mirror of
https://github.com/Azure/MachineLearningNotebooks.git
synced 2025-12-20 17:45:10 -05:00
Compare commits
31 Commits
azureml-sd
...
sdk-codete
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6a145086d8 | ||
|
|
cb695c91ce | ||
|
|
de505d67bd | ||
|
|
f19cfa4630 | ||
|
|
7eed2e4b56 | ||
|
|
57b0f701f8 | ||
|
|
7db93bcb1d | ||
|
|
fcbe925640 | ||
|
|
bedfbd649e | ||
|
|
fb760f648d | ||
|
|
a9a0713d2f | ||
|
|
c9d018b52c | ||
|
|
53dbd0afcf | ||
|
|
e3a64b1f16 | ||
|
|
732eecfc7c | ||
|
|
6995c086ff | ||
|
|
80bba4c7ae | ||
|
|
3c581b533f | ||
|
|
cc688caa4e | ||
|
|
da225e116e | ||
|
|
73c5d02880 | ||
|
|
e472b54f1b | ||
|
|
716c6d8bb1 | ||
|
|
23189c6f40 | ||
|
|
361b57ed29 | ||
|
|
3f531fd211 | ||
|
|
111f5e8d73 | ||
|
|
96c59d5c2b | ||
|
|
ce3214b7c6 | ||
|
|
53199d17de | ||
|
|
54c883412c |
7
.amlignore
Normal file
7
.amlignore
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
.ipynb_checkpoints
|
||||||
|
azureml-logs
|
||||||
|
.azureml
|
||||||
|
.git
|
||||||
|
outputs
|
||||||
|
azureml-setup
|
||||||
|
docs
|
||||||
3
.vscode/settings.json
vendored
Normal file
3
.vscode/settings.json
vendored
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
{
|
||||||
|
"python.pythonPath": "C:\\Users\\sgilley\\.azureml\\envs\\jan3\\python.exe"
|
||||||
|
}
|
||||||
@@ -95,19 +95,6 @@
|
|||||||
"If this cell succeeds, you're done configuring this library! Otherwise continue to follow the instructions in the rest of the notebook."
|
"If this cell succeeds, you're done configuring this library! Otherwise continue to follow the instructions in the rest of the notebook."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import os\n",
|
|
||||||
"\n",
|
|
||||||
"subscription_id = os.environ.get(\"SUBSCRIPTION_ID\", \"<my-subscription-id>\")\n",
|
|
||||||
"resource_group = os.environ.get(\"RESOURCE_GROUP\", \"<my-resource-group>\")\n",
|
|
||||||
"workspace_name = os.environ.get(\"WORKSPACE_NAME\", \"<my-workspace-name>\")"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": null,
|
"execution_count": null,
|
||||||
@@ -116,6 +103,10 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core import Workspace\n",
|
"from azureml.core import Workspace\n",
|
||||||
"\n",
|
"\n",
|
||||||
|
"subscription_id ='<subscription-id>'\n",
|
||||||
|
"resource_group ='<resource-group>'\n",
|
||||||
|
"workspace_name = '<workspace-name>'\n",
|
||||||
|
"\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name)\n",
|
" ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name)\n",
|
||||||
" ws.write_config()\n",
|
" ws.write_config()\n",
|
||||||
@@ -140,7 +131,7 @@
|
|||||||
"* Your subscription id\n",
|
"* Your subscription id\n",
|
||||||
"* The resource group name\n",
|
"* The resource group name\n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Note**: As with other Azure services, there are limits on certain resources (for eg. AmlCompute quota) associated with the Azure Machine Learning service. Please read [this article](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-manage-quotas) on the default limits and how to request more quota."
|
"**Note**: As with other Azure services, there are limits on certain resources (for eg. BatchAI cluster size) associated with the Azure Machine Learning service. Please read [this article](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-manage-quotas) on the default limits and how to request more quota."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -151,6 +142,15 @@
|
|||||||
"Specify a region where your workspace will be located from the list of [Azure Machine Learning regions](https://linktoregions)"
|
"Specify a region where your workspace will be located from the list of [Azure Machine Learning regions](https://linktoregions)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"workspace_region = \"eastus2\""
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": null,
|
"execution_count": null,
|
||||||
@@ -159,11 +159,10 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"\n",
|
"\n",
|
||||||
"subscription_id = os.environ.get(\"SUBSCRIPTION_ID\", \"<my-subscription-id>\")\n",
|
"subscription_id = os.environ.get(\"SUBSCRIPTION_ID\", subscription_id)\n",
|
||||||
"resource_group = os.environ.get(\"RESOURCE_GROUP\", \"my-aml-resource-group\")\n",
|
"resource_group = os.environ.get(\"RESOURCE_GROUP\", resource_group)\n",
|
||||||
"workspace_name = os.environ.get(\"WORKSPACE_NAME\", \"my-first-workspace\")\n",
|
"workspace_name = os.environ.get(\"WORKSPACE_NAME\", workspace_name)\n",
|
||||||
"\n",
|
"workspace_region = os.environ.get(\"WORKSPACE_REGION\", workspace_region)"
|
||||||
"workspace_region = os.environ.get(\"WORKSPACE_REGION\", \"eastus2\")"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -204,92 +203,16 @@
|
|||||||
"ws.write_config()"
|
"ws.write_config()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create compute resources for your training experiments\n",
|
|
||||||
"\n",
|
|
||||||
"Many of the subsequent examples use Azure Machine Learning managed compute (AmlCompute) to train models at scale. To create a **CPU** cluster now, run the cell below. The autoscale settings mean that the cluster will scale down to 0 nodes when inactive and up to 4 nodes when busy."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
|
||||||
"\n",
|
|
||||||
"# Choose a name for your CPU cluster\n",
|
|
||||||
"cpu_cluster_name = \"cpucluster\"\n",
|
|
||||||
"\n",
|
|
||||||
"# Verify that cluster does not exist already\n",
|
|
||||||
"try:\n",
|
|
||||||
" cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)\n",
|
|
||||||
" print('Found existing cluster, use it.')\n",
|
|
||||||
"except ComputeTargetException:\n",
|
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',\n",
|
|
||||||
" max_nodes=4)\n",
|
|
||||||
" cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)\n",
|
|
||||||
"\n",
|
|
||||||
"cpu_cluster.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"To create a **GPU** cluster, run the cell below. Note that your subscription must have sufficient quota for GPU VMs or the command will fail. To increase quota, see [these instructions](https://docs.microsoft.com/en-us/azure/azure-supportability/resource-manager-core-quotas-request). "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
|
||||||
"\n",
|
|
||||||
"# Choose a name for your GPU cluster\n",
|
|
||||||
"gpu_cluster_name = \"gpucluster\"\n",
|
|
||||||
"\n",
|
|
||||||
"# Check if cluster exists already\n",
|
|
||||||
"try:\n",
|
|
||||||
" gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)\n",
|
|
||||||
" print('Found existing cluster, use it.')\n",
|
|
||||||
"except ComputeTargetException:\n",
|
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',\n",
|
|
||||||
" max_nodes=4)\n",
|
|
||||||
" gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)\n",
|
|
||||||
"\n",
|
|
||||||
"gpu_cluster.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"## Success!\n",
|
"## Success!\n",
|
||||||
"Great, you are ready to move on to the rest of the sample notebooks. A good place to start is the [01.train-model tutorial](./tutorials/01.train-model.ipynb) to learn how to train and then deploy an image classification model."
|
"Great, you are ready to move on to the rest of the sample notebooks."
|
||||||
]
|
]
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": []
|
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "roastala"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
"kernelspec": {
|
||||||
"display_name": "Python 3.6",
|
"display_name": "Python 3.6",
|
||||||
"language": "python",
|
"language": "python",
|
||||||
@@ -305,7 +228,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.6.6"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
@@ -27,7 +27,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"## Prerequisites\n",
|
"## Prerequisites\n",
|
||||||
"1. Make sure you go through the [00. Installation and Configuration](../../00.configuration.ipynb) Notebook first if you haven't. \n",
|
"1. Make sure you go through the [00. Installation and Configuration](00.configuration.ipynb) Notebook first if you haven't. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"2. Install following pre-requisite libraries to your conda environment and restart notebook.\n",
|
"2. Install following pre-requisite libraries to your conda environment and restart notebook.\n",
|
||||||
"```shell\n",
|
"```shell\n",
|
||||||
@@ -525,7 +525,8 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
"\n",
|
"\n",
|
||||||
"myenv = CondaDependencies.create(conda_packages=[\"scikit-learn\"])\n",
|
"myenv = CondaDependencies()\n",
|
||||||
|
"myenv.add_conda_package(\"scikit-learn\")\n",
|
||||||
"print(myenv.serialize_to_string())\n",
|
"print(myenv.serialize_to_string())\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
@@ -679,7 +680,7 @@
|
|||||||
"# score the entire test set.\n",
|
"# score the entire test set.\n",
|
||||||
"test_samples = json.dumps({'data': X_test.tolist()})\n",
|
"test_samples = json.dumps({'data': X_test.tolist()})\n",
|
||||||
"\n",
|
"\n",
|
||||||
"result = service.run(input_data = test_samples)\n",
|
"result = json.loads(service.run(input_data = test_samples))['result']\n",
|
||||||
"residual = result - y_test"
|
"residual = result - y_test"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -777,6 +778,13 @@
|
|||||||
"%%time\n",
|
"%%time\n",
|
||||||
"service.delete()"
|
"service.delete()"
|
||||||
]
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
@@ -800,7 +808,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.6"
|
"version": "3.6.4"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
@@ -21,9 +21,7 @@ def run(raw_data):
|
|||||||
data = json.loads(raw_data)['data']
|
data = json.loads(raw_data)['data']
|
||||||
data = np.array(data)
|
data = np.array(data)
|
||||||
result = model.predict(data)
|
result = model.predict(data)
|
||||||
|
return json.dumps({"result": result.tolist()})
|
||||||
# you can return any data type as long as it is JSON-serializable
|
|
||||||
return result.tolist()
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
result = str(e)
|
result = str(e)
|
||||||
return result
|
return json.dumps({"error": result})
|
||||||
|
|||||||
@@ -291,7 +291,11 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
|
"from azureml.core.runconfig import RunConfiguration\n",
|
||||||
|
"from azureml.core.conda_dependencies import CondaDependencies\n",
|
||||||
|
"\n",
|
||||||
"run_config_docker = RunConfiguration()\n",
|
"run_config_docker = RunConfiguration()\n",
|
||||||
|
"\n",
|
||||||
"run_config_docker.environment.python.user_managed_dependencies = False\n",
|
"run_config_docker.environment.python.user_managed_dependencies = False\n",
|
||||||
"run_config_docker.auto_prepare_environment = True\n",
|
"run_config_docker.auto_prepare_environment = True\n",
|
||||||
"run_config_docker.environment.docker.enabled = True\n",
|
"run_config_docker.environment.docker.enabled = True\n",
|
||||||
@@ -299,9 +303,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"# Specify conda dependencies with scikit-learn\n",
|
"# Specify conda dependencies with scikit-learn\n",
|
||||||
"cd = CondaDependencies.create(conda_packages=['scikit-learn'])\n",
|
"cd = CondaDependencies.create(conda_packages=['scikit-learn'])\n",
|
||||||
"run_config_docker.environment.python.conda_dependencies = cd\n",
|
"run_config_docker.environment.python.conda_dependencies = cd"
|
||||||
"\n",
|
|
||||||
"src = ScriptRunConfig(source_directory=\"./\", script='train.py', run_config=run_config_docker)"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -320,17 +322,8 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import subprocess\n",
|
"src = ScriptRunConfig(source_directory=\"./\", script='train.py', run_config=run_config_docker)\n",
|
||||||
"\n",
|
"run = exp.submit(src)"
|
||||||
"# Check if Docker is installed and Linux containers are enables\n",
|
|
||||||
"if subprocess.run(\"docker -v\", shell=True) == 0:\n",
|
|
||||||
" out = subprocess.check_output(\"docker system info\", shell=True, encoding=\"ascii\").split(\"\\n\")\n",
|
|
||||||
" if not \"OSType: linux\" in out:\n",
|
|
||||||
" print(\"Switch Docker engine to use Linux containers.\")\n",
|
|
||||||
" else:\n",
|
|
||||||
" run = exp.submit(src)\n",
|
|
||||||
"else:\n",
|
|
||||||
" print(\"Docker engine not installed.\")"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -190,16 +190,6 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"## Create Linux DSVM as a compute target\n",
|
"## Create Linux DSVM as a compute target\n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Note**: To streamline the compute that Azure Machine Learning creates, we are making updates to support creating only single to multi-node AmlCompute. The DSVMCompute class will be deprecated in a later release, but the DSVM can be created using the below single line command and then attached(like any VM) using the sample code below. Also note, that we only support Linux VMs and the commands below will spin a Linux VM only.\n",
|
|
||||||
"\n",
|
|
||||||
"```shell\n",
|
|
||||||
"# create a DSVM in your resource group\n",
|
|
||||||
"# note you need to be at least a contributor to the resource group in order to execute this command successfully.\n",
|
|
||||||
"(myenv) $ az vm create --resource-group <resource_group_name> --name <some_vm_name> --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username <username> --admin-password <password> --generate-ssh-keys --authentication-type password\n",
|
|
||||||
"```\n",
|
|
||||||
"\n",
|
|
||||||
"**Note**: You can also use [this url](https://portal.azure.com/#create/microsoft-dsvm.linux-data-science-vm-ubuntulinuxdsvmubuntu) to create the VM using the Azure Portal\n",
|
|
||||||
"\n",
|
|
||||||
"**Note**: If creation fails with a message about Marketplace purchase eligibilty, go to portal.azure.com, start creating DSVM there, and select \"Want to create programmatically\" to enable programmatic creation. Once you've enabled it, you can exit without actually creating VM.\n",
|
"**Note**: If creation fails with a message about Marketplace purchase eligibilty, go to portal.azure.com, start creating DSVM there, and select \"Want to create programmatically\" to enable programmatic creation. Once you've enabled it, you can exit without actually creating VM.\n",
|
||||||
" \n",
|
" \n",
|
||||||
"**Note**: By default SSH runs on port 22 and you don't need to specify it. But if for security reasons you switch to a different port (such as 5022), you can specify the port number in the provisioning configuration object."
|
"**Note**: By default SSH runs on port 22 and you don't need to specify it. But if for security reasons you switch to a different port (such as 5022), you can specify the port number in the provisioning configuration object."
|
||||||
@@ -623,7 +613,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.6.6"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
@@ -1,328 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# 06. Logging APIs\n",
|
|
||||||
"This notebook showcase various ways to use the Azure Machine Learning service run logging APIs, and view the results in the Azure portal."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Prerequisites\n",
|
|
||||||
"Make sure you go through the [00. Installation and Configuration](../../00.configuration.ipynb) Notebook first if you haven't. Also make sure you have tqdm and matplotlib installed in the current kernel.\n",
|
|
||||||
"\n",
|
|
||||||
"```\n",
|
|
||||||
"(myenv) $ conda install -y tqdm matplotlib\n",
|
|
||||||
"```"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Validate Azure ML SDK installation and get version number for debugging purposes"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {
|
|
||||||
"tags": [
|
|
||||||
"install"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core import Experiment, Run, Workspace\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"\n",
|
|
||||||
"# Check core SDK version number\n",
|
|
||||||
"print(\"SDK version:\", azureml.core.VERSION)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Initialize Workspace\n",
|
|
||||||
"\n",
|
|
||||||
"Initialize a workspace object from persisted configuration."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {
|
|
||||||
"tags": [
|
|
||||||
"create workspace"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"print('Workspace name: ' + ws.name, \n",
|
|
||||||
" 'Azure region: ' + ws.location, \n",
|
|
||||||
" 'Subscription id: ' + ws.subscription_id, \n",
|
|
||||||
" 'Resource group: ' + ws.resource_group, sep='\\n')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Set experiment\n",
|
|
||||||
"Create a new experiment (or get the one with such name)."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"exp = Experiment(workspace=ws, name='logging-api-test')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Log metrics\n",
|
|
||||||
"We will start a run, and use the various logging APIs to record different types of metrics during the run."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from tqdm import tqdm\n",
|
|
||||||
"\n",
|
|
||||||
"# start logging for the run\n",
|
|
||||||
"run = exp.start_logging()\n",
|
|
||||||
"\n",
|
|
||||||
"# log a string value\n",
|
|
||||||
"run.log(name='Name', value='Logging API run')\n",
|
|
||||||
"\n",
|
|
||||||
"# log a numerical value\n",
|
|
||||||
"run.log(name='Magic Number', value=42)\n",
|
|
||||||
"\n",
|
|
||||||
"# Log a list of values. Note this will generate a single-variable line chart.\n",
|
|
||||||
"run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89])\n",
|
|
||||||
"\n",
|
|
||||||
"# create a dictionary to hold a table of values\n",
|
|
||||||
"sines = {}\n",
|
|
||||||
"sines['angle'] = []\n",
|
|
||||||
"sines['sine'] = []\n",
|
|
||||||
"\n",
|
|
||||||
"for i in tqdm(range(-10, 10)):\n",
|
|
||||||
" # log a metric value repeatedly, this will generate a single-variable line chart.\n",
|
|
||||||
" run.log(name='Sigmoid', value=1 / (1 + np.exp(-i)))\n",
|
|
||||||
" angle = i / 2.0\n",
|
|
||||||
" \n",
|
|
||||||
" # log a 2 (or more) values as a metric repeatedly. This will generate a 2-variable line chart if you have 2 numerical columns.\n",
|
|
||||||
" run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle))\n",
|
|
||||||
" \n",
|
|
||||||
" sines['angle'].append(angle)\n",
|
|
||||||
" sines['sine'].append(np.sin(angle))\n",
|
|
||||||
"\n",
|
|
||||||
"# log a dictionary as a table, this will generate a 2-variable chart if you have 2 numerical columns\n",
|
|
||||||
"run.log_table(name='Sine Wave', value=sines)\n",
|
|
||||||
"\n",
|
|
||||||
"run.complete()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Even after the run is marked completed, you can still log things."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Log an image\n",
|
|
||||||
"This is how to log a _matplotlib_ pyplot object."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%matplotlib inline\n",
|
|
||||||
"import matplotlib.pyplot as plt\n",
|
|
||||||
"angle = np.linspace(-3, 3, 50)\n",
|
|
||||||
"plt.plot(angle, np.tanh(angle), label='tanh')\n",
|
|
||||||
"plt.legend(fontsize=12)\n",
|
|
||||||
"plt.title('Hyperbolic Tangent', fontsize=16)\n",
|
|
||||||
"plt.grid(True)\n",
|
|
||||||
"\n",
|
|
||||||
"run.log_image(name='Hyperbolic Tangent', plot=plt)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Upload a file"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"You can also upload an abitrary file. First, let's create a dummy file locally."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%%writefile myfile.txt\n",
|
|
||||||
"\n",
|
|
||||||
"This is a dummy file."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Now let's upload this file into the run record as a run artifact, and display the properties after the upload."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"props = run.upload_file(name='myfile_in_the_cloud.txt', path_or_stream='./myfile.txt')\n",
|
|
||||||
"props.serialize()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Examine the run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Now let's take a look at the run detail page in Azure portal. Make sure you checkout the various charts and plots generated/uploaded."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"You can get all the metrics in that run back."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run.get_metrics()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"You can also see the files uploaded for this run."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run.get_file_names()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"You can also download all the files locally."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import os\n",
|
|
||||||
"os.makedirs('files', exist_ok=True)\n",
|
|
||||||
"\n",
|
|
||||||
"for f in run.get_file_names():\n",
|
|
||||||
" dest = os.path.join('files', f.split('/')[-1])\n",
|
|
||||||
" print('Downloading file {} to {}...'.format(f, dest))\n",
|
|
||||||
" run.download_file(f, dest) "
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "haining"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -192,11 +192,9 @@
|
|||||||
" data = json.loads(raw_data)['data']\n",
|
" data = json.loads(raw_data)['data']\n",
|
||||||
" data = numpy.array(data)\n",
|
" data = numpy.array(data)\n",
|
||||||
" result = model.predict(data)\n",
|
" result = model.predict(data)\n",
|
||||||
" # you can return any datatype as long as it is JSON-serializable\n",
|
|
||||||
" return result.tolist()\n",
|
|
||||||
" except Exception as e:\n",
|
" except Exception as e:\n",
|
||||||
" error = str(e)\n",
|
" result = str(e)\n",
|
||||||
" return error"
|
" return json.dumps({\"result\": result.tolist()})"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -389,6 +387,13 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"aci_service.delete()"
|
"aci_service.delete()"
|
||||||
]
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
@@ -412,7 +417,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.6"
|
"version": "3.6.5"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
@@ -122,11 +122,9 @@
|
|||||||
" data = json.loads(raw_data)['data']\n",
|
" data = json.loads(raw_data)['data']\n",
|
||||||
" data = numpy.array(data)\n",
|
" data = numpy.array(data)\n",
|
||||||
" result = model.predict(data)\n",
|
" result = model.predict(data)\n",
|
||||||
" # you can return any data type as long as it is JSON-serializable\n",
|
|
||||||
" return result.tolist()\n",
|
|
||||||
" except Exception as e:\n",
|
" except Exception as e:\n",
|
||||||
" error = str(e)\n",
|
" result = str(e)\n",
|
||||||
" return error"
|
" return json.dumps({\"result\": result.tolist()})"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -334,7 +332,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.6"
|
"version": "3.6.5"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
@@ -156,12 +156,11 @@
|
|||||||
" inputs_dc.collect(data) #this call is saving our input data into our blob\n",
|
" inputs_dc.collect(data) #this call is saving our input data into our blob\n",
|
||||||
" prediction_dc.collect(result)#this call is saving our prediction data into our blob\n",
|
" prediction_dc.collect(result)#this call is saving our prediction data into our blob\n",
|
||||||
" print (\"saving prediction data\" + time.strftime(\"%H:%M:%S\"))\n",
|
" print (\"saving prediction data\" + time.strftime(\"%H:%M:%S\"))\n",
|
||||||
" # you can return any data type as long as it is JSON-serializable\n",
|
" return json.dumps({\"result\": result.tolist()})\n",
|
||||||
" return result.tolist()\n",
|
|
||||||
" except Exception as e:\n",
|
" except Exception as e:\n",
|
||||||
" error = str(e)\n",
|
" result = str(e)\n",
|
||||||
" print (error + time.strftime(\"%H:%M:%S\"))\n",
|
" print (result + time.strftime(\"%H:%M:%S\"))\n",
|
||||||
" return error"
|
" return json.dumps({\"error\": result})"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -161,12 +161,13 @@
|
|||||||
" \n",
|
" \n",
|
||||||
" #Print statement for appinsights custom traces:\n",
|
" #Print statement for appinsights custom traces:\n",
|
||||||
" print (\"saving prediction data\" + time.strftime(\"%H:%M:%S\"))\n",
|
" print (\"saving prediction data\" + time.strftime(\"%H:%M:%S\"))\n",
|
||||||
" # you can return any data type as long as it is JSON-serializable\n",
|
" \n",
|
||||||
" return result.tolist()\n",
|
" return json.dumps({\"result\": result.tolist()})\n",
|
||||||
|
" \n",
|
||||||
" except Exception as e:\n",
|
" except Exception as e:\n",
|
||||||
" error = str(e)\n",
|
" result = str(e)\n",
|
||||||
" print (error + time.strftime(\"%H:%M:%S\"))\n",
|
" print (result + time.strftime(\"%H:%M:%S\"))\n",
|
||||||
" return error"
|
" return json.dumps({\"error\": result})"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
22
README.md
22
README.md
@@ -1,5 +1,10 @@
|
|||||||
For full documentation for Azure Machine Learning service, visit **https://aka.ms/aml-docs**.
|
Get the full documentation for Azure Machine Learning service at:
|
||||||
# Sample Notebooks for Azure Machine Learning service
|
|
||||||
|
https://docs.microsoft.com/azure/machine-learning/service/
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
# Sample notebooks for Azure Machine Learning service
|
||||||
|
|
||||||
To run the notebooks in this repository use one of these methods:
|
To run the notebooks in this repository use one of these methods:
|
||||||
|
|
||||||
@@ -17,24 +22,13 @@ To run the notebooks in this repository use one of these methods:
|
|||||||
|
|
||||||
## **Use your own notebook server**
|
## **Use your own notebook server**
|
||||||
|
|
||||||
Video walkthrough:
|
|
||||||
|
|
||||||
[](https://youtu.be/VIsXeTuW3FU)
|
|
||||||
|
|
||||||
1. Setup a Jupyter Notebook server and [install the Azure Machine Learning SDK](https://docs.microsoft.com/en-us/azure/machine-learning/service/quickstart-create-workspace-with-python).
|
1. Setup a Jupyter Notebook server and [install the Azure Machine Learning SDK](https://docs.microsoft.com/en-us/azure/machine-learning/service/quickstart-create-workspace-with-python).
|
||||||
1. Clone [this repository](https://aka.ms/aml-notebooks).
|
1. Clone [this repository](https://aka.ms/aml-notebooks).
|
||||||
1. You may need to install other packages for specific notebook.
|
1. You may need to install other packages for specific notebooks
|
||||||
- For example, to run the Azure Machine Learning Data Prep notebooks, install the extra dataprep SDK:
|
|
||||||
```
|
|
||||||
pip install --upgrade azureml-dataprep
|
|
||||||
```
|
|
||||||
|
|
||||||
1. Start your notebook server.
|
1. Start your notebook server.
|
||||||
1. Follow the instructions in the [00.configuration](00.configuration.ipynb) notebook to create and connect to a workspace.
|
1. Follow the instructions in the [00.configuration](00.configuration.ipynb) notebook to create and connect to a workspace.
|
||||||
1. Open one of the sample notebooks.
|
1. Open one of the sample notebooks.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
> Note: **Looking for automated machine learning samples?**
|
> Note: **Looking for automated machine learning samples?**
|
||||||
> For your convenience, you can use an installation script instead of the steps below for the automated ML notebooks. Go to the [automl folder README](automl/README.md) and follow the instructions. The script installs all packages needed for notebooks in that folder.
|
> For your convenience, you can use an installation script instead of the steps below for the automated ML notebooks. Go to the [automl folder README](automl/README.md) and follow the instructions. The script installs all packages needed for notebooks in that folder.
|
||||||
|
|
||||||
|
|||||||
15
aml_config/conda_dependencies.yml
Normal file
15
aml_config/conda_dependencies.yml
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
# Conda environment specification. The dependencies defined in this file will
|
||||||
|
|
||||||
|
# be automatically provisioned for runs with userManagedDependencies=False.
|
||||||
|
|
||||||
|
|
||||||
|
# Details about the Conda environment file format:
|
||||||
|
|
||||||
|
# https://conda.io/docs/user-guide/tasks/manage-environments.html#create-env-file-manually
|
||||||
|
|
||||||
|
|
||||||
|
name: project_environment
|
||||||
|
dependencies:
|
||||||
|
# The python interpreter version.
|
||||||
|
|
||||||
|
# Currently Azure ML only supports 3.5.2 and later.
|
||||||
115
aml_config/docker.runconfig
Normal file
115
aml_config/docker.runconfig
Normal file
@@ -0,0 +1,115 @@
|
|||||||
|
# The script to run.
|
||||||
|
script: train.py
|
||||||
|
# The arguments to the script file.
|
||||||
|
arguments: []
|
||||||
|
# The name of the compute target to use for this run.
|
||||||
|
target: local
|
||||||
|
# Framework to execute inside. Allowed values are "Python" , "PySpark", "CNTK", "TensorFlow", and "PyTorch".
|
||||||
|
framework: PySpark
|
||||||
|
# Communicator for the given framework. Allowed values are "None" , "ParameterServer", "OpenMpi", and "IntelMpi".
|
||||||
|
communicator: None
|
||||||
|
# Automatically prepare the run environment as part of the run itself.
|
||||||
|
autoPrepareEnvironment: true
|
||||||
|
# Maximum allowed duration for the run.
|
||||||
|
maxRunDurationSeconds:
|
||||||
|
# Number of nodes to use for running job.
|
||||||
|
nodeCount: 1
|
||||||
|
# Environment details.
|
||||||
|
environment:
|
||||||
|
# Environment variables set for the run.
|
||||||
|
environmentVariables:
|
||||||
|
EXAMPLE_ENV_VAR: EXAMPLE_VALUE
|
||||||
|
# Python details
|
||||||
|
python:
|
||||||
|
# user_managed_dependencies=True indicates that the environmentwill be user managed. False indicates that AzureML willmanage the user environment.
|
||||||
|
userManagedDependencies: false
|
||||||
|
# The python interpreter path
|
||||||
|
interpreterPath: python
|
||||||
|
# Path to the conda dependencies file to use for this run. If a project
|
||||||
|
# contains multiple programs with different sets of dependencies, it may be
|
||||||
|
# convenient to manage those environments with separate files.
|
||||||
|
condaDependenciesFile: aml_config/conda_dependencies.yml
|
||||||
|
# Docker details
|
||||||
|
docker:
|
||||||
|
# Set True to perform this run inside a Docker container.
|
||||||
|
enabled: true
|
||||||
|
# Base image used for Docker-based runs.
|
||||||
|
baseImage: mcr.microsoft.com/azureml/base:0.2.0
|
||||||
|
# Set False if necessary to work around shared volume bugs.
|
||||||
|
sharedVolumes: true
|
||||||
|
# Run with NVidia Docker extension to support GPUs.
|
||||||
|
gpuSupport: false
|
||||||
|
# Extra arguments to the Docker run command.
|
||||||
|
arguments: []
|
||||||
|
# Image registry that contains the base image.
|
||||||
|
baseImageRegistry:
|
||||||
|
# DNS name or IP address of azure container registry(ACR)
|
||||||
|
address:
|
||||||
|
# The username for ACR
|
||||||
|
username:
|
||||||
|
# The password for ACR
|
||||||
|
password:
|
||||||
|
# Spark details
|
||||||
|
spark:
|
||||||
|
# List of spark repositories.
|
||||||
|
repositories:
|
||||||
|
- https://mmlspark.azureedge.net/maven
|
||||||
|
packages:
|
||||||
|
- group: com.microsoft.ml.spark
|
||||||
|
artifact: mmlspark_2.11
|
||||||
|
version: '0.12'
|
||||||
|
precachePackages: true
|
||||||
|
# Databricks details
|
||||||
|
databricks:
|
||||||
|
# List of maven libraries.
|
||||||
|
mavenLibraries: []
|
||||||
|
# List of PyPi libraries
|
||||||
|
pypiLibraries: []
|
||||||
|
# List of RCran libraries
|
||||||
|
rcranLibraries: []
|
||||||
|
# List of JAR libraries
|
||||||
|
jarLibraries: []
|
||||||
|
# List of Egg libraries
|
||||||
|
eggLibraries: []
|
||||||
|
# History details.
|
||||||
|
history:
|
||||||
|
# Enable history tracking -- this allows status, logs, metrics, and outputs
|
||||||
|
# to be collected for a run.
|
||||||
|
outputCollection: true
|
||||||
|
# whether to take snapshots for history.
|
||||||
|
snapshotProject: true
|
||||||
|
# Spark configuration details.
|
||||||
|
spark:
|
||||||
|
configuration:
|
||||||
|
spark.app.name: Azure ML Experiment
|
||||||
|
spark.yarn.maxAppAttempts: 1
|
||||||
|
# HDI details.
|
||||||
|
hdi:
|
||||||
|
# Yarn deploy mode. Options are cluster and client.
|
||||||
|
yarnDeployMode: cluster
|
||||||
|
# Tensorflow details.
|
||||||
|
tensorflow:
|
||||||
|
# The number of worker tasks.
|
||||||
|
workerCount: 1
|
||||||
|
# The number of parameter server tasks.
|
||||||
|
parameterServerCount: 1
|
||||||
|
# Mpi details.
|
||||||
|
mpi:
|
||||||
|
# When using MPI, number of processes per node.
|
||||||
|
processCountPerNode: 1
|
||||||
|
# data reference configuration details
|
||||||
|
dataReferences: {}
|
||||||
|
# Project share datastore reference.
|
||||||
|
sourceDirectoryDataStore:
|
||||||
|
# AmlCompute details.
|
||||||
|
amlcompute:
|
||||||
|
# VM size of the Cluster to be created.Allowed values are Azure vm sizes.The list of vm sizes is available in 'https://docs.microsoft.com/en-us/azure/cloud-services/cloud-services-sizes-specs
|
||||||
|
vmSize:
|
||||||
|
# VM priority of the Cluster to be created.Allowed values are "dedicated" , "lowpriority".
|
||||||
|
vmPriority:
|
||||||
|
# A bool that indicates if the cluster has to be retained after job completion.
|
||||||
|
retainCluster: false
|
||||||
|
# Name of the cluster to be created. If not specified, runId will be used as cluster name.
|
||||||
|
name:
|
||||||
|
# Maximum number of nodes in the AmlCompute cluster to be created. Minimum number of nodes will always be set to 0.
|
||||||
|
clusterMaxNodeCount: 1
|
||||||
115
aml_config/local.runconfig
Normal file
115
aml_config/local.runconfig
Normal file
@@ -0,0 +1,115 @@
|
|||||||
|
# The script to run.
|
||||||
|
script: train.py
|
||||||
|
# The arguments to the script file.
|
||||||
|
arguments: []
|
||||||
|
# The name of the compute target to use for this run.
|
||||||
|
target: local
|
||||||
|
# Framework to execute inside. Allowed values are "Python" , "PySpark", "CNTK", "TensorFlow", and "PyTorch".
|
||||||
|
framework: Python
|
||||||
|
# Communicator for the given framework. Allowed values are "None" , "ParameterServer", "OpenMpi", and "IntelMpi".
|
||||||
|
communicator: None
|
||||||
|
# Automatically prepare the run environment as part of the run itself.
|
||||||
|
autoPrepareEnvironment: true
|
||||||
|
# Maximum allowed duration for the run.
|
||||||
|
maxRunDurationSeconds:
|
||||||
|
# Number of nodes to use for running job.
|
||||||
|
nodeCount: 1
|
||||||
|
# Environment details.
|
||||||
|
environment:
|
||||||
|
# Environment variables set for the run.
|
||||||
|
environmentVariables:
|
||||||
|
EXAMPLE_ENV_VAR: EXAMPLE_VALUE
|
||||||
|
# Python details
|
||||||
|
python:
|
||||||
|
# user_managed_dependencies=True indicates that the environmentwill be user managed. False indicates that AzureML willmanage the user environment.
|
||||||
|
userManagedDependencies: false
|
||||||
|
# The python interpreter path
|
||||||
|
interpreterPath: python
|
||||||
|
# Path to the conda dependencies file to use for this run. If a project
|
||||||
|
# contains multiple programs with different sets of dependencies, it may be
|
||||||
|
# convenient to manage those environments with separate files.
|
||||||
|
condaDependenciesFile: aml_config/conda_dependencies.yml
|
||||||
|
# Docker details
|
||||||
|
docker:
|
||||||
|
# Set True to perform this run inside a Docker container.
|
||||||
|
enabled: false
|
||||||
|
# Base image used for Docker-based runs.
|
||||||
|
baseImage: mcr.microsoft.com/azureml/base:0.2.0
|
||||||
|
# Set False if necessary to work around shared volume bugs.
|
||||||
|
sharedVolumes: true
|
||||||
|
# Run with NVidia Docker extension to support GPUs.
|
||||||
|
gpuSupport: false
|
||||||
|
# Extra arguments to the Docker run command.
|
||||||
|
arguments: []
|
||||||
|
# Image registry that contains the base image.
|
||||||
|
baseImageRegistry:
|
||||||
|
# DNS name or IP address of azure container registry(ACR)
|
||||||
|
address:
|
||||||
|
# The username for ACR
|
||||||
|
username:
|
||||||
|
# The password for ACR
|
||||||
|
password:
|
||||||
|
# Spark details
|
||||||
|
spark:
|
||||||
|
# List of spark repositories.
|
||||||
|
repositories:
|
||||||
|
- https://mmlspark.azureedge.net/maven
|
||||||
|
packages:
|
||||||
|
- group: com.microsoft.ml.spark
|
||||||
|
artifact: mmlspark_2.11
|
||||||
|
version: '0.12'
|
||||||
|
precachePackages: true
|
||||||
|
# Databricks details
|
||||||
|
databricks:
|
||||||
|
# List of maven libraries.
|
||||||
|
mavenLibraries: []
|
||||||
|
# List of PyPi libraries
|
||||||
|
pypiLibraries: []
|
||||||
|
# List of RCran libraries
|
||||||
|
rcranLibraries: []
|
||||||
|
# List of JAR libraries
|
||||||
|
jarLibraries: []
|
||||||
|
# List of Egg libraries
|
||||||
|
eggLibraries: []
|
||||||
|
# History details.
|
||||||
|
history:
|
||||||
|
# Enable history tracking -- this allows status, logs, metrics, and outputs
|
||||||
|
# to be collected for a run.
|
||||||
|
outputCollection: true
|
||||||
|
# whether to take snapshots for history.
|
||||||
|
snapshotProject: true
|
||||||
|
# Spark configuration details.
|
||||||
|
spark:
|
||||||
|
configuration:
|
||||||
|
spark.app.name: Azure ML Experiment
|
||||||
|
spark.yarn.maxAppAttempts: 1
|
||||||
|
# HDI details.
|
||||||
|
hdi:
|
||||||
|
# Yarn deploy mode. Options are cluster and client.
|
||||||
|
yarnDeployMode: cluster
|
||||||
|
# Tensorflow details.
|
||||||
|
tensorflow:
|
||||||
|
# The number of worker tasks.
|
||||||
|
workerCount: 1
|
||||||
|
# The number of parameter server tasks.
|
||||||
|
parameterServerCount: 1
|
||||||
|
# Mpi details.
|
||||||
|
mpi:
|
||||||
|
# When using MPI, number of processes per node.
|
||||||
|
processCountPerNode: 1
|
||||||
|
# data reference configuration details
|
||||||
|
dataReferences: {}
|
||||||
|
# Project share datastore reference.
|
||||||
|
sourceDirectoryDataStore:
|
||||||
|
# AmlCompute details.
|
||||||
|
amlcompute:
|
||||||
|
# VM size of the Cluster to be created.Allowed values are Azure vm sizes.The list of vm sizes is available in 'https://docs.microsoft.com/en-us/azure/cloud-services/cloud-services-sizes-specs
|
||||||
|
vmSize:
|
||||||
|
# VM priority of the Cluster to be created.Allowed values are "dedicated" , "lowpriority".
|
||||||
|
vmPriority:
|
||||||
|
# A bool that indicates if the cluster has to be retained after job completion.
|
||||||
|
retainCluster: false
|
||||||
|
# Name of the cluster to be created. If not specified, runId will be used as cluster name.
|
||||||
|
name:
|
||||||
|
# Maximum number of nodes in the AmlCompute cluster to be created. Minimum number of nodes will always be set to 0.
|
||||||
|
clusterMaxNodeCount: 1
|
||||||
1
aml_config/project.json
Normal file
1
aml_config/project.json
Normal file
@@ -0,0 +1 @@
|
|||||||
|
{"Id": "local-compute", "Scope": "/subscriptions/65a1016d-0f67-45d2-b838-b8f373d6d52e/resourceGroups/sheri/providers/Microsoft.MachineLearningServices/workspaces/sheritestqs3/projects/local-compute"}
|
||||||
@@ -140,7 +140,7 @@
|
|||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**task**|classification or regression|\n",
|
"|**task**|classification or regression|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
||||||
@@ -157,8 +157,8 @@
|
|||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
" debug_log = 'automl_errors.log',\n",
|
" debug_log = 'automl_errors.log',\n",
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
" iteration_timeout_minutes = 60,\n",
|
" max_time_sec = 3600,\n",
|
||||||
" iterations = 25,\n",
|
" iterations = 50,\n",
|
||||||
" n_cross_validations = 3,\n",
|
" n_cross_validations = 3,\n",
|
||||||
" verbosity = logging.INFO,\n",
|
" verbosity = logging.INFO,\n",
|
||||||
" X = X_train, \n",
|
" X = X_train, \n",
|
||||||
@@ -246,7 +246,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(local_run).show() "
|
"RunDetails(local_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -143,7 +143,7 @@
|
|||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**task**|classification or regression|\n",
|
"|**task**|classification or regression|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Regression supports the following primary metrics: <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Regression supports the following primary metrics: <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
||||||
@@ -158,7 +158,7 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"automl_config = AutoMLConfig(task = 'regression',\n",
|
"automl_config = AutoMLConfig(task = 'regression',\n",
|
||||||
" iteration_timeout_minutes = 10,\n",
|
" max_time_sec = 600,\n",
|
||||||
" iterations = 10,\n",
|
" iterations = 10,\n",
|
||||||
" primary_metric = 'spearman_correlation',\n",
|
" primary_metric = 'spearman_correlation',\n",
|
||||||
" n_cross_validations = 5,\n",
|
" n_cross_validations = 5,\n",
|
||||||
@@ -221,7 +221,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(local_run).show() "
|
"RunDetails(local_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -128,7 +128,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import DsvmCompute\n",
|
"from azureml.core.compute import DsvmCompute\n",
|
||||||
"\n",
|
"\n",
|
||||||
"dsvm_name = 'mydsvma'\n",
|
"dsvm_name = 'mydsvm'\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" dsvm_compute = DsvmCompute(ws, dsvm_name)\n",
|
" dsvm_compute = DsvmCompute(ws, dsvm_name)\n",
|
||||||
" print('Found an existing DSVM.')\n",
|
" print('Found an existing DSVM.')\n",
|
||||||
@@ -192,10 +192,10 @@
|
|||||||
"|Property|Description|\n",
|
"|Property|Description|\n",
|
||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**max_concurrent_iterations**|Maximum number of iterations to execute in parallel. This should be less than the number of cores on the DSVM.|"
|
"|**concurrent_iterations**|Maximum number of iterations to execute in parallel. This should be less than the number of cores on the DSVM.|"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -205,12 +205,12 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"automl_settings = {\n",
|
"automl_settings = {\n",
|
||||||
" \"iteration_timeout_minutes\": 10,\n",
|
" \"max_time_sec\": 600,\n",
|
||||||
" \"iterations\": 20,\n",
|
" \"iterations\": 20,\n",
|
||||||
" \"n_cross_validations\": 5,\n",
|
" \"n_cross_validations\": 5,\n",
|
||||||
" \"primary_metric\": 'AUC_weighted',\n",
|
" \"primary_metric\": 'AUC_weighted',\n",
|
||||||
" \"preprocess\": False,\n",
|
" \"preprocess\": False,\n",
|
||||||
" \"max_concurrent_iterations\": 2,\n",
|
" \"concurrent_iterations\": 2,\n",
|
||||||
" \"verbosity\": logging.INFO\n",
|
" \"verbosity\": logging.INFO\n",
|
||||||
"}\n",
|
"}\n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -286,7 +286,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(remote_run).show() "
|
"RunDetails(remote_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -130,25 +130,29 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import AmlCompute\n",
|
"from azureml.core.compute import BatchAiCompute\n",
|
||||||
"from azureml.core.compute import ComputeTarget\n",
|
"from azureml.core.compute import ComputeTarget\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Choose a name for your cluster.\n",
|
"# Choose a name for your cluster.\n",
|
||||||
"batchai_cluster_name = \"cpucluster\"\n",
|
"batchai_cluster_name = \"mybatchai\"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"found = False\n",
|
"found = False\n",
|
||||||
"# Check if this compute target already exists in the workspace.\n",
|
"# Check if this compute target already exists in the workspace.\n",
|
||||||
"cts = ws.compute_targets\n",
|
"for ct_name, ct in ws.compute_targets().items():\n",
|
||||||
"if batchai_cluster_name in cts and cts[batchai_cluster_name].type == 'BatchAI':\n",
|
" print(ct.name, ct.type)\n",
|
||||||
|
" if (ct.name == batchai_cluster_name and ct.type == 'BatchAI'):\n",
|
||||||
" found = True\n",
|
" found = True\n",
|
||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
" compute_target = cts[batchai_cluster_name]\n",
|
" compute_target = ct\n",
|
||||||
|
" break\n",
|
||||||
" \n",
|
" \n",
|
||||||
"if not found:\n",
|
"if not found:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" provisioning_config = AmlCompute.provisioning_configuration(vm_size = \"STANDARD_D2_V2\", # for GPU, use \"STANDARD_NC6\"\n",
|
" provisioning_config = BatchAiCompute.provisioning_configuration(vm_size = \"STANDARD_D2_V2\", # for GPU, use \"STANDARD_NC6\"\n",
|
||||||
" #vm_priority = 'lowpriority', # optional\n",
|
" #vm_priority = 'lowpriority', # optional\n",
|
||||||
" max_nodes = 6)\n",
|
" autoscale_enabled = True,\n",
|
||||||
|
" cluster_min_nodes = 1, \n",
|
||||||
|
" cluster_max_nodes = 4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # Create the cluster.\n",
|
" # Create the cluster.\n",
|
||||||
" compute_target = ComputeTarget.create(ws, batchai_cluster_name, provisioning_config)\n",
|
" compute_target = ComputeTarget.create(ws, batchai_cluster_name, provisioning_config)\n",
|
||||||
@@ -213,10 +217,10 @@
|
|||||||
"|Property|Description|\n",
|
"|Property|Description|\n",
|
||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**max_concurrent_iterations**|Maximum number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM.|"
|
"|**concurrent_iterations**|Maximum number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM.|"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -226,12 +230,12 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"automl_settings = {\n",
|
"automl_settings = {\n",
|
||||||
" \"iteration_timeout_minutes\": 2,\n",
|
" \"max_time_sec\": 120,\n",
|
||||||
" \"iterations\": 20,\n",
|
" \"iterations\": 20,\n",
|
||||||
" \"n_cross_validations\": 5,\n",
|
" \"n_cross_validations\": 5,\n",
|
||||||
" \"primary_metric\": 'AUC_weighted',\n",
|
" \"primary_metric\": 'AUC_weighted',\n",
|
||||||
" \"preprocess\": False,\n",
|
" \"preprocess\": False,\n",
|
||||||
" \"max_concurrent_iterations\": 5,\n",
|
" \"concurrent_iterations\": 5,\n",
|
||||||
" \"verbosity\": logging.INFO\n",
|
" \"verbosity\": logging.INFO\n",
|
||||||
"}\n",
|
"}\n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -308,7 +312,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(remote_run).show() "
|
"RunDetails(remote_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -137,22 +137,22 @@
|
|||||||
"# Add your VM information below\n",
|
"# Add your VM information below\n",
|
||||||
"# If a compute with the specified compute_name already exists, it will be used and the dsvm_ip_addr, dsvm_ssh_port, \n",
|
"# If a compute with the specified compute_name already exists, it will be used and the dsvm_ip_addr, dsvm_ssh_port, \n",
|
||||||
"# dsvm_username and dsvm_password will be ignored.\n",
|
"# dsvm_username and dsvm_password will be ignored.\n",
|
||||||
"compute_name = 'mydsvmb'\n",
|
"compute_name = 'mydsvm'\n",
|
||||||
"dsvm_ip_addr = '<<ip_addr>>'\n",
|
"dsvm_ip_addr = '<<ip_addr>>'\n",
|
||||||
"dsvm_ssh_port = 22\n",
|
"dsvm_ssh_port = 22\n",
|
||||||
"dsvm_username = '<<username>>'\n",
|
"dsvm_username = '<<username>>'\n",
|
||||||
"dsvm_password = '<<password>>'\n",
|
"dsvm_password = '<<password>>'\n",
|
||||||
"\n",
|
"\n",
|
||||||
"if compute_name in ws.compute_targets:\n",
|
"if compute_name in ws.compute_targets():\n",
|
||||||
" print('Using existing compute.')\n",
|
" print('Using existing compute.')\n",
|
||||||
" dsvm_compute = ws.compute_targets[compute_name]\n",
|
" dsvm_compute = ws.compute_targets()[compute_name]\n",
|
||||||
"else:\n",
|
"else:\n",
|
||||||
" RemoteCompute.attach(workspace=ws, name=compute_name, address=dsvm_ip_addr, username=dsvm_username, password=dsvm_password, ssh_port=dsvm_ssh_port)\n",
|
" RemoteCompute.attach(workspace=ws, name=compute_name, address=dsvm_ip_addr, username=dsvm_username, password=dsvm_password, ssh_port=dsvm_ssh_port)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" while ws.compute_targets[compute_name].provisioning_state == 'Creating':\n",
|
" while ws.compute_targets()[compute_name].provisioning_state == 'Creating':\n",
|
||||||
" time.sleep(1)\n",
|
" time.sleep(1)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" dsvm_compute = ws.compute_targets[compute_name]\n",
|
" dsvm_compute = ws.compute_targets()[compute_name]\n",
|
||||||
" \n",
|
" \n",
|
||||||
" if dsvm_compute.provisioning_state == 'Failed':\n",
|
" if dsvm_compute.provisioning_state == 'Failed':\n",
|
||||||
" print('Attached failed.')\n",
|
" print('Attached failed.')\n",
|
||||||
@@ -243,10 +243,10 @@
|
|||||||
"|Property|Description|\n",
|
"|Property|Description|\n",
|
||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**max_concurrent_iterations**|Maximum number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM.|\n",
|
"|**concurrent_iterations**|Maximum number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM.|\n",
|
||||||
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.|\n",
|
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.|\n",
|
||||||
"|**max_cores_per_iteration**|Indicates how many cores on the compute target would be used to train a single pipeline.<br>Default is *1*; you can set it to *-1* to use all cores.|"
|
"|**max_cores_per_iteration**|Indicates how many cores on the compute target would be used to train a single pipeline.<br>Default is *1*; you can set it to *-1* to use all cores.|"
|
||||||
]
|
]
|
||||||
@@ -258,8 +258,8 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"automl_settings = {\n",
|
"automl_settings = {\n",
|
||||||
" \"iteration_timeout_minutes\": 60,\n",
|
" \"max_time_sec\": 3600,\n",
|
||||||
" \"iterations\": 4,\n",
|
" \"iterations\": 10,\n",
|
||||||
" \"n_cross_validations\": 5,\n",
|
" \"n_cross_validations\": 5,\n",
|
||||||
" \"primary_metric\": 'AUC_weighted',\n",
|
" \"primary_metric\": 'AUC_weighted',\n",
|
||||||
" \"preprocess\": True,\n",
|
" \"preprocess\": True,\n",
|
||||||
@@ -312,20 +312,10 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(remote_run).show() "
|
"RunDetails(remote_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Wait until the run finishes.\n",
|
|
||||||
"remote_run.wait_for_completion(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
|
|||||||
@@ -155,18 +155,18 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"## Configure AutoML\n",
|
"## Configure AutoML\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment. This includes setting `experiment_exit_score`, which should cause the run to complete before the `iterations` count is reached.\n",
|
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment. This includes setting `exit_score`, which should cause the run to complete before the `iterations` count is reached.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"|Property|Description|\n",
|
"|Property|Description|\n",
|
||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**task**|classification or regression|\n",
|
"|**task**|classification or regression|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.|\n",
|
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.|\n",
|
||||||
"|**experiment_exit_score**|*double* value indicating the target for *primary_metric*. <br>Once the target is surpassed the run terminates.|\n",
|
"|**exit_score**|*double* value indicating the target for *primary_metric*. <br>Once the target is surpassed the run terminates.|\n",
|
||||||
"|**blacklist_models**|*List* of *strings* indicating machine learning algorithms for AutoML to avoid in this run.<br><br> Allowed values for **Classification**<br><i>LogisticRegression</i><br><i>SGD</i><br><i>MultinomialNaiveBayes</i><br><i>BernoulliNaiveBayes</i><br><i>SVM</i><br><i>LinearSVM</i><br><i>KNN</i><br><i>DecisionTree</i><br><i>RandomForest</i><br><i>ExtremeRandomTrees</i><br><i>LightGBM</i><br><i>GradientBoosting</i><br><i>TensorFlowDNN</i><br><i>TensorFlowLinearClassifier</i><br><br>Allowed values for **Regression**<br><i>ElasticNet</i><br><i>GradientBoosting</i><br><i>DecisionTree</i><br><i>KNN</i><br><i>LassoLars</i><br><i>SGD</i><br><i>RandomForest</i><br><i>ExtremeRandomTrees</i><br><i>LightGBM</i><br><i>TensorFlowLinearRegressor</i><br><i>TensorFlowDNN</i>|\n",
|
"|**blacklist_algos**|*List* of *strings* indicating machine learning algorithms for AutoML to avoid in this run.<br><br> Allowed values for **Classification**<br><i>LogisticRegression</i><br><i>SGDClassifierWrapper</i><br><i>NBWrapper</i><br><i>BernoulliNB</i><br><i>SVCWrapper</i><br><i>LinearSVMWrapper</i><br><i>KNeighborsClassifier</i><br><i>DecisionTreeClassifier</i><br><i>RandomForestClassifier</i><br><i>ExtraTreesClassifier</i><br><i>LightGBMClassifier</i><br><br>Allowed values for **Regression**<br><i>ElasticNet<i><br><i>GradientBoostingRegressor<i><br><i>DecisionTreeRegressor<i><br><i>KNeighborsRegressor<i><br><i>LassoLars<i><br><i>SGDRegressor<i><br><i>RandomForestRegressor<i><br><i>ExtraTreesRegressor<i>|\n",
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
||||||
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
||||||
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
||||||
@@ -181,12 +181,12 @@
|
|||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
" debug_log = 'automl_errors.log',\n",
|
" debug_log = 'automl_errors.log',\n",
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
" iteration_timeout_minutes = 60,\n",
|
" max_time_sec = 3600,\n",
|
||||||
" iterations = 20,\n",
|
" iterations = 20,\n",
|
||||||
" n_cross_validations = 5,\n",
|
" n_cross_validations = 5,\n",
|
||||||
" preprocess = True,\n",
|
" preprocess = True,\n",
|
||||||
" experiment_exit_score = 0.9984,\n",
|
" exit_score = 0.9984,\n",
|
||||||
" blacklist_models = ['KNN','LinearSVM'],\n",
|
" blacklist_algos = ['KNeighborsClassifier','LinearSVMWrapper'],\n",
|
||||||
" verbosity = logging.INFO,\n",
|
" verbosity = logging.INFO,\n",
|
||||||
" X = X_train, \n",
|
" X = X_train, \n",
|
||||||
" y = y_train,\n",
|
" y = y_train,\n",
|
||||||
@@ -236,7 +236,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(local_run).show() "
|
"RunDetails(local_run).show() "
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
384
automl/06.auto-ml-sparse-data-custom-cv-split.ipynb
Normal file
384
automl/06.auto-ml-sparse-data-custom-cv-split.ipynb
Normal file
@@ -0,0 +1,384 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
||||||
|
"\n",
|
||||||
|
"Licensed under the MIT License."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# AutoML 06: Custom CV Splits and Handling Sparse Data\n",
|
||||||
|
"\n",
|
||||||
|
"In this example we use the scikit-learn's [20newsgroup](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_20newsgroups.html) to showcase how you can use AutoML for handling sparse data and how to specify custom cross validations splits.\n",
|
||||||
|
"\n",
|
||||||
|
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
||||||
|
"\n",
|
||||||
|
"In this notebook you will learn how to:\n",
|
||||||
|
"1. Create an `Experiment` in an existing `Workspace`.\n",
|
||||||
|
"2. Configure AutoML using `AutoMLConfig`.\n",
|
||||||
|
"4. Train the model.\n",
|
||||||
|
"5. Explore the results.\n",
|
||||||
|
"6. Test the best fitted model.\n",
|
||||||
|
"\n",
|
||||||
|
"In addition this notebook showcases the following features\n",
|
||||||
|
"- **Custom CV** splits \n",
|
||||||
|
"- Handling **sparse data** in the input"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Create an Experiment\n",
|
||||||
|
"\n",
|
||||||
|
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import logging\n",
|
||||||
|
"import os\n",
|
||||||
|
"import random\n",
|
||||||
|
"\n",
|
||||||
|
"from matplotlib import pyplot as plt\n",
|
||||||
|
"from matplotlib.pyplot import imshow\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"from sklearn import datasets\n",
|
||||||
|
"\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"from azureml.core.experiment import Experiment\n",
|
||||||
|
"from azureml.core.workspace import Workspace\n",
|
||||||
|
"from azureml.train.automl import AutoMLConfig\n",
|
||||||
|
"from azureml.train.automl.run import AutoMLRun"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"ws = Workspace.from_config()\n",
|
||||||
|
"\n",
|
||||||
|
"# choose a name for the experiment\n",
|
||||||
|
"experiment_name = 'automl-local-missing-data'\n",
|
||||||
|
"# project folder\n",
|
||||||
|
"project_folder = './sample_projects/automl-local-missing-data'\n",
|
||||||
|
"\n",
|
||||||
|
"experiment = Experiment(ws, experiment_name)\n",
|
||||||
|
"\n",
|
||||||
|
"output = {}\n",
|
||||||
|
"output['SDK version'] = azureml.core.VERSION\n",
|
||||||
|
"output['Subscription ID'] = ws.subscription_id\n",
|
||||||
|
"output['Workspace'] = ws.name\n",
|
||||||
|
"output['Resource Group'] = ws.resource_group\n",
|
||||||
|
"output['Location'] = ws.location\n",
|
||||||
|
"output['Project Directory'] = project_folder\n",
|
||||||
|
"output['Experiment Name'] = experiment.name\n",
|
||||||
|
"pd.set_option('display.max_colwidth', -1)\n",
|
||||||
|
"pd.DataFrame(data=output, index=['']).T"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Diagnostics\n",
|
||||||
|
"\n",
|
||||||
|
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.telemetry import set_diagnostics_collection\n",
|
||||||
|
"set_diagnostics_collection(send_diagnostics = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Creating Sparse Data"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from sklearn.datasets import fetch_20newsgroups\n",
|
||||||
|
"from sklearn.feature_extraction.text import HashingVectorizer\n",
|
||||||
|
"from sklearn.model_selection import train_test_split\n",
|
||||||
|
"\n",
|
||||||
|
"remove = ('headers', 'footers', 'quotes')\n",
|
||||||
|
"categories = [\n",
|
||||||
|
" 'alt.atheism',\n",
|
||||||
|
" 'talk.religion.misc',\n",
|
||||||
|
" 'comp.graphics',\n",
|
||||||
|
" 'sci.space',\n",
|
||||||
|
"]\n",
|
||||||
|
"data_train = fetch_20newsgroups(subset = 'train', categories = categories,\n",
|
||||||
|
" shuffle = True, random_state = 42,\n",
|
||||||
|
" remove = remove)\n",
|
||||||
|
"\n",
|
||||||
|
"X_train, X_valid, y_train, y_valid = train_test_split(data_train.data, data_train.target, test_size = 0.33, random_state = 42)\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"vectorizer = HashingVectorizer(stop_words = 'english', alternate_sign = False,\n",
|
||||||
|
" n_features = 2**16)\n",
|
||||||
|
"X_train = vectorizer.transform(X_train)\n",
|
||||||
|
"X_valid = vectorizer.transform(X_valid)\n",
|
||||||
|
"\n",
|
||||||
|
"summary_df = pd.DataFrame(index = ['No of Samples', 'No of Features'])\n",
|
||||||
|
"summary_df['Train Set'] = [X_train.shape[0], X_train.shape[1]]\n",
|
||||||
|
"summary_df['Validation Set'] = [X_valid.shape[0], X_valid.shape[1]]\n",
|
||||||
|
"summary_df"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Configure AutoML\n",
|
||||||
|
"\n",
|
||||||
|
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment.\n",
|
||||||
|
"\n",
|
||||||
|
"|Property|Description|\n",
|
||||||
|
"|-|-|\n",
|
||||||
|
"|**task**|classification or regression|\n",
|
||||||
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
|
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.<br>**Note:** If input data is sparse, you cannot use *True*.|\n",
|
||||||
|
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
||||||
|
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
||||||
|
"|**X_valid**|(sparse) array-like, shape = [n_samples, n_features] for the custom validation set.|\n",
|
||||||
|
"|**y_valid**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification for the custom validation set.|\n",
|
||||||
|
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
|
" debug_log = 'automl_errors.log',\n",
|
||||||
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
|
" max_time_sec = 3600,\n",
|
||||||
|
" iterations = 5,\n",
|
||||||
|
" preprocess = False,\n",
|
||||||
|
" verbosity = logging.INFO,\n",
|
||||||
|
" X = X_train, \n",
|
||||||
|
" y = y_train,\n",
|
||||||
|
" X_valid = X_valid, \n",
|
||||||
|
" y_valid = y_valid, \n",
|
||||||
|
" path = project_folder)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Train the Models\n",
|
||||||
|
"\n",
|
||||||
|
"Call the `submit` method on the experiment object and pass the run configuration. Execution of local runs is synchronous. Depending on the data and the number of iterations this can run for a while.\n",
|
||||||
|
"In this example, we specify `show_output = True` to print currently running iterations to the console."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"local_run = experiment.submit(automl_config, show_output=True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Explore the Results"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Widget for Monitoring Runs\n",
|
||||||
|
"\n",
|
||||||
|
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
||||||
|
"\n",
|
||||||
|
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
|
"RunDetails(local_run).show() "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"\n",
|
||||||
|
"#### Retrieve All Child Runs\n",
|
||||||
|
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"children = list(local_run.get_children())\n",
|
||||||
|
"metricslist = {}\n",
|
||||||
|
"for run in children:\n",
|
||||||
|
" properties = run.get_properties()\n",
|
||||||
|
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
||||||
|
" metricslist[int(properties['iteration'])] = metrics\n",
|
||||||
|
" \n",
|
||||||
|
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
||||||
|
"rundata"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Retrieve the Best Model\n",
|
||||||
|
"\n",
|
||||||
|
"Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. The Model includes the pipeline and any pre-processing. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"best_run, fitted_model = local_run.get_output()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Best Model Based on Any Other Metric\n",
|
||||||
|
"Show the run and the model which has the smallest `accuracy` value:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# lookup_metric = \"accuracy\"\n",
|
||||||
|
"# best_run, fitted_model = local_run.get_output(metric = lookup_metric)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Model from a Specific Iteration\n",
|
||||||
|
"Show the run and the model from the third iteration:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# iteration = 3\n",
|
||||||
|
"# best_run, fitted_model = local_run.get_output(iteration = iteration)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Testing the Best Fitted Model"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Load test data.\n",
|
||||||
|
"from pandas_ml import ConfusionMatrix\n",
|
||||||
|
"\n",
|
||||||
|
"data_test = fetch_20newsgroups(subset = 'test', categories = categories,\n",
|
||||||
|
" shuffle = True, random_state = 42,\n",
|
||||||
|
" remove = remove)\n",
|
||||||
|
"\n",
|
||||||
|
"X_test = vectorizer.transform(data_test.data)\n",
|
||||||
|
"y_test = data_test.target\n",
|
||||||
|
"\n",
|
||||||
|
"# Test our best pipeline.\n",
|
||||||
|
"\n",
|
||||||
|
"y_pred = fitted_model.predict(X_test)\n",
|
||||||
|
"y_pred_strings = [data_test.target_names[i] for i in y_pred]\n",
|
||||||
|
"y_test_strings = [data_test.target_names[i] for i in y_test]\n",
|
||||||
|
"\n",
|
||||||
|
"cm = ConfusionMatrix(y_test_strings, y_pred_strings)\n",
|
||||||
|
"print(cm)\n",
|
||||||
|
"cm.plot()"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"authors": [
|
||||||
|
{
|
||||||
|
"name": "savitam"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python36"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.6"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -1,384 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 06: Train Test Split and Handling Sparse Data\n",
|
|
||||||
"\n",
|
|
||||||
"In this example we use the scikit-learn's [20newsgroup](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_20newsgroups.html) to showcase how you can use AutoML for handling sparse data and how to specify custom cross validations splits.\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you will learn how to:\n",
|
|
||||||
"1. Create an `Experiment` in an existing `Workspace`.\n",
|
|
||||||
"2. Configure AutoML using `AutoMLConfig`.\n",
|
|
||||||
"4. Train the model.\n",
|
|
||||||
"5. Explore the results.\n",
|
|
||||||
"6. Test the best fitted model.\n",
|
|
||||||
"\n",
|
|
||||||
"In addition this notebook showcases the following features\n",
|
|
||||||
"- Explicit train test splits \n",
|
|
||||||
"- Handling **sparse data** in the input"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create an Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import random\n",
|
|
||||||
"\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
|
||||||
"from azureml.train.automl.run import AutoMLRun"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"\n",
|
|
||||||
"# choose a name for the experiment\n",
|
|
||||||
"experiment_name = 'automl-local-missing-data'\n",
|
|
||||||
"# project folder\n",
|
|
||||||
"project_folder = './sample_projects/automl-local-missing-data'\n",
|
|
||||||
"\n",
|
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
|
||||||
"\n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data=output, index=['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Creating Sparse Data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn.datasets import fetch_20newsgroups\n",
|
|
||||||
"from sklearn.feature_extraction.text import HashingVectorizer\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"\n",
|
|
||||||
"remove = ('headers', 'footers', 'quotes')\n",
|
|
||||||
"categories = [\n",
|
|
||||||
" 'alt.atheism',\n",
|
|
||||||
" 'talk.religion.misc',\n",
|
|
||||||
" 'comp.graphics',\n",
|
|
||||||
" 'sci.space',\n",
|
|
||||||
"]\n",
|
|
||||||
"data_train = fetch_20newsgroups(subset = 'train', categories = categories,\n",
|
|
||||||
" shuffle = True, random_state = 42,\n",
|
|
||||||
" remove = remove)\n",
|
|
||||||
"\n",
|
|
||||||
"X_train, X_valid, y_train, y_valid = train_test_split(data_train.data, data_train.target, test_size = 0.33, random_state = 42)\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"vectorizer = HashingVectorizer(stop_words = 'english', alternate_sign = False,\n",
|
|
||||||
" n_features = 2**16)\n",
|
|
||||||
"X_train = vectorizer.transform(X_train)\n",
|
|
||||||
"X_valid = vectorizer.transform(X_valid)\n",
|
|
||||||
"\n",
|
|
||||||
"summary_df = pd.DataFrame(index = ['No of Samples', 'No of Features'])\n",
|
|
||||||
"summary_df['Train Set'] = [X_train.shape[0], X_train.shape[1]]\n",
|
|
||||||
"summary_df['Validation Set'] = [X_valid.shape[0], X_valid.shape[1]]\n",
|
|
||||||
"summary_df"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment.\n",
|
|
||||||
"\n",
|
|
||||||
"|Property|Description|\n",
|
|
||||||
"|-|-|\n",
|
|
||||||
"|**task**|classification or regression|\n",
|
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
|
||||||
"|**preprocess**|Setting this to *True* enables AutoML to perform preprocessing on the input to handle *missing data*, and to perform some common *feature extraction*.<br>**Note:** If input data is sparse, you cannot use *True*.|\n",
|
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
|
||||||
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
|
||||||
"|**X_valid**|(sparse) array-like, shape = [n_samples, n_features] for the custom validation set.|\n",
|
|
||||||
"|**y_valid**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification for the custom validation set.|\n",
|
|
||||||
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'automl_errors.log',\n",
|
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
|
||||||
" iteration_timeout_minutes = 60,\n",
|
|
||||||
" iterations = 5,\n",
|
|
||||||
" preprocess = False,\n",
|
|
||||||
" verbosity = logging.INFO,\n",
|
|
||||||
" X = X_train, \n",
|
|
||||||
" y = y_train,\n",
|
|
||||||
" X_valid = X_valid, \n",
|
|
||||||
" y_valid = y_valid, \n",
|
|
||||||
" path = project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Train the Models\n",
|
|
||||||
"\n",
|
|
||||||
"Call the `submit` method on the experiment object and pass the run configuration. Execution of local runs is synchronous. Depending on the data and the number of iterations this can run for a while.\n",
|
|
||||||
"In this example, we specify `show_output = True` to print currently running iterations to the console."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = experiment.submit(automl_config, show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Explore the Results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Widget for Monitoring Runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(local_run).show() "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"\n",
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(local_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
" \n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. The Model includes the pipeline and any pre-processing. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = local_run.get_output()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model Based on Any Other Metric\n",
|
|
||||||
"Show the run and the model which has the smallest `accuracy` value:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# lookup_metric = \"accuracy\"\n",
|
|
||||||
"# best_run, fitted_model = local_run.get_output(metric = lookup_metric)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Model from a Specific Iteration\n",
|
|
||||||
"Show the run and the model from the third iteration:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# iteration = 3\n",
|
|
||||||
"# best_run, fitted_model = local_run.get_output(iteration = iteration)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Testing the Best Fitted Model"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Load test data.\n",
|
|
||||||
"from pandas_ml import ConfusionMatrix\n",
|
|
||||||
"\n",
|
|
||||||
"data_test = fetch_20newsgroups(subset = 'test', categories = categories,\n",
|
|
||||||
" shuffle = True, random_state = 42,\n",
|
|
||||||
" remove = remove)\n",
|
|
||||||
"\n",
|
|
||||||
"X_test = vectorizer.transform(data_test.data)\n",
|
|
||||||
"y_test = data_test.target\n",
|
|
||||||
"\n",
|
|
||||||
"# Test our best pipeline.\n",
|
|
||||||
"\n",
|
|
||||||
"y_pred = fitted_model.predict(X_test)\n",
|
|
||||||
"y_pred_strings = [data_test.target_names[i] for i in y_pred]\n",
|
|
||||||
"y_test_strings = [data_test.target_names[i] for i in y_test]\n",
|
|
||||||
"\n",
|
|
||||||
"cm = ConfusionMatrix(y_test_strings, y_pred_strings)\n",
|
|
||||||
"print(cm)\n",
|
|
||||||
"cm.plot()"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "savitam"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -116,11 +116,10 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"experiment_name = 'automl-local-classification' # Replace this with any project name from previous cell.\n",
|
"experiment_name = 'automl-local-classification' # Replace this with any project name from previous cell.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"proj = ws.experiments[experiment_name]\n",
|
"proj = ws.experiments()[experiment_name]\n",
|
||||||
"summary_df = pd.DataFrame(index = ['Type', 'Status', 'Primary Metric', 'Iterations', 'Compute', 'Name'])\n",
|
"summary_df = pd.DataFrame(index = ['Type', 'Status', 'Primary Metric', 'Iterations', 'Compute', 'Name'])\n",
|
||||||
"pattern = re.compile('^AutoML_[^_]*$')\n",
|
"pattern = re.compile('^AutoML_[^_]*$')\n",
|
||||||
"all_runs = list(proj.get_runs(properties={'azureml.runsource': 'automl'}))\n",
|
"all_runs = list(proj.get_runs(properties={'azureml.runsource': 'automl'}))\n",
|
||||||
"automl_runs_project = []\n",
|
|
||||||
"for run in all_runs:\n",
|
"for run in all_runs:\n",
|
||||||
" if(pattern.match(run.id)):\n",
|
" if(pattern.match(run.id)):\n",
|
||||||
" properties = run.get_properties()\n",
|
" properties = run.get_properties()\n",
|
||||||
@@ -131,8 +130,6 @@
|
|||||||
" else:\n",
|
" else:\n",
|
||||||
" iterations = properties['num_iterations']\n",
|
" iterations = properties['num_iterations']\n",
|
||||||
" summary_df[run.id] = [amlsettings['task_type'], run.get_details()['status'], properties['primary_metric'], iterations, properties['target'], amlsettings['name']]\n",
|
" summary_df[run.id] = [amlsettings['task_type'], run.get_details()['status'], properties['primary_metric'], iterations, properties['target'], amlsettings['name']]\n",
|
||||||
" if run.get_details()['status'] == 'Completed':\n",
|
|
||||||
" automl_runs_project.append(run.id)\n",
|
|
||||||
" \n",
|
" \n",
|
||||||
"from IPython.display import HTML\n",
|
"from IPython.display import HTML\n",
|
||||||
"projname_html = HTML(\"<h3>{}</h3>\".format(proj.name))\n",
|
"projname_html = HTML(\"<h3>{}</h3>\".format(proj.name))\n",
|
||||||
@@ -157,10 +154,10 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"run_id = automl_runs_project[0] # Replace with your own run_id from above run ids\n",
|
"run_id = '' # Filling your own run_id from above run ids\n",
|
||||||
"assert (run_id in summary_df.keys()),\"Run id not found! Please set run id to a value from above run ids\"\n",
|
"assert (run_id in summary_df.keys()),\"Run id not found! Please set run id to a value from above run ids\"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"\n",
|
"\n",
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
"experiment = Experiment(ws, experiment_name)\n",
|
||||||
"ml_run = AutoMLRun(experiment = experiment, run_id = run_id)\n",
|
"ml_run = AutoMLRun(experiment = experiment, run_id = run_id)\n",
|
||||||
@@ -241,7 +238,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"iteration = 1 # Replace with an iteration number.\n",
|
"iteration = 4 # Replace with an iteration number.\n",
|
||||||
"best_run, fitted_model = ml_run.get_output(iteration = iteration)\n",
|
"best_run, fitted_model = ml_run.get_output(iteration = iteration)\n",
|
||||||
"fitted_model"
|
"fitted_model"
|
||||||
]
|
]
|
||||||
@@ -299,7 +296,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"iteration = 1 # Replace with an iteration number.\n",
|
"iteration = 4 # Replace with an iteration number.\n",
|
||||||
"description = 'AutoML Model'\n",
|
"description = 'AutoML Model'\n",
|
||||||
"tags = None\n",
|
"tags = None\n",
|
||||||
"ml_run.register_model(description = description, tags = tags, iteration = iteration)\n",
|
"ml_run.register_model(description = description, tags = tags, iteration = iteration)\n",
|
||||||
|
|||||||
@@ -1,568 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 08: Remote Execution with DataStore\n",
|
|
||||||
"\n",
|
|
||||||
"This sample accesses a data file on a remote DSVM through DataStore. Advantages of using data store are:\n",
|
|
||||||
"1. DataStore secures the access details.\n",
|
|
||||||
"2. DataStore supports read, write to blob and file store\n",
|
|
||||||
"3. AutoML natively supports copying data from DataStore to DSVM\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you would see\n",
|
|
||||||
"1. Storing data in DataStore.\n",
|
|
||||||
"2. get_data returning data from DataStore.\n",
|
|
||||||
"\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created a <b>Workspace</b>. For AutoML you would need to create an <b>Experiment</b>. An <b>Experiment</b> is a named object in a <b>Workspace</b>, which is used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import random\n",
|
|
||||||
"import time\n",
|
|
||||||
"\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.compute import DsvmCompute\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
|
||||||
"from azureml.train.automl.run import AutoMLRun"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"\n",
|
|
||||||
"# choose a name for experiment\n",
|
|
||||||
"experiment_name = 'automl-remote-datastore-file'\n",
|
|
||||||
"# project folder\n",
|
|
||||||
"project_folder = './sample_projects/automl-remote-dsvm-file'\n",
|
|
||||||
"\n",
|
|
||||||
"experiment=Experiment(ws, experiment_name)\n",
|
|
||||||
"\n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data=output, index=['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create a Remote Linux DSVM\n",
|
|
||||||
"Note: If creation fails with a message about Marketplace purchase eligibilty, go to portal.azure.com, start creating DSVM there, and select \"Want to create programmatically\" to enable programmatic creation. Once you've enabled it, you can exit without actually creating VM.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note**: By default SSH runs on port 22 and you don't need to specify it. But if for security reasons you can switch to a different port (such as 5022), you can append the port number to the address. [Read more](https://render.githubusercontent.com/documentation/sdk/ssh-issue.md) on this."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"compute_target_name = 'mydsvmc'\n",
|
|
||||||
"\n",
|
|
||||||
"try:\n",
|
|
||||||
" while ws.compute_targets[compute_target_name].provisioning_state == 'Creating':\n",
|
|
||||||
" time.sleep(1)\n",
|
|
||||||
" \n",
|
|
||||||
" dsvm_compute = DsvmCompute(workspace=ws, name=compute_target_name)\n",
|
|
||||||
" print('found existing:', dsvm_compute.name)\n",
|
|
||||||
"except:\n",
|
|
||||||
" dsvm_config = DsvmCompute.provisioning_configuration(vm_size=\"Standard_D2_v2\")\n",
|
|
||||||
" dsvm_compute = DsvmCompute.create(ws, name=compute_target_name, provisioning_configuration=dsvm_config)\n",
|
|
||||||
" dsvm_compute.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Copy data file to local\n",
|
|
||||||
"\n",
|
|
||||||
"Download the data file.\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"mkdir data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"df = pd.read_csv(\"https://automldemods.blob.core.windows.net/datasets/PlayaEvents2016,_1.6MB,_3.4k-rows.cleaned.2.tsv\",\n",
|
|
||||||
" delimiter=\"\\t\", quotechar='\"')\n",
|
|
||||||
"df.to_csv(\"data/data.tsv\", sep=\"\\t\", quotechar='\"', index=False)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Upload data to the cloud"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Now make the data accessible remotely by uploading that data from your local machine into Azure so it can be accessed for remote training. The datastore is a convenient construct associated with your workspace for you to upload/download data, and interact with it from your remote compute targets. It is backed by Azure blob storage account.\n",
|
|
||||||
"\n",
|
|
||||||
"The data.tsv files are uploaded into a directory named data at the root of the datastore."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core import Workspace, Datastore\n",
|
|
||||||
"#blob_datastore = Datastore(ws, blob_datastore_name)\n",
|
|
||||||
"ds = ws.get_default_datastore()\n",
|
|
||||||
"print(ds.datastore_type, ds.account_name, ds.container_name)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# ds.upload_files(\"data.tsv\")\n",
|
|
||||||
"ds.upload(src_dir='./data', target_path='data', overwrite=True, show_progress=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure & Run\n",
|
|
||||||
"\n",
|
|
||||||
"First let's create a DataReferenceConfigruation object to inform the system what data folder to download to the compute target.\n",
|
|
||||||
"The path_on_compute should be an absolute path to ensure that the data files are downloaded only once. The get_data method should use this same path to access the data files."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.runconfig import DataReferenceConfiguration\n",
|
|
||||||
"dr = DataReferenceConfiguration(datastore_name=ds.name, \n",
|
|
||||||
" path_on_datastore='data', \n",
|
|
||||||
" path_on_compute='/tmp/azureml_runs',\n",
|
|
||||||
" mode='download', # download files from datastore to compute target\n",
|
|
||||||
" overwrite=False)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.runconfig import RunConfiguration\n",
|
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies\n",
|
|
||||||
"\n",
|
|
||||||
"# create a new RunConfig object\n",
|
|
||||||
"conda_run_config = RunConfiguration(framework=\"python\")\n",
|
|
||||||
"\n",
|
|
||||||
"# Set compute target to the Linux DSVM\n",
|
|
||||||
"conda_run_config.target = dsvm_compute\n",
|
|
||||||
"# set the data reference of the run coonfiguration\n",
|
|
||||||
"conda_run_config.data_references = {ds.name: dr}\n",
|
|
||||||
"\n",
|
|
||||||
"cd = CondaDependencies.create(pip_packages=['azureml-sdk[automl]'], conda_packages=['numpy'])\n",
|
|
||||||
"conda_run_config.environment.python.conda_dependencies = cd"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create Get Data File\n",
|
|
||||||
"For remote executions you should author a get_data.py file containing a get_data() function. This file should be in the root directory of the project. You can encapsulate code to read data either from a blob storage or local disk in this file.\n",
|
|
||||||
"\n",
|
|
||||||
"The *get_data()* function returns a [dictionary](README.md#getdata).\n",
|
|
||||||
"\n",
|
|
||||||
"The read_csv uses the path_on_compute value specified in the DataReferenceConfiguration call plus the path_on_datastore folder and then the actual file name."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if not os.path.exists(project_folder):\n",
|
|
||||||
" os.makedirs(project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%%writefile $project_folder/get_data.py\n",
|
|
||||||
"\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"from sklearn.preprocessing import LabelEncoder\n",
|
|
||||||
"import os\n",
|
|
||||||
"from os.path import expanduser, join, dirname\n",
|
|
||||||
"\n",
|
|
||||||
"def get_data():\n",
|
|
||||||
" # Burning man 2016 data\n",
|
|
||||||
" df = pd.read_csv(\"/tmp/azureml_runs/data/data.tsv\", delimiter=\"\\t\", quotechar='\"')\n",
|
|
||||||
" # get integer labels\n",
|
|
||||||
" le = LabelEncoder()\n",
|
|
||||||
" le.fit(df[\"Label\"].values)\n",
|
|
||||||
" y = le.transform(df[\"Label\"].values)\n",
|
|
||||||
" X = df.drop([\"Label\"], axis=1)\n",
|
|
||||||
"\n",
|
|
||||||
" X_train, _, y_train, _ = train_test_split(X, y, test_size=0.1, random_state=42)\n",
|
|
||||||
"\n",
|
|
||||||
" return { \"X\" : X_train.values, \"y\" : y_train }"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Instantiate AutoML <a class=\"anchor\" id=\"Instatiate-AutoML-Remote-DSVM\"></a>\n",
|
|
||||||
"\n",
|
|
||||||
"You can specify automl_settings as **kwargs** as well. Also note that you can use the get_data() symantic for local excutions too. \n",
|
|
||||||
"\n",
|
|
||||||
"<i>Note: For Remote DSVM and Batch AI you cannot pass Numpy arrays directly to AutoMLConfig.</i>\n",
|
|
||||||
"\n",
|
|
||||||
"|Property|Description|\n",
|
|
||||||
"|-|-|\n",
|
|
||||||
"|**primary_metric**|This is the metric that you want to optimize.<br> Classification supports the following primary metrics <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration|\n",
|
|
||||||
"|**iterations**|Number of iterations. In each iteration Auto ML trains a specific pipeline with the data|\n",
|
|
||||||
"|**n_cross_validations**|Number of cross validation splits|\n",
|
|
||||||
"|**max_concurrent_iterations**|Max number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM\n",
|
|
||||||
"|**preprocess**| *True/False* <br>Setting this to *True* enables Auto ML to perform preprocessing <br>on the input to handle *missing data*, and perform some common *feature extraction*|\n",
|
|
||||||
"|**max_cores_per_iteration**| Indicates how many cores on the compute target would be used to train a single pipeline.<br> Default is *1*, you can set it to *-1* to use all cores|"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_settings = {\n",
|
|
||||||
" \"iteration_timeout_minutes\": 60,\n",
|
|
||||||
" \"iterations\": 4,\n",
|
|
||||||
" \"n_cross_validations\": 5,\n",
|
|
||||||
" \"primary_metric\": 'AUC_weighted',\n",
|
|
||||||
" \"preprocess\": True,\n",
|
|
||||||
" \"max_cores_per_iteration\": 1,\n",
|
|
||||||
" \"verbosity\": logging.INFO\n",
|
|
||||||
"}\n",
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'automl_errors.log',\n",
|
|
||||||
" path=project_folder,\n",
|
|
||||||
" run_configuration=conda_run_config,\n",
|
|
||||||
" #compute_target = dsvm_compute,\n",
|
|
||||||
" data_script = project_folder + \"/get_data.py\",\n",
|
|
||||||
" **automl_settings\n",
|
|
||||||
" )"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Training the Models <a class=\"anchor\" id=\"Training-the-model-Remote-DSVM\"></a>\n",
|
|
||||||
"\n",
|
|
||||||
"For remote runs the execution is asynchronous, so you will see the iterations get populated as they complete. You can interact with the widgets/models even when the experiment is running to retreive the best model up to that point. Once you are satisfied with the model you can cancel a particular iteration or the whole run."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"remote_run = experiment.submit(automl_config, show_output=False)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Exploring the Results <a class=\"anchor\" id=\"Exploring-the-Results-Remote-DSVM\"></a>\n",
|
|
||||||
"#### Widget for monitoring runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will sit on \"loading\" until the first iteration completed, then you will see an auto-updating graph and table show up. It refreshed once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"You can click on a pipeline to see run properties and output logs. Logs are also available on the DSVM under /tmp/azureml_run/{iterationid}/azureml-logs\n",
|
|
||||||
"\n",
|
|
||||||
"NOTE: The widget displays a link at the bottom. This links to a web-ui to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(remote_run).show() "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Wait until the run finishes.\n",
|
|
||||||
"remote_run.wait_for_completion(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"\n",
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use sdk methods to fetch all the child runs and see individual metrics that we log. "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(remote_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)} \n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
"\n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Canceling Runs\n",
|
|
||||||
"You can cancel ongoing remote runs using the *cancel()* and *cancel_iteration()* functions"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Cancel the ongoing experiment and stop scheduling new iterations\n",
|
|
||||||
"# remote_run.cancel()\n",
|
|
||||||
"\n",
|
|
||||||
"# Cancel iteration 1 and move onto iteration 2\n",
|
|
||||||
"# remote_run.cancel_iteration(1)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The *get_output* method returns the best run and the fitted model. There are overloads on *get_output* that allow you to retrieve the best run and fitted model for *any* logged metric or a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = remote_run.get_output()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model based on any other metric"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# lookup_metric = \"accuracy\"\n",
|
|
||||||
"# best_run, fitted_model = remote_run.get_output(metric=lookup_metric)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Model from a specific iteration"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# iteration = 1\n",
|
|
||||||
"# best_run, fitted_model = remote_run.get_output(iteration=iteration)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Testing the Best Fitted Model <a class=\"anchor\" id=\"Testing-the-Fitted-Model-Remote-DSVM\"></a>\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import sklearn\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"from sklearn.preprocessing import LabelEncoder\n",
|
|
||||||
"from pandas_ml import ConfusionMatrix\n",
|
|
||||||
"\n",
|
|
||||||
"df = pd.read_csv(\"https://automldemods.blob.core.windows.net/datasets/PlayaEvents2016,_1.6MB,_3.4k-rows.cleaned.2.tsv\",\n",
|
|
||||||
" delimiter=\"\\t\", quotechar='\"')\n",
|
|
||||||
"\n",
|
|
||||||
"# get integer labels\n",
|
|
||||||
"le = LabelEncoder()\n",
|
|
||||||
"le.fit(df[\"Label\"].values)\n",
|
|
||||||
"y = le.transform(df[\"Label\"].values)\n",
|
|
||||||
"X = df.drop([\"Label\"], axis=1)\n",
|
|
||||||
"\n",
|
|
||||||
"_, X_test, _, y_test = train_test_split(X, y, test_size=0.1, random_state=42)\n",
|
|
||||||
"\n",
|
|
||||||
"ypred = fitted_model.predict(X_test.values)\n",
|
|
||||||
"\n",
|
|
||||||
"ypred_strings = le.inverse_transform(ypred)\n",
|
|
||||||
"ytest_strings = le.inverse_transform(y_test)\n",
|
|
||||||
"\n",
|
|
||||||
"cm = ConfusionMatrix(ytest_strings, ypred_strings)\n",
|
|
||||||
"\n",
|
|
||||||
"print(cm)\n",
|
|
||||||
"\n",
|
|
||||||
"cm.plot()"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "savitam"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
550
automl/08.auto-ml-remote-execution-with-text-file-on-DSVM.ipynb
Normal file
550
automl/08.auto-ml-remote-execution-with-text-file-on-DSVM.ipynb
Normal file
@@ -0,0 +1,550 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
||||||
|
"\n",
|
||||||
|
"Licensed under the MIT License."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# AutoML 08: Remote Execution with DataStore\n",
|
||||||
|
"\n",
|
||||||
|
"This sample accesses a data file on a remote DSVM through DataStore. Advantages of using data store are:\n",
|
||||||
|
"1. DataStore secures the access details.\n",
|
||||||
|
"2. DataStore supports read, write to blob and file store\n",
|
||||||
|
"3. AutoML natively supports copying data from DataStore to DSVM\n",
|
||||||
|
"\n",
|
||||||
|
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
||||||
|
"\n",
|
||||||
|
"In this notebook you would see\n",
|
||||||
|
"1. Storing data in DataStore.\n",
|
||||||
|
"2. get_data returning data from DataStore.\n",
|
||||||
|
"\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Create Experiment\n",
|
||||||
|
"\n",
|
||||||
|
"As part of the setup you have already created a <b>Workspace</b>. For AutoML you would need to create an <b>Experiment</b>. An <b>Experiment</b> is a named object in a <b>Workspace</b>, which is used to run experiments."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import logging\n",
|
||||||
|
"import os\n",
|
||||||
|
"import random\n",
|
||||||
|
"\n",
|
||||||
|
"from matplotlib import pyplot as plt\n",
|
||||||
|
"from matplotlib.pyplot import imshow\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"from sklearn import datasets\n",
|
||||||
|
"\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"from azureml.core.experiment import Experiment\n",
|
||||||
|
"from azureml.core.workspace import Workspace\n",
|
||||||
|
"from azureml.train.automl import AutoMLConfig\n",
|
||||||
|
"from azureml.train.automl.run import AutoMLRun"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"ws = Workspace.from_config()\n",
|
||||||
|
"\n",
|
||||||
|
"# choose a name for experiment\n",
|
||||||
|
"experiment_name = 'automl-remote-datastore-file'\n",
|
||||||
|
"# project folder\n",
|
||||||
|
"project_folder = './sample_projects/automl-remote-dsvm-file'\n",
|
||||||
|
"\n",
|
||||||
|
"experiment=Experiment(ws, experiment_name)\n",
|
||||||
|
"\n",
|
||||||
|
"output = {}\n",
|
||||||
|
"output['SDK version'] = azureml.core.VERSION\n",
|
||||||
|
"output['Subscription ID'] = ws.subscription_id\n",
|
||||||
|
"output['Workspace'] = ws.name\n",
|
||||||
|
"output['Resource Group'] = ws.resource_group\n",
|
||||||
|
"output['Location'] = ws.location\n",
|
||||||
|
"output['Project Directory'] = project_folder\n",
|
||||||
|
"output['Experiment Name'] = experiment.name\n",
|
||||||
|
"pd.set_option('display.max_colwidth', -1)\n",
|
||||||
|
"pd.DataFrame(data=output, index=['']).T"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Diagnostics\n",
|
||||||
|
"\n",
|
||||||
|
"Opt-in diagnostics for better experience, quality, and security of future releases"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.telemetry import set_diagnostics_collection\n",
|
||||||
|
"set_diagnostics_collection(send_diagnostics=True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Create a Remote Linux DSVM\n",
|
||||||
|
"Note: If creation fails with a message about Marketplace purchase eligibilty, go to portal.azure.com, start creating DSVM there, and select \"Want to create programmatically\" to enable programmatic creation. Once you've enabled it, you can exit without actually creating VM.\n",
|
||||||
|
"\n",
|
||||||
|
"**Note**: By default SSH runs on port 22 and you don't need to specify it. But if for security reasons you can switch to a different port (such as 5022), you can append the port number to the address. [Read more](https://render.githubusercontent.com/documentation/sdk/ssh-issue.md) on this."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.compute import DsvmCompute\n",
|
||||||
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
|
"\n",
|
||||||
|
"compute_target_name = 'mydsvm'\n",
|
||||||
|
"\n",
|
||||||
|
"try:\n",
|
||||||
|
" dsvm_compute = DsvmCompute(workspace=ws, name=compute_target_name)\n",
|
||||||
|
" print('found existing:', dsvm_compute.name)\n",
|
||||||
|
"except ComputeTargetException:\n",
|
||||||
|
" dsvm_config = DsvmCompute.provisioning_configuration(vm_size=\"Standard_D2_v2\")\n",
|
||||||
|
" dsvm_compute = DsvmCompute.create(ws, name=compute_target_name, provisioning_configuration=dsvm_config)\n",
|
||||||
|
" dsvm_compute.wait_for_completion(show_output=True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Copy data file to local\n",
|
||||||
|
"\n",
|
||||||
|
"Download the data file.\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"mkdir data"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"df = pd.read_csv(\"https://automldemods.blob.core.windows.net/datasets/PlayaEvents2016,_1.6MB,_3.4k-rows.cleaned.2.tsv\",\n",
|
||||||
|
" delimiter=\"\\t\", quotechar='\"')\n",
|
||||||
|
"df.to_csv(\"data/data.tsv\", sep=\"\\t\", quotechar='\"', index=False)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Upload data to the cloud"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Now make the data accessible remotely by uploading that data from your local machine into Azure so it can be accessed for remote training. The datastore is a convenient construct associated with your workspace for you to upload/download data, and interact with it from your remote compute targets. It is backed by Azure blob storage account.\n",
|
||||||
|
"\n",
|
||||||
|
"The data.tsv files are uploaded into a directory named data at the root of the datastore."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core import Workspace, Datastore\n",
|
||||||
|
"#blob_datastore = Datastore(ws, blob_datastore_name)\n",
|
||||||
|
"ds = ws.get_default_datastore()\n",
|
||||||
|
"print(ds.datastore_type, ds.account_name, ds.container_name)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# ds.upload_files(\"data.tsv\")\n",
|
||||||
|
"ds.upload(src_dir='./data', target_path='data', overwrite=True, show_progress=True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Configure & Run\n",
|
||||||
|
"\n",
|
||||||
|
"First let's create a DataReferenceConfigruation object to inform the system what data folder to download to the copmute target."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.runconfig import DataReferenceConfiguration\n",
|
||||||
|
"dr = DataReferenceConfiguration(datastore_name=ds.name, \n",
|
||||||
|
" path_on_datastore='data', \n",
|
||||||
|
" mode='download', # download files from datastore to compute target\n",
|
||||||
|
" overwrite=True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.runconfig import RunConfiguration\n",
|
||||||
|
"\n",
|
||||||
|
"# create a new RunConfig object\n",
|
||||||
|
"conda_run_config = RunConfiguration(framework=\"python\")\n",
|
||||||
|
"\n",
|
||||||
|
"# Set compute target to the Linux DSVM\n",
|
||||||
|
"conda_run_config.target = dsvm_compute.name\n",
|
||||||
|
"# set the data reference of the run coonfiguration\n",
|
||||||
|
"conda_run_config.data_references = {ds.name: dr}"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Create Get Data File\n",
|
||||||
|
"For remote executions you should author a get_data.py file containing a get_data() function. This file should be in the root directory of the project. You can encapsulate code to read data either from a blob storage or local disk in this file.\n",
|
||||||
|
"\n",
|
||||||
|
"The *get_data()* function returns a [dictionary](README.md#getdata)."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"if not os.path.exists(project_folder):\n",
|
||||||
|
" os.makedirs(project_folder)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"%%writefile $project_folder/get_data.py\n",
|
||||||
|
"\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"from sklearn.model_selection import train_test_split\n",
|
||||||
|
"from sklearn.preprocessing import LabelEncoder\n",
|
||||||
|
"import os\n",
|
||||||
|
"from os.path import expanduser, join, dirname\n",
|
||||||
|
"\n",
|
||||||
|
"def get_data():\n",
|
||||||
|
" # Burning man 2016 data\n",
|
||||||
|
" df = pd.read_csv(join(dirname(os.path.realpath(__file__)),\n",
|
||||||
|
" os.environ[\"AZUREML_DATAREFERENCE_workspacefilestore\"],\n",
|
||||||
|
" \"data.tsv\"), delimiter=\"\\t\", quotechar='\"')\n",
|
||||||
|
" # get integer labels\n",
|
||||||
|
" le = LabelEncoder()\n",
|
||||||
|
" le.fit(df[\"Label\"].values)\n",
|
||||||
|
" y = le.transform(df[\"Label\"].values)\n",
|
||||||
|
" X = df.drop([\"Label\"], axis=1)\n",
|
||||||
|
"\n",
|
||||||
|
" X_train, _, y_train, _ = train_test_split(X, y, test_size=0.1, random_state=42)\n",
|
||||||
|
"\n",
|
||||||
|
" return { \"X\" : X_train.values, \"y\" : y_train }"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Instantiate AutoML <a class=\"anchor\" id=\"Instatiate-AutoML-Remote-DSVM\"></a>\n",
|
||||||
|
"\n",
|
||||||
|
"You can specify automl_settings as **kwargs** as well. Also note that you can use the get_data() symantic for local excutions too. \n",
|
||||||
|
"\n",
|
||||||
|
"<i>Note: For Remote DSVM and Batch AI you cannot pass Numpy arrays directly to AutoMLConfig.</i>\n",
|
||||||
|
"\n",
|
||||||
|
"|Property|Description|\n",
|
||||||
|
"|-|-|\n",
|
||||||
|
"|**primary_metric**|This is the metric that you want to optimize.<br> Classification supports the following primary metrics <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
|
"|**max_time_sec**|Time limit in seconds for each iteration|\n",
|
||||||
|
"|**iterations**|Number of iterations. In each iteration Auto ML trains a specific pipeline with the data|\n",
|
||||||
|
"|**n_cross_validations**|Number of cross validation splits|\n",
|
||||||
|
"|**concurrent_iterations**|Max number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM\n",
|
||||||
|
"|**preprocess**| *True/False* <br>Setting this to *True* enables Auto ML to perform preprocessing <br>on the input to handle *missing data*, and perform some common *feature extraction*|\n",
|
||||||
|
"|**max_cores_per_iteration**| Indicates how many cores on the compute target would be used to train a single pipeline.<br> Default is *1*, you can set it to *-1* to use all cores|"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"automl_settings = {\n",
|
||||||
|
" \"max_time_sec\": 3600,\n",
|
||||||
|
" \"iterations\": 10,\n",
|
||||||
|
" \"n_cross_validations\": 5,\n",
|
||||||
|
" \"primary_metric\": 'AUC_weighted',\n",
|
||||||
|
" \"preprocess\": True,\n",
|
||||||
|
" \"max_cores_per_iteration\": 2,\n",
|
||||||
|
" \"verbosity\": logging.INFO\n",
|
||||||
|
"}\n",
|
||||||
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
|
" debug_log = 'automl_errors.log',\n",
|
||||||
|
" path=project_folder,\n",
|
||||||
|
" run_configuration=conda_run_config,\n",
|
||||||
|
" #compute_target = dsvm_compute,\n",
|
||||||
|
" data_script = project_folder + \"/get_data.py\",\n",
|
||||||
|
" **automl_settings\n",
|
||||||
|
" )"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Training the Models <a class=\"anchor\" id=\"Training-the-model-Remote-DSVM\"></a>\n",
|
||||||
|
"\n",
|
||||||
|
"For remote runs the execution is asynchronous, so you will see the iterations get populated as they complete. You can interact with the widgets/models even when the experiment is running to retreive the best model up to that point. Once you are satisfied with the model you can cancel a particular iteration or the whole run."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"remote_run = experiment.submit(automl_config, show_output=False)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Exploring the Results <a class=\"anchor\" id=\"Exploring-the-Results-Remote-DSVM\"></a>\n",
|
||||||
|
"#### Widget for monitoring runs\n",
|
||||||
|
"\n",
|
||||||
|
"The widget will sit on \"loading\" until the first iteration completed, then you will see an auto-updating graph and table show up. It refreshed once per minute, so you should see the graph update as child runs complete.\n",
|
||||||
|
"\n",
|
||||||
|
"You can click on a pipeline to see run properties and output logs. Logs are also available on the DSVM under /tmp/azureml_run/{iterationid}/azureml-logs\n",
|
||||||
|
"\n",
|
||||||
|
"NOTE: The widget displays a link at the bottom. This links to a web-ui to explore the individual run details."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
|
"RunDetails(remote_run).show() "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"\n",
|
||||||
|
"#### Retrieve All Child Runs\n",
|
||||||
|
"You can also use sdk methods to fetch all the child runs and see individual metrics that we log. "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"children = list(remote_run.get_children())\n",
|
||||||
|
"metricslist = {}\n",
|
||||||
|
"for run in children:\n",
|
||||||
|
" properties = run.get_properties()\n",
|
||||||
|
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)} \n",
|
||||||
|
" metricslist[int(properties['iteration'])] = metrics\n",
|
||||||
|
"\n",
|
||||||
|
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
||||||
|
"rundata"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Canceling Runs\n",
|
||||||
|
"You can cancel ongoing remote runs using the *cancel()* and *cancel_iteration()* functions"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Cancel the ongoing experiment and stop scheduling new iterations\n",
|
||||||
|
"remote_run.cancel()\n",
|
||||||
|
"\n",
|
||||||
|
"# Cancel iteration 1 and move onto iteration 2\n",
|
||||||
|
"# remote_run.cancel_iteration(1)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Retrieve the Best Model\n",
|
||||||
|
"\n",
|
||||||
|
"Below we select the best pipeline from our iterations. The *get_output* method returns the best run and the fitted model. There are overloads on *get_output* that allow you to retrieve the best run and fitted model for *any* logged metric or a particular *iteration*."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"best_run, fitted_model = remote_run.get_output()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Best Model based on any other metric"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# lookup_metric = \"accuracy\"\n",
|
||||||
|
"# best_run, fitted_model = remote_run.get_output(metric=lookup_metric)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Model from a specific iteration"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# iteration = 1\n",
|
||||||
|
"# best_run, fitted_model = remote_run.get_output(iteration=iteration)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Testing the Best Fitted Model <a class=\"anchor\" id=\"Testing-the-Fitted-Model-Remote-DSVM\"></a>\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import sklearn\n",
|
||||||
|
"from sklearn.model_selection import train_test_split\n",
|
||||||
|
"from sklearn.preprocessing import LabelEncoder\n",
|
||||||
|
"from pandas_ml import ConfusionMatrix\n",
|
||||||
|
"\n",
|
||||||
|
"df = pd.read_csv(\"https://automldemods.blob.core.windows.net/datasets/PlayaEvents2016,_1.6MB,_3.4k-rows.cleaned.2.tsv\",\n",
|
||||||
|
" delimiter=\"\\t\", quotechar='\"')\n",
|
||||||
|
"\n",
|
||||||
|
"# get integer labels\n",
|
||||||
|
"le = LabelEncoder()\n",
|
||||||
|
"le.fit(df[\"Label\"].values)\n",
|
||||||
|
"y = le.transform(df[\"Label\"].values)\n",
|
||||||
|
"X = df.drop([\"Label\"], axis=1)\n",
|
||||||
|
"\n",
|
||||||
|
"_, X_test, _, y_test = train_test_split(X, y, test_size=0.1, random_state=42)\n",
|
||||||
|
"\n",
|
||||||
|
"ypred = fitted_model.predict(X_test.values)\n",
|
||||||
|
"\n",
|
||||||
|
"ypred_strings = le.inverse_transform(ypred)\n",
|
||||||
|
"ytest_strings = le.inverse_transform(y_test)\n",
|
||||||
|
"\n",
|
||||||
|
"cm = ConfusionMatrix(ytest_strings, ypred_strings)\n",
|
||||||
|
"\n",
|
||||||
|
"print(cm)\n",
|
||||||
|
"\n",
|
||||||
|
"cm.plot()"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"authors": [
|
||||||
|
{
|
||||||
|
"name": "savitam"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python36"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.6"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -121,7 +121,7 @@
|
|||||||
"|-|-|\n",
|
"|-|-|\n",
|
||||||
"|**task**|classification or regression|\n",
|
"|**task**|classification or regression|\n",
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
"|**max_time_sec**|Time limit in seconds for each iteration.|\n",
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
||||||
@@ -143,7 +143,7 @@
|
|||||||
" name = experiment_name,\n",
|
" name = experiment_name,\n",
|
||||||
" debug_log = 'automl_errors.log',\n",
|
" debug_log = 'automl_errors.log',\n",
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
" iteration_timeout_minutes = 20,\n",
|
" max_time_sec = 1200,\n",
|
||||||
" iterations = 10,\n",
|
" iterations = 10,\n",
|
||||||
" n_cross_validations = 2,\n",
|
" n_cross_validations = 2,\n",
|
||||||
" verbosity = logging.INFO,\n",
|
" verbosity = logging.INFO,\n",
|
||||||
@@ -226,7 +226,6 @@
|
|||||||
"import pickle\n",
|
"import pickle\n",
|
||||||
"import json\n",
|
"import json\n",
|
||||||
"import numpy\n",
|
"import numpy\n",
|
||||||
"import azureml.train.automl\n",
|
|
||||||
"from sklearn.externals import joblib\n",
|
"from sklearn.externals import joblib\n",
|
||||||
"from azureml.core.model import Model\n",
|
"from azureml.core.model import Model\n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -299,12 +298,15 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies\n",
|
"%%writefile myenv.yml\n",
|
||||||
"\n",
|
"name: myenv\n",
|
||||||
"myenv = CondaDependencies.create(conda_packages=['numpy','scikit-learn'], pip_packages=['azureml-sdk[automl]'])\n",
|
"channels:\n",
|
||||||
"\n",
|
" - defaults\n",
|
||||||
"conda_env_file_name = 'myenv.yml'\n",
|
"dependencies:\n",
|
||||||
"myenv.save_to_file('.', conda_env_file_name)"
|
" - pip:\n",
|
||||||
|
" - numpy==1.14.2\n",
|
||||||
|
" - scikit-learn==0.19.2\n",
|
||||||
|
" - azureml-sdk[notebooks,automl]==<<azureml-version>>"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -314,14 +316,14 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# Substitute the actual version number in the environment file.\n",
|
"# Substitute the actual version number in the environment file.\n",
|
||||||
"# This is not strictly needed in this notebook because the model should have been generated using the current SDK version.\n",
|
"\n",
|
||||||
"# However, we include this in case this code is used on an experiment from a previous SDK version.\n",
|
"conda_env_file_name = 'myenv.yml'\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(conda_env_file_name, 'r') as cefr:\n",
|
"with open(conda_env_file_name, 'r') as cefr:\n",
|
||||||
" content = cefr.read()\n",
|
" content = cefr.read()\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(conda_env_file_name, 'w') as cefw:\n",
|
"with open(conda_env_file_name, 'w') as cefw:\n",
|
||||||
" cefw.write(content.replace(azureml.core.VERSION, dependencies['azureml-sdk']))\n",
|
" cefw.write(content.replace('<<azureml-version>>', dependencies['azureml-sdk']))\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Substitute the actual model id in the script file.\n",
|
"# Substitute the actual model id in the script file.\n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -361,10 +363,7 @@
|
|||||||
" image_config = image_config, \n",
|
" image_config = image_config, \n",
|
||||||
" workspace = ws)\n",
|
" workspace = ws)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"image.wait_for_creation(show_output = True)\n",
|
"image.wait_for_creation(show_output = True)"
|
||||||
"\n",
|
|
||||||
"if image.creation_state == 'Failed':\n",
|
|
||||||
" print(\"Image build log at: \" + image.image_build_log_uri)"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -128,7 +128,7 @@
|
|||||||
"automl_classifier = AutoMLConfig(task = 'classification',\n",
|
"automl_classifier = AutoMLConfig(task = 'classification',\n",
|
||||||
" debug_log = 'automl_errors.log',\n",
|
" debug_log = 'automl_errors.log',\n",
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
" iteration_timeout_minutes = 60,\n",
|
" max_time_sec = 3600,\n",
|
||||||
" iterations = 10,\n",
|
" iterations = 10,\n",
|
||||||
" n_cross_validations = 2,\n",
|
" n_cross_validations = 2,\n",
|
||||||
" verbosity = logging.INFO,\n",
|
" verbosity = logging.INFO,\n",
|
||||||
@@ -139,7 +139,7 @@
|
|||||||
"automl_sample_weight = AutoMLConfig(task = 'classification',\n",
|
"automl_sample_weight = AutoMLConfig(task = 'classification',\n",
|
||||||
" debug_log = 'automl_errors.log',\n",
|
" debug_log = 'automl_errors.log',\n",
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
" primary_metric = 'AUC_weighted',\n",
|
||||||
" iteration_timeout_minutes = 60,\n",
|
" max_time_sec = 3600,\n",
|
||||||
" iterations = 10,\n",
|
" iterations = 10,\n",
|
||||||
" n_cross_validations = 2,\n",
|
" n_cross_validations = 2,\n",
|
||||||
" verbosity = logging.INFO,\n",
|
" verbosity = logging.INFO,\n",
|
||||||
|
|||||||
@@ -40,7 +40,8 @@
|
|||||||
"from azureml.core.experiment import Experiment\n",
|
"from azureml.core.experiment import Experiment\n",
|
||||||
"from azureml.core.workspace import Workspace\n",
|
"from azureml.core.workspace import Workspace\n",
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
"from azureml.train.automl import AutoMLConfig\n",
|
||||||
"from azureml.train.automl.run import AutoMLRun\n"
|
"from azureml.train.automl.run import AutoMLRun\n",
|
||||||
|
"from azureml.train.automl.utilities import get_sdk_dependencies"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -62,6 +63,29 @@
|
|||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
"set_diagnostics_collection(send_diagnostics = True)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Retrieve the SDK versions in the current environment"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"To retrieve the SDK versions in the current environment, run `get_sdk_dependencies`."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"get_sdk_dependencies()"
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
|
|||||||
558
automl/13.auto-ml-dataprep.ipynb
Normal file
558
automl/13.auto-ml-dataprep.ipynb
Normal file
@@ -0,0 +1,558 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
||||||
|
"\n",
|
||||||
|
"Licensed under the MIT License."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# AutoML 13: Prepare Data using `azureml.dataprep`\n",
|
||||||
|
"In this example we showcase how you can use the `azureml.dataprep` SDK to load and prepare data for AutoML. `azureml.dataprep` can also be used standalone; full documentation can be found [here](https://github.com/Microsoft/PendletonDocs).\n",
|
||||||
|
"\n",
|
||||||
|
"Make sure you have executed the [setup](00.configuration.ipynb) before running this notebook.\n",
|
||||||
|
"\n",
|
||||||
|
"In this notebook you will learn how to:\n",
|
||||||
|
"1. Define data loading and preparation steps in a `Dataflow` using `azureml.dataprep`.\n",
|
||||||
|
"2. Pass the `Dataflow` to AutoML for a local run.\n",
|
||||||
|
"3. Pass the `Dataflow` to AutoML for a remote run."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Install `azureml.dataprep` SDK"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"!pip install azureml-dataprep"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Diagnostics\n",
|
||||||
|
"\n",
|
||||||
|
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.telemetry import set_diagnostics_collection\n",
|
||||||
|
"set_diagnostics_collection(send_diagnostics = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Create an Experiment\n",
|
||||||
|
"\n",
|
||||||
|
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import logging\n",
|
||||||
|
"import os\n",
|
||||||
|
"\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"from azureml.core.compute import DsvmCompute\n",
|
||||||
|
"from azureml.core.experiment import Experiment\n",
|
||||||
|
"from azureml.core.runconfig import CondaDependencies\n",
|
||||||
|
"from azureml.core.runconfig import RunConfiguration\n",
|
||||||
|
"from azureml.core.workspace import Workspace\n",
|
||||||
|
"import azureml.dataprep as dprep\n",
|
||||||
|
"from azureml.train.automl import AutoMLConfig"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"ws = Workspace.from_config()\n",
|
||||||
|
" \n",
|
||||||
|
"# choose a name for experiment\n",
|
||||||
|
"experiment_name = 'automl-dataprep-classification'\n",
|
||||||
|
"# project folder\n",
|
||||||
|
"project_folder = './sample_projects/automl-dataprep-classification'\n",
|
||||||
|
" \n",
|
||||||
|
"experiment = Experiment(ws, experiment_name)\n",
|
||||||
|
" \n",
|
||||||
|
"output = {}\n",
|
||||||
|
"output['SDK version'] = azureml.core.VERSION\n",
|
||||||
|
"output['Subscription ID'] = ws.subscription_id\n",
|
||||||
|
"output['Workspace Name'] = ws.name\n",
|
||||||
|
"output['Resource Group'] = ws.resource_group\n",
|
||||||
|
"output['Location'] = ws.location\n",
|
||||||
|
"output['Project Directory'] = project_folder\n",
|
||||||
|
"output['Experiment Name'] = experiment.name\n",
|
||||||
|
"pd.set_option('display.max_colwidth', -1)\n",
|
||||||
|
"pd.DataFrame(data = output, index = ['']).T"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Loading Data using DataPrep"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# You can use `smart_read_file` which intelligently figures out delimiters and datatypes of a file.\n",
|
||||||
|
"# The data referenced here was pulled from `sklearn.datasets.load_digits()`.\n",
|
||||||
|
"simple_example_data_root = 'https://dprepdata.blob.core.windows.net/automl-notebook-data/'\n",
|
||||||
|
"X = dprep.smart_read_file(simple_example_data_root + 'X.csv').skip(1) # Remove the header row.\n",
|
||||||
|
"\n",
|
||||||
|
"# You can also use `read_csv` and `to_*` transformations to read (with overridable delimiter)\n",
|
||||||
|
"# and convert column types manually.\n",
|
||||||
|
"# Here we read a comma delimited file and convert all columns to integers.\n",
|
||||||
|
"y = dprep.read_csv(simple_example_data_root + 'y.csv').to_long(dprep.ColumnSelector(term='.*', use_regex = True))"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Review the Data Preparation Result\n",
|
||||||
|
"\n",
|
||||||
|
"You can peek the result of a Dataflow at any range using `skip(i)` and `head(j)`. Doing so evaluates only `j` records for all the steps in the Dataflow, which makes it fast even against large datasets."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"X.skip(1).head(5)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Configure AutoML\n",
|
||||||
|
"\n",
|
||||||
|
"This creates a general AutoML settings object applicable for both local and remote runs."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"automl_settings = {\n",
|
||||||
|
" \"max_time_sec\" : 600,\n",
|
||||||
|
" \"iterations\" : 2,\n",
|
||||||
|
" \"primary_metric\" : 'AUC_weighted',\n",
|
||||||
|
" \"preprocess\" : False,\n",
|
||||||
|
" \"verbosity\" : logging.INFO,\n",
|
||||||
|
" \"n_cross_validations\": 3\n",
|
||||||
|
"}"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Local Run"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Pass Data with `Dataflow` Objects\n",
|
||||||
|
"\n",
|
||||||
|
"The `Dataflow` objects captured above can be passed to the `submit` method for a local run. AutoML will retrieve the results from the `Dataflow` for model training."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
|
" debug_log = 'automl_errors.log',\n",
|
||||||
|
" X = X,\n",
|
||||||
|
" y = y,\n",
|
||||||
|
" **automl_settings)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"local_run = experiment.submit(automl_config, show_output = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Remote Run"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Create or Attach a Remote Linux DSVM"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"dsvm_name = 'mydsvm'\n",
|
||||||
|
"try:\n",
|
||||||
|
" dsvm_compute = DsvmCompute(ws, dsvm_name)\n",
|
||||||
|
" print('Found existing DVSM.')\n",
|
||||||
|
"except:\n",
|
||||||
|
" print('Creating a new DSVM.')\n",
|
||||||
|
" dsvm_config = DsvmCompute.provisioning_configuration(vm_size = \"Standard_D2_v2\")\n",
|
||||||
|
" dsvm_compute = DsvmCompute.create(ws, name = dsvm_name, provisioning_configuration = dsvm_config)\n",
|
||||||
|
" dsvm_compute.wait_for_completion(show_output = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Update Conda Dependency file to have AutoML and DataPrep SDK\n",
|
||||||
|
"\n",
|
||||||
|
"Currently the AutoML and DataPrep SDKs are not installed with the Azure ML SDK by default. To circumvent this limitation, we update the conda dependency file to add these dependencies."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"cd = CondaDependencies()\n",
|
||||||
|
"cd.add_pip_package(pip_package='azureml-dataprep')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Create a `RunConfiguration` with DSVM name"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"run_config = RunConfiguration(conda_dependencies=cd)\n",
|
||||||
|
"run_config.target = dsvm_compute\n",
|
||||||
|
"run_config.auto_prepare_environment = True"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Pass Data with `Dataflow` Objects\n",
|
||||||
|
"\n",
|
||||||
|
"The `Dataflow` objects captured above can also be passed to the `submit` method for a remote run. AutoML will serialize the `Dataflow` object and send it to the remote compute target. The `Dataflow` will not be evaluated locally."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"automl_config = AutoMLConfig(task = 'classification',\n",
|
||||||
|
" debug_log = 'automl_errors.log',\n",
|
||||||
|
" path = project_folder,\n",
|
||||||
|
" run_configuration = run_config,\n",
|
||||||
|
" X = X,\n",
|
||||||
|
" y = y,\n",
|
||||||
|
" **automl_settings)\n",
|
||||||
|
"remote_run = experiment.submit(automl_config, show_output = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Explore the Results"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Widget for Monitoring Runs\n",
|
||||||
|
"\n",
|
||||||
|
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
||||||
|
"\n",
|
||||||
|
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
|
"RunDetails(local_run).show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Retrieve All Child Runs\n",
|
||||||
|
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"children = list(local_run.get_children())\n",
|
||||||
|
"metricslist = {}\n",
|
||||||
|
"for run in children:\n",
|
||||||
|
" properties = run.get_properties()\n",
|
||||||
|
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
||||||
|
" metricslist[int(properties['iteration'])] = metrics\n",
|
||||||
|
" \n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
||||||
|
"rundata"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Retrieve the Best Model\n",
|
||||||
|
"\n",
|
||||||
|
"Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"best_run, fitted_model = local_run.get_output()\n",
|
||||||
|
"print(best_run)\n",
|
||||||
|
"print(fitted_model)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Best Model Based on Any Other Metric\n",
|
||||||
|
"Show the run and the model that has the smallest `log_loss` value:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"lookup_metric = \"log_loss\"\n",
|
||||||
|
"best_run, fitted_model = local_run.get_output(metric = lookup_metric)\n",
|
||||||
|
"print(best_run)\n",
|
||||||
|
"print(fitted_model)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Model from a Specific Iteration\n",
|
||||||
|
"Show the run and the model from the first iteration:"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"iteration = 0\n",
|
||||||
|
"best_run, fitted_model = local_run.get_output(iteration = iteration)\n",
|
||||||
|
"print(best_run)\n",
|
||||||
|
"print(fitted_model)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Test the Best Fitted Model\n",
|
||||||
|
"\n",
|
||||||
|
"#### Load Test Data"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from sklearn import datasets\n",
|
||||||
|
"\n",
|
||||||
|
"digits = datasets.load_digits()\n",
|
||||||
|
"X_test = digits.data[:10, :]\n",
|
||||||
|
"y_test = digits.target[:10]\n",
|
||||||
|
"images = digits.images[:10]"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Testing Our Best Fitted Model\n",
|
||||||
|
"We will try to predict 2 digits and see how our model works."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"#Randomly select digits and test\n",
|
||||||
|
"from matplotlib import pyplot as plt\n",
|
||||||
|
"from matplotlib.pyplot import imshow\n",
|
||||||
|
"import random\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"\n",
|
||||||
|
"for index in np.random.choice(len(y_test), 2, replace = False):\n",
|
||||||
|
" print(index)\n",
|
||||||
|
" predicted = fitted_model.predict(X_test[index:index + 1])[0]\n",
|
||||||
|
" label = y_test[index]\n",
|
||||||
|
" title = \"Label value = %d Predicted value = %d \" % (label, predicted)\n",
|
||||||
|
" fig = plt.figure(1, figsize=(3,3))\n",
|
||||||
|
" ax1 = fig.add_axes((0,0,.8,.8))\n",
|
||||||
|
" ax1.set_title(title)\n",
|
||||||
|
" plt.imshow(images[index], cmap = plt.cm.gray_r, interpolation = 'nearest')\n",
|
||||||
|
" plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Appendix"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Capture the `Dataflow` Objects for Later Use in AutoML\n",
|
||||||
|
"\n",
|
||||||
|
"`Dataflow` objects are immutable and are composed of a list of data preparation steps. A `Dataflow` object can be branched at any point for further usage."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# sklearn.digits.data + target\n",
|
||||||
|
"digits_complete = dprep.smart_read_file('https://dprepdata.blob.core.windows.net/automl-notebook-data/digits-complete.csv')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"`digits_complete` (sourced from `sklearn.datasets.load_digits()`) is forked into `dflow_X` to capture all the feature columns and `dflow_y` to capture the label column."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"digits_complete.to_pandas_dataframe().shape\n",
|
||||||
|
"labels_column = 'Column64'\n",
|
||||||
|
"dflow_X = digits_complete.drop_columns(columns = [labels_column])\n",
|
||||||
|
"dflow_y = digits_complete.keep_columns(columns = [labels_column])"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"authors": [
|
||||||
|
{
|
||||||
|
"name": "savitam"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python36"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.5"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -1,446 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 13: Prepare Data using `azureml.dataprep` for Local Execution\n",
|
|
||||||
"In this example we showcase how you can use the `azureml.dataprep` SDK to load and prepare data for AutoML. `azureml.dataprep` can also be used standalone; full documentation can be found [here](https://github.com/Microsoft/PendletonDocs).\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [setup](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you will learn how to:\n",
|
|
||||||
"1. Define data loading and preparation steps in a `Dataflow` using `azureml.dataprep`.\n",
|
|
||||||
"2. Pass the `Dataflow` to AutoML for a local run.\n",
|
|
||||||
"3. Pass the `Dataflow` to AutoML for a remote run."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create an Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"import azureml.dataprep as dprep\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
" \n",
|
|
||||||
"# choose a name for experiment\n",
|
|
||||||
"experiment_name = 'automl-dataprep-local'\n",
|
|
||||||
"# project folder\n",
|
|
||||||
"project_folder = './sample_projects/automl-dataprep-local'\n",
|
|
||||||
" \n",
|
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
|
||||||
" \n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace Name'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data = output, index = ['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Loading Data using DataPrep"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# You can use `smart_read_file` which intelligently figures out delimiters and datatypes of a file.\n",
|
|
||||||
"# The data referenced here was pulled from `sklearn.datasets.load_digits()`.\n",
|
|
||||||
"simple_example_data_root = 'https://dprepdata.blob.core.windows.net/automl-notebook-data/'\n",
|
|
||||||
"X = dprep.smart_read_file(simple_example_data_root + 'X.csv').skip(1) # Remove the header row.\n",
|
|
||||||
"\n",
|
|
||||||
"# You can also use `read_csv` and `to_*` transformations to read (with overridable delimiter)\n",
|
|
||||||
"# and convert column types manually.\n",
|
|
||||||
"# Here we read a comma delimited file and convert all columns to integers.\n",
|
|
||||||
"y = dprep.read_csv(simple_example_data_root + 'y.csv').to_long(dprep.ColumnSelector(term='.*', use_regex = True))"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Review the Data Preparation Result\n",
|
|
||||||
"\n",
|
|
||||||
"You can peek the result of a Dataflow at any range using `skip(i)` and `head(j)`. Doing so evaluates only `j` records for all the steps in the Dataflow, which makes it fast even against large datasets."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"X.skip(1).head(5)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"This creates a general AutoML settings object applicable for both local and remote runs."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_settings = {\n",
|
|
||||||
" \"iteration_timeout_minutes\" : 10,\n",
|
|
||||||
" \"iterations\" : 2,\n",
|
|
||||||
" \"primary_metric\" : 'AUC_weighted',\n",
|
|
||||||
" \"preprocess\" : False,\n",
|
|
||||||
" \"verbosity\" : logging.INFO,\n",
|
|
||||||
" \"n_cross_validations\": 3\n",
|
|
||||||
"}"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Local Run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Pass Data with `Dataflow` Objects\n",
|
|
||||||
"\n",
|
|
||||||
"The `Dataflow` objects captured above can be passed to the `submit` method for a local run. AutoML will retrieve the results from the `Dataflow` for model training."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'automl_errors.log',\n",
|
|
||||||
" X = X,\n",
|
|
||||||
" y = y,\n",
|
|
||||||
" **automl_settings)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = experiment.submit(automl_config, show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Explore the Results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Widget for Monitoring Runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(local_run).show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(local_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
" \n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = local_run.get_output()\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model Based on Any Other Metric\n",
|
|
||||||
"Show the run and the model that has the smallest `log_loss` value:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"lookup_metric = \"log_loss\"\n",
|
|
||||||
"best_run, fitted_model = local_run.get_output(metric = lookup_metric)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Model from a Specific Iteration\n",
|
|
||||||
"Show the run and the model from the first iteration:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"iteration = 0\n",
|
|
||||||
"best_run, fitted_model = local_run.get_output(iteration = iteration)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Test the Best Fitted Model\n",
|
|
||||||
"\n",
|
|
||||||
"#### Load Test Data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"digits = datasets.load_digits()\n",
|
|
||||||
"X_test = digits.data[:10, :]\n",
|
|
||||||
"y_test = digits.target[:10]\n",
|
|
||||||
"images = digits.images[:10]"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Testing Our Best Fitted Model\n",
|
|
||||||
"We will try to predict 2 digits and see how our model works."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"#Randomly select digits and test\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import random\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"\n",
|
|
||||||
"for index in np.random.choice(len(y_test), 2, replace = False):\n",
|
|
||||||
" print(index)\n",
|
|
||||||
" predicted = fitted_model.predict(X_test[index:index + 1])[0]\n",
|
|
||||||
" label = y_test[index]\n",
|
|
||||||
" title = \"Label value = %d Predicted value = %d \" % (label, predicted)\n",
|
|
||||||
" fig = plt.figure(1, figsize=(3,3))\n",
|
|
||||||
" ax1 = fig.add_axes((0,0,.8,.8))\n",
|
|
||||||
" ax1.set_title(title)\n",
|
|
||||||
" plt.imshow(images[index], cmap = plt.cm.gray_r, interpolation = 'nearest')\n",
|
|
||||||
" plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Appendix"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Capture the `Dataflow` Objects for Later Use in AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"`Dataflow` objects are immutable and are composed of a list of data preparation steps. A `Dataflow` object can be branched at any point for further usage."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# sklearn.digits.data + target\n",
|
|
||||||
"digits_complete = dprep.smart_read_file('https://dprepdata.blob.core.windows.net/automl-notebook-data/digits-complete.csv')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"`digits_complete` (sourced from `sklearn.datasets.load_digits()`) is forked into `dflow_X` to capture all the feature columns and `dflow_y` to capture the label column."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"digits_complete.to_pandas_dataframe().shape\n",
|
|
||||||
"labels_column = 'Column64'\n",
|
|
||||||
"dflow_X = digits_complete.drop_columns(columns = [labels_column])\n",
|
|
||||||
"dflow_y = digits_complete.keep_columns(columns = [labels_column])"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "savitam"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.5"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -1,495 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 13: Prepare Data using `azureml.dataprep` for Remote Execution (DSVM)\n",
|
|
||||||
"In this example we showcase how you can use the `azureml.dataprep` SDK to load and prepare data for AutoML. `azureml.dataprep` can also be used standalone; full documentation can be found [here](https://github.com/Microsoft/PendletonDocs).\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [setup](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you will learn how to:\n",
|
|
||||||
"1. Define data loading and preparation steps in a `Dataflow` using `azureml.dataprep`.\n",
|
|
||||||
"2. Pass the `Dataflow` to AutoML for a local run.\n",
|
|
||||||
"3. Pass the `Dataflow` to AutoML for a remote run."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create an Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import time\n",
|
|
||||||
"\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.compute import DsvmCompute\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"import azureml.dataprep as dprep\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
" \n",
|
|
||||||
"# choose a name for experiment\n",
|
|
||||||
"experiment_name = 'automl-dataprep-remote-dsvm'\n",
|
|
||||||
"# project folder\n",
|
|
||||||
"project_folder = './sample_projects/automl-dataprep-remote-dsvm'\n",
|
|
||||||
" \n",
|
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
|
||||||
" \n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace Name'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data = output, index = ['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Loading Data using DataPrep"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# You can use `smart_read_file` which intelligently figures out delimiters and datatypes of a file.\n",
|
|
||||||
"# The data referenced here was pulled from `sklearn.datasets.load_digits()`.\n",
|
|
||||||
"simple_example_data_root = 'https://dprepdata.blob.core.windows.net/automl-notebook-data/'\n",
|
|
||||||
"X = dprep.smart_read_file(simple_example_data_root + 'X.csv').skip(1) # Remove the header row.\n",
|
|
||||||
"\n",
|
|
||||||
"# You can also use `read_csv` and `to_*` transformations to read (with overridable delimiter)\n",
|
|
||||||
"# and convert column types manually.\n",
|
|
||||||
"# Here we read a comma delimited file and convert all columns to integers.\n",
|
|
||||||
"y = dprep.read_csv(simple_example_data_root + 'y.csv').to_long(dprep.ColumnSelector(term='.*', use_regex = True))"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Review the Data Preparation Result\n",
|
|
||||||
"\n",
|
|
||||||
"You can peek the result of a Dataflow at any range using `skip(i)` and `head(j)`. Doing so evaluates only `j` records for all the steps in the Dataflow, which makes it fast even against large datasets."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"X.skip(1).head(5)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"This creates a general AutoML settings object applicable for both local and remote runs."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_settings = {\n",
|
|
||||||
" \"iteration_timeout_minutes\" : 10,\n",
|
|
||||||
" \"iterations\" : 2,\n",
|
|
||||||
" \"primary_metric\" : 'AUC_weighted',\n",
|
|
||||||
" \"preprocess\" : False,\n",
|
|
||||||
" \"verbosity\" : logging.INFO,\n",
|
|
||||||
" \"n_cross_validations\": 3\n",
|
|
||||||
"}"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Remote Run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Create or Attach a Remote Linux DSVM"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"dsvm_name = 'mydsvmd'\n",
|
|
||||||
"\n",
|
|
||||||
"try:\n",
|
|
||||||
" while ws.compute_targets[dsvm_name].provisioning_state == 'Creating':\n",
|
|
||||||
" time.sleep(1)\n",
|
|
||||||
" \n",
|
|
||||||
" dsvm_compute = DsvmCompute(ws, dsvm_name)\n",
|
|
||||||
" print('Found existing DVSM.')\n",
|
|
||||||
"except:\n",
|
|
||||||
" print('Creating a new DSVM.')\n",
|
|
||||||
" dsvm_config = DsvmCompute.provisioning_configuration(vm_size = \"Standard_D2_v2\")\n",
|
|
||||||
" dsvm_compute = DsvmCompute.create(ws, name = dsvm_name, provisioning_configuration = dsvm_config)\n",
|
|
||||||
" dsvm_compute.wait_for_completion(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.runconfig import RunConfiguration\n",
|
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies\n",
|
|
||||||
"\n",
|
|
||||||
"conda_run_config = RunConfiguration(framework=\"python\")\n",
|
|
||||||
"\n",
|
|
||||||
"conda_run_config.target = dsvm_compute\n",
|
|
||||||
"\n",
|
|
||||||
"cd = CondaDependencies.create(pip_packages=['azureml-sdk[automl]'], conda_packages=['numpy'])\n",
|
|
||||||
"conda_run_config.environment.python.conda_dependencies = cd"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Pass Data with `Dataflow` Objects\n",
|
|
||||||
"\n",
|
|
||||||
"The `Dataflow` objects captured above can also be passed to the `submit` method for a remote run. AutoML will serialize the `Dataflow` object and send it to the remote compute target. The `Dataflow` will not be evaluated locally."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'automl_errors.log',\n",
|
|
||||||
" path = project_folder,\n",
|
|
||||||
" run_configuration=conda_run_config,\n",
|
|
||||||
" X = X,\n",
|
|
||||||
" y = y,\n",
|
|
||||||
" **automl_settings)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"remote_run = experiment.submit(automl_config, show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Explore the Results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Widget for Monitoring Runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(remote_run).show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(remote_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
" \n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The `get_output` method returns the best run and the fitted model. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = remote_run.get_output()\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model Based on Any Other Metric\n",
|
|
||||||
"Show the run and the model that has the smallest `log_loss` value:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"lookup_metric = \"log_loss\"\n",
|
|
||||||
"best_run, fitted_model = remote_run.get_output(metric = lookup_metric)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Model from a Specific Iteration\n",
|
|
||||||
"Show the run and the model from the first iteration:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"iteration = 0\n",
|
|
||||||
"best_run, fitted_model = remote_run.get_output(iteration = iteration)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Test the Best Fitted Model\n",
|
|
||||||
"\n",
|
|
||||||
"#### Load Test Data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"digits = datasets.load_digits()\n",
|
|
||||||
"X_test = digits.data[:10, :]\n",
|
|
||||||
"y_test = digits.target[:10]\n",
|
|
||||||
"images = digits.images[:10]"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Testing Our Best Fitted Model\n",
|
|
||||||
"We will try to predict 2 digits and see how our model works."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"#Randomly select digits and test\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import random\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"\n",
|
|
||||||
"for index in np.random.choice(len(y_test), 2, replace = False):\n",
|
|
||||||
" print(index)\n",
|
|
||||||
" predicted = fitted_model.predict(X_test[index:index + 1])[0]\n",
|
|
||||||
" label = y_test[index]\n",
|
|
||||||
" title = \"Label value = %d Predicted value = %d \" % (label, predicted)\n",
|
|
||||||
" fig = plt.figure(1, figsize=(3,3))\n",
|
|
||||||
" ax1 = fig.add_axes((0,0,.8,.8))\n",
|
|
||||||
" ax1.set_title(title)\n",
|
|
||||||
" plt.imshow(images[index], cmap = plt.cm.gray_r, interpolation = 'nearest')\n",
|
|
||||||
" plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Appendix"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Capture the `Dataflow` Objects for Later Use in AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"`Dataflow` objects are immutable and are composed of a list of data preparation steps. A `Dataflow` object can be branched at any point for further usage."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# sklearn.digits.data + target\n",
|
|
||||||
"digits_complete = dprep.smart_read_file('https://dprepdata.blob.core.windows.net/automl-notebook-data/digits-complete.csv')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"`digits_complete` (sourced from `sklearn.datasets.load_digits()`) is forked into `dflow_X` to capture all the feature columns and `dflow_y` to capture the label column."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"digits_complete.to_pandas_dataframe().shape\n",
|
|
||||||
"labels_column = 'Column64'\n",
|
|
||||||
"dflow_X = digits_complete.drop_columns(columns = [labels_column])\n",
|
|
||||||
"dflow_y = digits_complete.keep_columns(columns = [labels_column])"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "savitam"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.5"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -1,374 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 14: Explain classification model and visualize the explanation\n",
|
|
||||||
"\n",
|
|
||||||
"In this example we use the sklearn's [iris dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html) to showcase how you can use the AutoML Classifier for a simple classification problem.\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you would see\n",
|
|
||||||
"1. Creating an Experiment in an existing Workspace\n",
|
|
||||||
"2. Instantiating AutoMLConfig\n",
|
|
||||||
"3. Training the Model using local compute and explain the model\n",
|
|
||||||
"4. Visualization model's feature importance in widget\n",
|
|
||||||
"5. Explore best model's explanation\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Install AzureML Explainer SDK "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"!pip install azureml_sdk[explain]"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created a <b>Workspace</b>. For AutoML you would need to create an <b>Experiment</b>. An <b>Experiment</b> is a named object in a <b>Workspace</b>, which is used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import random\n",
|
|
||||||
"\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
|
||||||
"from azureml.train.automl.run import AutoMLRun"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"\n",
|
|
||||||
"# choose a name for experiment\n",
|
|
||||||
"experiment_name = 'automl-local-classification'\n",
|
|
||||||
"# project folder\n",
|
|
||||||
"project_folder = './sample_projects/automl-local-classification-model-explanation'\n",
|
|
||||||
"\n",
|
|
||||||
"experiment=Experiment(ws, experiment_name)\n",
|
|
||||||
"\n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace Name'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data = output, index = ['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Load Iris Data Set"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"iris = datasets.load_iris()\n",
|
|
||||||
"y = iris.target\n",
|
|
||||||
"X = iris.data\n",
|
|
||||||
"\n",
|
|
||||||
"features = iris.feature_names\n",
|
|
||||||
"\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"X_train, X_test, y_train, y_test = train_test_split(X,\n",
|
|
||||||
" y,\n",
|
|
||||||
" test_size=0.1,\n",
|
|
||||||
" random_state=100,\n",
|
|
||||||
" stratify=y)\n",
|
|
||||||
"\n",
|
|
||||||
"X_train = pd.DataFrame(X_train, columns=features)\n",
|
|
||||||
"X_test = pd.DataFrame(X_test, columns=features)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Instantiate Auto ML Config\n",
|
|
||||||
"\n",
|
|
||||||
"Instantiate a AutoMLConfig object. This defines the settings and data used to run the experiment.\n",
|
|
||||||
"\n",
|
|
||||||
"|Property|Description|\n",
|
|
||||||
"|-|-|\n",
|
|
||||||
"|**task**|classification or regression|\n",
|
|
||||||
"|**primary_metric**|This is the metric that you want to optimize.<br> Classification supports the following primary metrics <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
|
||||||
"|**max_time_sec**|Time limit in minutes for each iterations|\n",
|
|
||||||
"|**iterations**|Number of iterations. In each iteration Auto ML trains the data with a specific pipeline|\n",
|
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
|
||||||
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers. |\n",
|
|
||||||
"|**X_valid**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
|
||||||
"|**y_valid**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]|\n",
|
|
||||||
"|**model_explainability**|Indicate to explain each trained pipeline or not |\n",
|
|
||||||
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder. |"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'automl_errors.log',\n",
|
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
|
||||||
" max_time_sec = 12000,\n",
|
|
||||||
" iterations = 10,\n",
|
|
||||||
" verbosity = logging.INFO,\n",
|
|
||||||
" X = X_train, \n",
|
|
||||||
" y = y_train,\n",
|
|
||||||
" X_valid = X_test,\n",
|
|
||||||
" y_valid = y_test,\n",
|
|
||||||
" model_explainability=True,\n",
|
|
||||||
" path=project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Training the Model\n",
|
|
||||||
"\n",
|
|
||||||
"You can call the submit method on the experiment object and pass the run configuration. For Local runs the execution is synchronous. Depending on the data and number of iterations this can run for while.\n",
|
|
||||||
"You will see the currently running iterations printing to the console."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = experiment.submit(automl_config, show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Exploring the results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Widget for monitoring runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will sit on \"loading\" until the first iteration completed, then you will see an auto-updating graph and table show up. It refreshed once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"NOTE: The widget displays a link at the bottom. This links to a web-ui to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(local_run).show() "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"child_run = next(local_run.get_children())\n",
|
|
||||||
"RunDetails(child_run).show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The *get_output* method on automl_classifier returns the best run and the fitted model for the last *fit* invocation. There are overloads on *get_output* that allow you to retrieve the best run and fitted model for *any* logged metric or a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = local_run.get_output()\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Best Model 's explanation\n",
|
|
||||||
"\n",
|
|
||||||
"Retrieve the explanation from the best_run. And explanation information includes:\n",
|
|
||||||
"\n",
|
|
||||||
"1.\tshap_values: The explanation information generated by shap lib\n",
|
|
||||||
"2.\texpected_values: The expected value of the model applied to set of X_train data.\n",
|
|
||||||
"3.\toverall_summary: The model level feature importance values sorted in descending order\n",
|
|
||||||
"4.\toverall_imp: The feature names sorted in the same order as in overall_summary\n",
|
|
||||||
"5.\tper_class_summary: The class level feature importance values sorted in descending order. Only available for the classification case\n",
|
|
||||||
"6.\tper_class_imp: The feature names sorted in the same order as in per_class_summary. Only available for the classification case"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.train.automl.automlexplainer import retrieve_model_explanation\n",
|
|
||||||
"\n",
|
|
||||||
"shap_values, expected_values, overall_summary, overall_imp, per_class_summary, per_class_imp = \\\n",
|
|
||||||
" retrieve_model_explanation(best_run)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(overall_summary)\n",
|
|
||||||
"print(overall_imp)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(per_class_summary)\n",
|
|
||||||
"print(per_class_imp)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Beside retrieve the existed model explanation information, explain the model with different train/test data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.train.automl.automlexplainer import explain_model\n",
|
|
||||||
"\n",
|
|
||||||
"shap_values, expected_values, overall_summary, overall_imp, per_class_summary, per_class_imp = \\\n",
|
|
||||||
" explain_model(fitted_model, X_train, X_test)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(overall_summary)\n",
|
|
||||||
"print(overall_imp)"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "xif"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -1,423 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 15a: Classification with ensembling on local compute\n",
|
|
||||||
"\n",
|
|
||||||
"In this example we use the scikit-learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html) to showcase how you can use AutoML for a simple classification problem.\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you will learn how to:\n",
|
|
||||||
"1. Create an `Experiment` in an existing `Workspace`.\n",
|
|
||||||
"2. Configure AutoML using `AutoMLConfig` which enables an extra ensembling iteration.\n",
|
|
||||||
"3. Train the model using local compute.\n",
|
|
||||||
"4. Explore the results.\n",
|
|
||||||
"5. Test the best fitted model.\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create an Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import random\n",
|
|
||||||
"\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
|
||||||
"from azureml.train.automl.run import AutoMLRun"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"\n",
|
|
||||||
"# Choose a name for the experiment and specify the project folder.\n",
|
|
||||||
"experiment_name = 'automl-local-classification'\n",
|
|
||||||
"project_folder = './sample_projects/automl-local-classification'\n",
|
|
||||||
"\n",
|
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
|
||||||
"\n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace Name'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data = output, index = ['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Load Training Data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"digits = datasets.load_digits()\n",
|
|
||||||
"\n",
|
|
||||||
"# Exclude the first 50 rows from training so that they can be used for test.\n",
|
|
||||||
"X_train = digits.data[150:,:]\n",
|
|
||||||
"y_train = digits.target[150:]\n",
|
|
||||||
"X_valid = digits.data[50:150]\n",
|
|
||||||
"y_valid = digits.target[50:150]"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment.\n",
|
|
||||||
"\n",
|
|
||||||
"|Property|Description|\n",
|
|
||||||
"|-|-|\n",
|
|
||||||
"|**task**|classification or regression|\n",
|
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i>|\n",
|
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
|
||||||
"|**n_cross_validations**|Number of cross validation splits.|\n",
|
|
||||||
"|**X**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
|
||||||
"|**y**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
|
||||||
"|**X_valid**|(sparse) array-like, shape = [n_samples, n_features]|\n",
|
|
||||||
"|**y_valid**|(sparse) array-like, shape = [n_samples, ], [n_samples, n_classes]<br>Multi-class targets. An indicator matrix turns on multilabel classification. This should be an array of integers.|\n",
|
|
||||||
"|**enable_ensembling**|Flag to enable an ensembling iteration after all the other iterations complete.|\n",
|
|
||||||
"|**ensemble_iterations**|Number of iterations during which we choose a fitted pipeline to be part of the final ensemble.|\n",
|
|
||||||
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'classification',\n",
|
|
||||||
" debug_log = 'classification.log',\n",
|
|
||||||
" primary_metric = 'AUC_weighted',\n",
|
|
||||||
" iteration_timeout_minutes = 60,\n",
|
|
||||||
" iterations = 10,\n",
|
|
||||||
" verbosity = logging.INFO,\n",
|
|
||||||
" X = X_train, \n",
|
|
||||||
" y = y_train,\n",
|
|
||||||
" X_valid = X_valid,\n",
|
|
||||||
" y_valid = y_valid,\n",
|
|
||||||
" enable_ensembling = True,\n",
|
|
||||||
" ensemble_iterations = 5,\n",
|
|
||||||
" path = project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Train the Model\n",
|
|
||||||
"\n",
|
|
||||||
"Call the `submit` method on the experiment object and pass the run configuration. Execution of local runs is synchronous. Depending on the data and the number of iterations this can run for a while.\n",
|
|
||||||
"In this example, we specify `show_output = True` to print currently running iterations to the console."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = experiment.submit(automl_config, show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Optionally, you can continue an interrupted local run by calling `continue_experiment` without the `iterations` parameter, or run more iterations for a completed run by specifying the `iterations` parameter:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = local_run.continue_experiment(X = X_train, \n",
|
|
||||||
" y = y_train,\n",
|
|
||||||
" X_valid = X_valid,\n",
|
|
||||||
" y_valid = y_valid,\n",
|
|
||||||
" show_output = True,\n",
|
|
||||||
" iterations = 5)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Explore the Results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Widget for Monitoring Runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(local_run).show() "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"\n",
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(local_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
"\n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The `get_output` method on `automl_classifier` returns the best run and the fitted model for the last invocation. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = local_run.get_output()\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model Based on Any Other Metric\n",
|
|
||||||
"Show the run and the model that has the smallest `log_loss` value:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"lookup_metric = \"log_loss\"\n",
|
|
||||||
"best_run, fitted_model = local_run.get_output(metric = lookup_metric)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Model from a Specific Iteration\n",
|
|
||||||
"Show the run and the model from the third iteration:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"iteration = 3\n",
|
|
||||||
"third_run, third_model = local_run.get_output(iteration = iteration)\n",
|
|
||||||
"print(third_run)\n",
|
|
||||||
"print(third_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Test the Best Fitted Model\n",
|
|
||||||
"\n",
|
|
||||||
"#### Load Test Data"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"digits = datasets.load_digits()\n",
|
|
||||||
"X_test = digits.data[:10, :]\n",
|
|
||||||
"y_test = digits.target[:10]\n",
|
|
||||||
"images = digits.images[:10]"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Testing Our Best Pipeline\n",
|
|
||||||
"We will try to predict 2 digits and see how our model works."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Randomly select digits and test.\n",
|
|
||||||
"for index in np.random.choice(len(y_test), 2, replace = False):\n",
|
|
||||||
" print(index)\n",
|
|
||||||
" predicted = fitted_model.predict(X_test[index:index + 1])[0]\n",
|
|
||||||
" label = y_test[index]\n",
|
|
||||||
" title = \"Label value = %d Predicted value = %d \" % (label, predicted)\n",
|
|
||||||
" fig = plt.figure(1, figsize = (3,3))\n",
|
|
||||||
" ax1 = fig.add_axes((0,0,.8,.8))\n",
|
|
||||||
" ax1.set_title(title)\n",
|
|
||||||
" plt.imshow(images[index], cmap = plt.cm.gray_r, interpolation = 'nearest')\n",
|
|
||||||
" plt.show()"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "ratanase"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python [default]",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -1,449 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved.\n",
|
|
||||||
"\n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# AutoML 15b: Regression with ensembling on remote compute\n",
|
|
||||||
"\n",
|
|
||||||
"In this example we use the scikit-learn's [diabetes dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html) to showcase how you can use AutoML for a simple regression problem.\n",
|
|
||||||
"\n",
|
|
||||||
"Make sure you have executed the [00.configuration](00.configuration.ipynb) before running this notebook.\n",
|
|
||||||
"\n",
|
|
||||||
"In this notebook you will learn how to:\n",
|
|
||||||
"1. Create an `Experiment` in an existing `Workspace`.\n",
|
|
||||||
"2. Configure AutoML using `AutoMLConfig`which enables an extra ensembling iteration.\n",
|
|
||||||
"3. Train the model using remote compute.\n",
|
|
||||||
"4. Explore the results.\n",
|
|
||||||
"5. Test the best fitted model.\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create an Experiment\n",
|
|
||||||
"\n",
|
|
||||||
"As part of the setup you have already created an Azure ML `Workspace` object. For AutoML you will need to create an `Experiment` object, which is a named object in a `Workspace` used to run experiments."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import logging\n",
|
|
||||||
"import os\n",
|
|
||||||
"import random\n",
|
|
||||||
"\n",
|
|
||||||
"from matplotlib import pyplot as plt\n",
|
|
||||||
"from matplotlib.pyplot import imshow\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import pandas as pd\n",
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"from azureml.core.experiment import Experiment\n",
|
|
||||||
"from azureml.core.workspace import Workspace\n",
|
|
||||||
"from azureml.train.automl import AutoMLConfig\n",
|
|
||||||
"from azureml.train.automl.run import AutoMLRun"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"\n",
|
|
||||||
"# Choose a name for the experiment and specify the project folder.\n",
|
|
||||||
"experiment_name = 'automl-local-regression'\n",
|
|
||||||
"project_folder = './sample_projects/automl-local-regression'\n",
|
|
||||||
"\n",
|
|
||||||
"experiment = Experiment(ws, experiment_name)\n",
|
|
||||||
"\n",
|
|
||||||
"output = {}\n",
|
|
||||||
"output['SDK version'] = azureml.core.VERSION\n",
|
|
||||||
"output['Subscription ID'] = ws.subscription_id\n",
|
|
||||||
"output['Workspace Name'] = ws.name\n",
|
|
||||||
"output['Resource Group'] = ws.resource_group\n",
|
|
||||||
"output['Location'] = ws.location\n",
|
|
||||||
"output['Project Directory'] = project_folder\n",
|
|
||||||
"output['Experiment Name'] = experiment.name\n",
|
|
||||||
"pd.set_option('display.max_colwidth', -1)\n",
|
|
||||||
"pd.DataFrame(data = output, index = ['']).T"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Diagnostics\n",
|
|
||||||
"\n",
|
|
||||||
"Opt-in diagnostics for better experience, quality, and security of future releases."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.telemetry import set_diagnostics_collection\n",
|
|
||||||
"set_diagnostics_collection(send_diagnostics = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create a Remote Linux DSVM\n",
|
|
||||||
"**Note:** If creation fails with a message about Marketplace purchase eligibilty, start creation of a DSVM through the [Azure portal](https://portal.azure.com), and select \"Want to create programmatically\" to enable programmatic creation. Once you've enabled this setting, you can exit the portal without actually creating the DSVM, and creation of the DSVM through the notebook should work."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.compute import DsvmCompute\n",
|
|
||||||
"\n",
|
|
||||||
"dsvm_name = 'mydsvm'\n",
|
|
||||||
"try:\n",
|
|
||||||
" dsvm_compute = DsvmCompute(ws, dsvm_name)\n",
|
|
||||||
" print('Found an existing DSVM.')\n",
|
|
||||||
"except:\n",
|
|
||||||
" print('Creating a new DSVM.')\n",
|
|
||||||
" dsvm_config = DsvmCompute.provisioning_configuration(vm_size = \"Standard_D2_v2\")\n",
|
|
||||||
" dsvm_compute = DsvmCompute.create(ws, name = dsvm_name, provisioning_configuration = dsvm_config)\n",
|
|
||||||
" dsvm_compute.wait_for_completion(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Create Get Data File\n",
|
|
||||||
"For remote executions you should author a `get_data.py` file containing a `get_data()` function. This file should be in the root directory of the project. You can encapsulate code to read data either from a blob storage or local disk in this file.\n",
|
|
||||||
"In this example, the `get_data()` function returns data using scikit-learn's `diabetes` dataset."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if not os.path.exists(project_folder):\n",
|
|
||||||
" os.makedirs(project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%%writefile $project_folder/get_data.py\n",
|
|
||||||
"\n",
|
|
||||||
"# Load the diabetes dataset, a well-known built-in small dataset that comes with scikit-learn.\n",
|
|
||||||
"from sklearn.datasets import load_diabetes\n",
|
|
||||||
"from sklearn.linear_model import Ridge\n",
|
|
||||||
"from sklearn.metrics import mean_squared_error\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"\n",
|
|
||||||
"def get_data():\n",
|
|
||||||
" X, y = load_diabetes(return_X_y = True)\n",
|
|
||||||
"\n",
|
|
||||||
" columns = ['age', 'gender', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']\n",
|
|
||||||
"\n",
|
|
||||||
" X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size = 0.2, random_state = 0)\n",
|
|
||||||
" X_valid, X_test, y_valid, y_test = train_test_split(X_temp, y_temp, test_size = 0.5, random_state = 0)\n",
|
|
||||||
" return { \"X\" : X_train, \"y\" : y_train, \"X_valid\": X_valid, \"y_valid\": y_valid }"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Configure AutoML\n",
|
|
||||||
"\n",
|
|
||||||
"Instantiate an `AutoMLConfig` object to specify the settings and data used to run the experiment.\n",
|
|
||||||
"\n",
|
|
||||||
"|Property|Description|\n",
|
|
||||||
"|-|-|\n",
|
|
||||||
"|**task**|classification or regression|\n",
|
|
||||||
"|**primary_metric**|This is the metric that you want to optimize. Regression supports the following primary metrics: <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>|\n",
|
|
||||||
"|**iteration_timeout_minutes**|Time limit in minutes for each iteration.|\n",
|
|
||||||
"|**iterations**|Number of iterations. In each iteration AutoML trains a specific pipeline with the data.|\n",
|
|
||||||
"|**enable_ensembling**|Flag to enable an ensembling iteration after all the other iterations complete.|\n",
|
|
||||||
"|**ensemble_iterations**|Number of iterations during which we choose a fitted pipeline to be part of the final ensemble.|\n",
|
|
||||||
"|**path**|Relative path to the project folder. AutoML stores configuration files for the experiment under this folder. You can specify a new empty folder.|"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"automl_config = AutoMLConfig(task = 'regression',\n",
|
|
||||||
" iteration_timeout_minutes = 10,\n",
|
|
||||||
" iterations = 20,\n",
|
|
||||||
" primary_metric = 'spearman_correlation',\n",
|
|
||||||
" debug_log = 'regression.log',\n",
|
|
||||||
" verbosity = logging.INFO,\n",
|
|
||||||
" compute_target = dsvm_compute,\n",
|
|
||||||
" data_script = project_folder + \"/get_data.py\",\n",
|
|
||||||
" enable_ensembling = True,\n",
|
|
||||||
" ensemble_iterations = 5,\n",
|
|
||||||
" path = project_folder)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Train the Model\n",
|
|
||||||
"\n",
|
|
||||||
"Call the `submit` method on the experiment object and pass the run configuration. Execution of local runs is synchronous. Depending on the data and the number of iterations this can run for a while.\n",
|
|
||||||
"In this example, we specify `show_output = True` to print currently running iterations to the console."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run = experiment.submit(automl_config, show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"local_run"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Explore the Results"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Widget for Monitoring Runs\n",
|
|
||||||
"\n",
|
|
||||||
"The widget will first report a \"loading\" status while running the first iteration. After completing the first iteration, an auto-updating graph and table will be shown. The widget will refresh once per minute, so you should see the graph update as child runs complete.\n",
|
|
||||||
"\n",
|
|
||||||
"**Note:** The widget displays a link at the bottom. Use this link to open a web interface to explore the individual run details."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.widgets import RunDetails\n",
|
|
||||||
"RunDetails(local_run).show() "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"\n",
|
|
||||||
"#### Retrieve All Child Runs\n",
|
|
||||||
"You can also use SDK methods to fetch all the child runs and see individual metrics that we log."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"children = list(local_run.get_children())\n",
|
|
||||||
"metricslist = {}\n",
|
|
||||||
"for run in children:\n",
|
|
||||||
" properties = run.get_properties()\n",
|
|
||||||
" metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}\n",
|
|
||||||
" metricslist[int(properties['iteration'])] = metrics\n",
|
|
||||||
"\n",
|
|
||||||
"rundata = pd.DataFrame(metricslist).sort_index(1)\n",
|
|
||||||
"rundata"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Retrieve the Best Model\n",
|
|
||||||
"\n",
|
|
||||||
"Below we select the best pipeline from our iterations. The `get_output` method on `automl_classifier` returns the best run and the fitted model for the last invocation. Overloads on `get_output` allow you to retrieve the best run and fitted model for *any* logged metric or for a particular *iteration*."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"best_run, fitted_model = local_run.get_output()\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Best Model Based on Any Other Metric\n",
|
|
||||||
"Show the run and the model that has the smallest `root_mean_squared_error` value."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"lookup_metric = \"root_mean_squared_error\"\n",
|
|
||||||
"best_run, fitted_model = local_run.get_output(metric = lookup_metric)\n",
|
|
||||||
"print(best_run)\n",
|
|
||||||
"print(fitted_model)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Test the Best Model (Ensemble)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Predict on training and test set, and calculate residual values."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from sklearn.datasets import load_diabetes\n",
|
|
||||||
"from sklearn.linear_model import Ridge\n",
|
|
||||||
"from sklearn.metrics import mean_squared_error\n",
|
|
||||||
"from sklearn.model_selection import train_test_split\n",
|
|
||||||
"\n",
|
|
||||||
"X, y = load_diabetes(return_X_y = True)\n",
|
|
||||||
"\n",
|
|
||||||
"X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size = 0.2, random_state = 0)\n",
|
|
||||||
"X_valid, X_test, y_valid, y_test = train_test_split(X_temp, y_temp, test_size = 0.5, random_state = 0)\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"y_pred_train = fitted_model.predict(X_train)\n",
|
|
||||||
"y_residual_train = y_train - y_pred_train\n",
|
|
||||||
"\n",
|
|
||||||
"y_pred_test = fitted_model.predict(X_test)\n",
|
|
||||||
"y_residual_test = y_test - y_pred_test"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%matplotlib inline\n",
|
|
||||||
"import matplotlib.pyplot as plt\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"from sklearn import datasets\n",
|
|
||||||
"from sklearn.metrics import mean_squared_error, r2_score\n",
|
|
||||||
"\n",
|
|
||||||
"# Set up a multi-plot chart.\n",
|
|
||||||
"f, (a0, a1) = plt.subplots(1, 2, gridspec_kw = {'width_ratios':[1, 1], 'wspace':0, 'hspace': 0})\n",
|
|
||||||
"f.suptitle('Regression Residual Values', fontsize = 18)\n",
|
|
||||||
"f.set_figheight(6)\n",
|
|
||||||
"f.set_figwidth(16)\n",
|
|
||||||
"\n",
|
|
||||||
"# Plot residual values of training set.\n",
|
|
||||||
"a0.axis([0, 360, -200, 200])\n",
|
|
||||||
"a0.plot(y_residual_train, 'bo', alpha = 0.5)\n",
|
|
||||||
"a0.plot([-10,360],[0,0], 'r-', lw = 3)\n",
|
|
||||||
"a0.text(16,170,'RMSE = {0:.2f}'.format(np.sqrt(mean_squared_error(y_train, y_pred_train))), fontsize = 12)\n",
|
|
||||||
"a0.text(16,140,'R2 score = {0:.2f}'.format(r2_score(y_train, y_pred_train)), fontsize = 12)\n",
|
|
||||||
"a0.set_xlabel('Training samples', fontsize = 12)\n",
|
|
||||||
"a0.set_ylabel('Residual Values', fontsize = 12)\n",
|
|
||||||
"\n",
|
|
||||||
"# Plot a histogram.\n",
|
|
||||||
"a0.hist(y_residual_train, orientation = 'horizontal', color = 'b', bins = 10, histtype = 'step');\n",
|
|
||||||
"a0.hist(y_residual_train, orientation = 'horizontal', color = 'b', alpha = 0.2, bins = 10);\n",
|
|
||||||
"\n",
|
|
||||||
"# Plot residual values of test set.\n",
|
|
||||||
"a1.axis([0, 90, -200, 200])\n",
|
|
||||||
"a1.plot(y_residual_test, 'bo', alpha = 0.5)\n",
|
|
||||||
"a1.plot([-10,360],[0,0], 'r-', lw = 3)\n",
|
|
||||||
"a1.text(5,170,'RMSE = {0:.2f}'.format(np.sqrt(mean_squared_error(y_test, y_pred_test))), fontsize = 12)\n",
|
|
||||||
"a1.text(5,140,'R2 score = {0:.2f}'.format(r2_score(y_test, y_pred_test)), fontsize = 12)\n",
|
|
||||||
"a1.set_xlabel('Test samples', fontsize = 12)\n",
|
|
||||||
"a1.set_yticklabels([])\n",
|
|
||||||
"\n",
|
|
||||||
"# Plot a histogram.\n",
|
|
||||||
"a1.hist(y_residual_test, orientation = 'horizontal', color = 'b', bins = 10, histtype = 'step')\n",
|
|
||||||
"a1.hist(y_residual_test, orientation = 'horizontal', color = 'b', alpha = 0.2, bins = 10)\n",
|
|
||||||
"\n",
|
|
||||||
"plt.show()"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "ratanase"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python [default]",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
172
automl/README.md
172
automl/README.md
@@ -1,52 +1,24 @@
|
|||||||
# Table of Contents
|
# Table of Contents
|
||||||
1. [Automated ML Introduction](#introduction)
|
1. [Auto ML Introduction](#introduction)
|
||||||
1. [Running samples in Azure Notebooks](#jupyter)
|
2. [Running samples in a Local Conda environment](#localconda)
|
||||||
1. [Running samples in a Local Conda environment](#localconda)
|
3. [Auto ML SDK Sample Notebooks](#samples)
|
||||||
1. [Automated ML SDK Sample Notebooks](#samples)
|
4. [Documentation](#documentation)
|
||||||
1. [Documentation](#documentation)
|
5. [Running using python command](#pythoncommand)
|
||||||
1. [Running using python command](#pythoncommand)
|
6. [Troubleshooting](#troubleshooting)
|
||||||
1. [Troubleshooting](#troubleshooting)
|
|
||||||
|
|
||||||
<a name="introduction"></a>
|
|
||||||
# Automated ML introduction
|
|
||||||
Automated machine learning (automated ML) builds high quality machine learning models for you by automating model and hyperparameter selection. Bring a labelled dataset that you want to build a model for, automated ML will give you a high quality machine learning model that you can use for predictions.
|
|
||||||
|
|
||||||
|
# Auto ML Introduction <a name="introduction"></a>
|
||||||
|
AutoML builds high quality Machine Learning models for you by automating model and hyperparameter selection. Bring a labelled dataset that you want to build a model for, AutoML will give you a high quality machine learning model that you can use for predictions.
|
||||||
|
|
||||||
If you are new to Data Science, AutoML will help you get jumpstarted by simplifying machine learning model building. It abstracts you from needing to perform model selection, hyperparameter selection and in one step creates a high quality trained model for you to use.
|
If you are new to Data Science, AutoML will help you get jumpstarted by simplifying machine learning model building. It abstracts you from needing to perform model selection, hyperparameter selection and in one step creates a high quality trained model for you to use.
|
||||||
|
|
||||||
If you are an experienced data scientist, AutoML will help increase your productivity by intelligently performing the model and hyperparameter selection for your training and generates high quality models much quicker than manually specifying several combinations of the parameters and running training jobs. AutoML provides visibility and access to all the training jobs and the performance characteristics of the models to help you further tune the pipeline if you desire.
|
If you are an experienced data scientist, AutoML will help increase your productivity by intelligently performing the model and hyperparameter selection for your training and generates high quality models much quicker than manually specifying several combinations of the parameters and running training jobs. AutoML provides visibility and access to all the training jobs and the performance characteristics of the models to help you further tune the pipeline if you desire.
|
||||||
|
|
||||||
<a name="jupyter"></a>
|
|
||||||
## Running samples in Azure Notebooks - Jupyter based notebooks in the Azure cloud
|
|
||||||
|
|
||||||
1. [](https://aka.ms/aml-clone-azure-notebooks)
|
# Running samples in a Local Conda environment <a name="localconda"></a>
|
||||||
[Import sample notebooks ](https://aka.ms/aml-clone-azure-notebooks) into Azure Notebooks.
|
|
||||||
1. Follow the instructions in the [../00.configuration](00.configuration.ipynb) notebook to create and connect to a workspace.
|
|
||||||
1. Open one of the sample notebooks.
|
|
||||||
|
|
||||||
**Make sure the Azure Notebook kernel is set to `Python 3.6`** when you open a notebook.
|
You can run these notebooks in Azure Notebooks without any extra installation. To run these notebook on your own notebook server, use these installation instructions.
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
<a name="localconda"></a>
|
|
||||||
## Running samples in a Local Conda environment
|
|
||||||
|
|
||||||
To run these notebook on your own notebook server, use these installation instructions.
|
|
||||||
|
|
||||||
The instructions below will install everything you need and then start a Jupyter notebook. To start your Jupyter notebook manually, use:
|
|
||||||
|
|
||||||
```
|
|
||||||
conda activate azure_automl
|
|
||||||
jupyter notebook
|
|
||||||
```
|
|
||||||
|
|
||||||
or on Mac:
|
|
||||||
|
|
||||||
```
|
|
||||||
source activate azure_automl
|
|
||||||
jupyter notebook
|
|
||||||
```
|
|
||||||
|
|
||||||
|
It is best if you create a new conda environment locally to try this SDK, so it doesn't mess up with your existing Python environment.
|
||||||
|
|
||||||
### 1. Install mini-conda from [here](https://conda.io/miniconda.html), choose Python 3.7 or higher.
|
### 1. Install mini-conda from [here](https://conda.io/miniconda.html), choose Python 3.7 or higher.
|
||||||
- **Note**: if you already have conda installed, you can keep using it but it should be version 4.4.10 or later (as shown by: conda -V). If you have a previous version installed, you can update it using the command: conda update conda.
|
- **Note**: if you already have conda installed, you can keep using it but it should be version 4.4.10 or later (as shown by: conda -V). If you have a previous version installed, you can update it using the command: conda update conda.
|
||||||
@@ -57,7 +29,7 @@ There's no need to install mini-conda specifically.
|
|||||||
|
|
||||||
### 3. Setup a new conda environment
|
### 3. Setup a new conda environment
|
||||||
The **automl/automl_setup** script creates a new conda environment, installs the necessary packages, configures the widget and starts a jupyter notebook.
|
The **automl/automl_setup** script creates a new conda environment, installs the necessary packages, configures the widget and starts a jupyter notebook.
|
||||||
It takes the conda environment name as an optional parameter. The default conda environment name is azure_automl. The exact command depends on the operating system. It can take about 10 minutes to execute.
|
It takes the conda environment name as an optional parameter. The default conda environment name is azure_automl. The exact command depends on the operating system. It can take about 30 minutes to execute.
|
||||||
## Windows
|
## Windows
|
||||||
Start a conda command windows, cd to the **automl** folder where the sample notebooks were extracted and then run:
|
Start a conda command windows, cd to the **automl** folder where the sample notebooks were extracted and then run:
|
||||||
```
|
```
|
||||||
@@ -76,19 +48,19 @@ bash automl_setup_mac.sh
|
|||||||
cd to the **automl** folder where the sample notebooks were extracted and then run:
|
cd to the **automl** folder where the sample notebooks were extracted and then run:
|
||||||
|
|
||||||
```
|
```
|
||||||
bash automl_setup_linux.sh
|
automl_setup_linux.sh
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4. Running configuration.ipynb
|
### 4. Running configuration.ipynb
|
||||||
- Before running any samples you next need to run the configuration notebook. Click on 00.configuration.ipynb notebook
|
- Before running any samples you next need to run the configuration notebook. Click on 00.configuration.ipynb notebook
|
||||||
|
- Please make sure you use the Python [conda env:azure_automl] kernel when running this notebook.
|
||||||
- Execute the cells in the notebook to Register Machine Learning Services Resource Provider and create a workspace. (*instructions in notebook*)
|
- Execute the cells in the notebook to Register Machine Learning Services Resource Provider and create a workspace. (*instructions in notebook*)
|
||||||
|
|
||||||
### 5. Running Samples
|
### 5. Running Samples
|
||||||
- Please make sure you use the Python [conda env:azure_automl] kernel when trying the sample Notebooks.
|
- Please make sure you use the Python [conda env:azure_automl] kernel when trying the sample Notebooks.
|
||||||
- Follow the instructions in the individual notebooks to explore various features in AutoML
|
- Follow the instructions in the individual notebooks to explore various features in AutoML
|
||||||
|
|
||||||
<a name="samples"></a>
|
# Auto ML SDK Sample Notebooks <a name="samples"></a>
|
||||||
# Automated ML SDK Sample Notebooks
|
|
||||||
- [00.configuration.ipynb](00.configuration.ipynb)
|
- [00.configuration.ipynb](00.configuration.ipynb)
|
||||||
- Register Machine Learning Services Resource Provider
|
- Register Machine Learning Services Resource Provider
|
||||||
- Create new Azure ML Workspace
|
- Create new Azure ML Workspace
|
||||||
@@ -115,7 +87,7 @@ bash automl_setup_linux.sh
|
|||||||
|
|
||||||
- [03b.auto-ml-remote-batchai.ipynb](03b.auto-ml-remote-batchai.ipynb)
|
- [03b.auto-ml-remote-batchai.ipynb](03b.auto-ml-remote-batchai.ipynb)
|
||||||
- Dataset: scikit learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
|
- Dataset: scikit learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
|
||||||
- Example of using automated ML for classification using a remote Batch AI compute for training
|
- Example of using Auto ML for classification using a remote Batch AI compute for training
|
||||||
- Parallel execution of iterations
|
- Parallel execution of iterations
|
||||||
- Async tracking of progress
|
- Async tracking of progress
|
||||||
- Cancelling individual iterations or entire run
|
- Cancelling individual iterations or entire run
|
||||||
@@ -134,7 +106,7 @@ bash automl_setup_linux.sh
|
|||||||
- Specify a target metrics to indicate stopping criteria
|
- Specify a target metrics to indicate stopping criteria
|
||||||
- Handling Missing Data in the input
|
- Handling Missing Data in the input
|
||||||
|
|
||||||
- [06.auto-ml-sparse-data-train-test-split.ipynb](06.auto-ml-sparse-data-train-test-split.ipynb)
|
- [06.auto-ml-sparse-data-custom-cv-split.ipynb](06.auto-ml-sparse-data-custom-cv-split.ipynb)
|
||||||
- Dataset: Scikit learn's [20newsgroup](http://scikit-learn.org/stable/datasets/twenty_newsgroups.html)
|
- Dataset: Scikit learn's [20newsgroup](http://scikit-learn.org/stable/datasets/twenty_newsgroups.html)
|
||||||
- Handle sparse datasets
|
- Handle sparse datasets
|
||||||
- Specify custom train and validation set
|
- Specify custom train and validation set
|
||||||
@@ -143,11 +115,11 @@ bash automl_setup_linux.sh
|
|||||||
- List all projects for the workspace
|
- List all projects for the workspace
|
||||||
- List all AutoML Runs for a given project
|
- List all AutoML Runs for a given project
|
||||||
- Get details for a AutoML Run. (Automl settings, run widget & all metrics)
|
- Get details for a AutoML Run. (Automl settings, run widget & all metrics)
|
||||||
- Download fitted pipeline for any iteration
|
- Downlaod fitted pipeline for any iteration
|
||||||
|
|
||||||
- [08.auto-ml-remote-execution-with-DataStore.ipynb](08.auto-ml-remote-execution-with-DataStore.ipynb)
|
- [08.auto-ml-remote-execution-with-text-file-on-DSVM](08.auto-ml-remote-execution-with-text-file-on-DSVM.ipynb)
|
||||||
- Dataset: scikit learn's [digit dataset](https://innovate.burningman.org/datasets-page/)
|
- Dataset: scikit learn's [digit dataset](https://innovate.burningman.org/datasets-page/)
|
||||||
- Download the data and store it in DataStore.
|
- Download the data and store it in the DSVM to improve performance.
|
||||||
|
|
||||||
- [09.auto-ml-classification-with-deployment.ipynb](09.auto-ml-classification-with-deployment.ipynb)
|
- [09.auto-ml-classification-with-deployment.ipynb](09.auto-ml-classification-with-deployment.ipynb)
|
||||||
- Dataset: scikit learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
|
- Dataset: scikit learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
|
||||||
@@ -171,76 +143,34 @@ bash automl_setup_linux.sh
|
|||||||
- [13.auto-ml-dataprep.ipynb](13.auto-ml-dataprep.ipynb)
|
- [13.auto-ml-dataprep.ipynb](13.auto-ml-dataprep.ipynb)
|
||||||
- Using DataPrep for reading data
|
- Using DataPrep for reading data
|
||||||
|
|
||||||
- [14.auto-ml-model-explanation.ipynb](14.auto-ml-model-explanation.ipynb)
|
- [14a.auto-ml-classification-ensemble.ipynb](14a.auto-ml-classification-ensemble.ipynb)
|
||||||
- Dataset: sklearn's [iris dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html)
|
- Classification with ensembling
|
||||||
- Explaining the AutoML classification pipeline
|
|
||||||
- Visualizing feature importance in widget
|
|
||||||
|
|
||||||
- [15a.auto-ml-classification-ensemble.ipynb](15a.auto-ml-classification-ensemble.ipynb)
|
- [14b.auto-ml-regression-ensemble.ipynb](14b.auto-ml-regression-ensemble.ipynb)
|
||||||
- Dataset: scikit learn's [digit dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
|
- Regression with ensembling
|
||||||
- Enables an extra iteration for generating an Ensemble of models
|
|
||||||
- Uses local compute for training
|
|
||||||
|
|
||||||
- [15b.auto-ml-regression-ensemble.ipynb](15b.auto-ml-regression-ensemble.ipynb)
|
# Documentation <a name="documentation"></a>
|
||||||
- Dataset: scikit learn's [diabetes dataset](http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html)
|
|
||||||
- Enables an extra iteration for generating an Ensemble of models
|
|
||||||
- Uses remote Linux DSVM for training
|
|
||||||
|
|
||||||
<a name="documentation"></a>
|
|
||||||
# Documentation
|
|
||||||
## Table of Contents
|
## Table of Contents
|
||||||
1. [Automated ML Settings ](#automlsettings)
|
1. [Auto ML Settings ](#automlsettings)
|
||||||
1. [Cross validation split options](#cvsplits)
|
2. [Cross validation split options](#cvsplits)
|
||||||
1. [Get Data Syntax](#getdata)
|
3. [Get Data Syntax](#getdata)
|
||||||
1. [Data pre-processing and featurization](#preprocessing)
|
4. [Data pre-processing and featurization](#preprocessing)
|
||||||
|
|
||||||
<a name="automlsettings"></a>
|
|
||||||
## Automated ML Settings
|
|
||||||
|
|
||||||
|
## Auto ML Settings <a name="automlsettings"></a>
|
||||||
|Property|Description|Default|
|
|Property|Description|Default|
|
||||||
|-|-|-|
|
|-|-|-|
|
||||||
|**primary_metric**|This is the metric that you want to optimize.<br><br> Classification supports the following primary metrics <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i><br><br> Regression supports the following primary metrics <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i><br><i>normalized_root_mean_squared_log_error</i>| Classification: accuracy <br><br> Regression: spearman_correlation
|
|**primary_metric**|This is the metric that you want to optimize.<br><br> Classification supports the following primary metrics <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>balanced_accuracy</i><br><i>average_precision_score_weighted</i><br><i>precision_score_weighted</i><br><br> Regression supports the following primary metrics <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i><br><i>normalized_root_mean_squared_log_error</i>| Classification: accuracy <br><br> Regression: spearman_correlation
|
||||||
|**iteration_timeout_minutes**|Time limit in minutes for each iteration|None|
|
|**max_time_sec**|Time limit in seconds for each iteration|None|
|
||||||
|**iterations**|Number of iterations. In each iteration trains the data with a specific pipeline. To get the best result, use at least 100. |100|
|
|**iterations**|Number of iterations. In each iteration trains the data with a specific pipeline. To get the best result, use at least 100. |100|
|
||||||
|**n_cross_validations**|Number of cross validation splits|None|
|
|**n_cross_validations**|Number of cross validation splits|None|
|
||||||
|**validation_size**|Size of validation set as percentage of all training samples|None|
|
|**validation_size**|Size of validation set as percentage of all training samples|None|
|
||||||
|**max_concurrent_iterations**|Max number of iterations that would be executed in parallel|1|
|
|**concurrent_iterations**|Max number of iterations that would be executed in parallel|1|
|
||||||
|**preprocess**|*True/False* <br>Setting this to *True* enables preprocessing <br>on the input to handle missing data, and perform some common feature extraction<br>*Note: If input data is Sparse you cannot use preprocess=True*|False|
|
|**preprocess**|*True/False* <br>Setting this to *True* enables preprocessing <br>on the input to handle missing data, and perform some common feature extraction<br>*Note: If input data is Sparse you cannot use preprocess=True*|False|
|
||||||
|**max_cores_per_iteration**| Indicates how many cores on the compute target would be used to train a single pipeline.<br> You can set it to *-1* to use all cores|1|
|
|**max_cores_per_iteration**| Indicates how many cores on the compute target would be used to train a single pipeline.<br> You can set it to *-1* to use all cores|1|
|
||||||
|**experiment_exit_score**|*double* value indicating the target for *primary_metric*. <br> Once the target is surpassed the run terminates|None|
|
|**exit_score**|*double* value indicating the target for *primary_metric*. <br> Once the target is surpassed the run terminates|None|
|
||||||
|**blacklist_models**|*Array* of *strings* indicating models to ignore for Auto ML from the list of models.|None|
|
|**blacklist_algos**|*Array* of *strings* indicating pipelines to ignore for Auto ML.<br><br> Allowed values for **Classification**<br><i>LogisticRegression</i><br><i>SGDClassifierWrapper</i><br><i>NBWrapper</i><br><i>BernoulliNB</i><br><i>SVCWrapper</i><br><i>LinearSVMWrapper</i><br><i>KNeighborsClassifier</i><br><i>DecisionTreeClassifier</i><br><i>RandomForestClassifier</i><br><i>ExtraTreesClassifier</i><br><i>gradient boosting</i><br><i>LightGBMClassifier</i><br><br>Allowed values for **Regression**<br><i>ElasticNet</i><br><i>GradientBoostingRegressor</i><br><i>DecisionTreeRegressor</i><br><i>KNeighborsRegressor</i><br><i>LassoLars</i><br><i>SGDRegressor</i><br><i>RandomForestRegressor</i><br><i>ExtraTreesRegressor</i>|None|
|
||||||
|**whilelist_models**|*Array* of *strings* use only models listed for Auto ML from the list of models..|None|
|
|
||||||
<a name="cvsplits"></a>
|
|
||||||
## List of models for white list/blacklist
|
|
||||||
**Classification**
|
|
||||||
<br><i>LogisticRegression</i>
|
|
||||||
<br><i>SGD</i>
|
|
||||||
<br><i>MultinomialNaiveBayes</i>
|
|
||||||
<br><i>BernoulliNaiveBayes</i>
|
|
||||||
<br><i>SVM</i>
|
|
||||||
<br><i>LinearSVM</i>
|
|
||||||
<br><i>KNN</i>
|
|
||||||
<br><i>DecisionTree</i>
|
|
||||||
<br><i>RandomForest</i>
|
|
||||||
<br><i>ExtremeRandomTrees</i>
|
|
||||||
<br><i>LightGBM</i>
|
|
||||||
<br><i>GradientBoosting</i>
|
|
||||||
<br><i>TensorFlowDNN</i>
|
|
||||||
<br><i>TensorFlowLinearClassifier</i>
|
|
||||||
<br><br>**Regression**
|
|
||||||
<br><i>ElasticNet</i>
|
|
||||||
<br><i>GradientBoosting</i>
|
|
||||||
<br><i>DecisionTree</i>
|
|
||||||
<br><i>KNN</i>
|
|
||||||
<br><i>LassoLars</i>
|
|
||||||
<br><i>SGD</i>
|
|
||||||
<br><i>RandomForest</i>
|
|
||||||
<br><i>ExtremeRandomTrees</i>
|
|
||||||
<br><i>LightGBM</i>
|
|
||||||
<br><i>TensorFlowLinearRegressor</i>
|
|
||||||
<br><i>TensorFlowDNN</i>
|
|
||||||
|
|
||||||
## Cross validation split options
|
## Cross validation split options <a name="cvsplits"></a>
|
||||||
### K-Folds Cross Validation
|
### K-Folds Cross Validation
|
||||||
Use *n_cross_validations* setting to specify the number of cross validations. The training data set will be randomly split into *n_cross_validations* folds of equal size. During each cross validation round, one of the folds will be used for validation of the model trained on the remaining folds. This process repeats for *n_cross_validations* rounds until each fold is used once as validation set. Finally, the average scores accross all *n_cross_validations* rounds will be reported, and the corresponding model will be retrained on the whole training data set.
|
Use *n_cross_validations* setting to specify the number of cross validations. The training data set will be randomly split into *n_cross_validations* folds of equal size. During each cross validation round, one of the folds will be used for validation of the model trained on the remaining folds. This process repeats for *n_cross_validations* rounds until each fold is used once as validation set. Finally, the average scores accross all *n_cross_validations* rounds will be reported, and the corresponding model will be retrained on the whole training data set.
|
||||||
|
|
||||||
@@ -250,8 +180,7 @@ Use *validation_size* to specify the percentage of the training data set that sh
|
|||||||
### Custom train and validation set
|
### Custom train and validation set
|
||||||
You can specify seperate train and validation set either through the get_data() or directly to the fit method.
|
You can specify seperate train and validation set either through the get_data() or directly to the fit method.
|
||||||
|
|
||||||
<a name="getdata"></a>
|
## get_data() syntax <a name="getdata"></a>
|
||||||
## get_data() syntax
|
|
||||||
The *get_data()* function can be used to return a dictionary with these values:
|
The *get_data()* function can be used to return a dictionary with these values:
|
||||||
|
|
||||||
|Key|Type|Dependency|Mutually Exclusive with|Description|
|
|Key|Type|Dependency|Mutually Exclusive with|Description|
|
||||||
@@ -267,23 +196,21 @@ The *get_data()* function can be used to return a dictionary with these values:
|
|||||||
|columns|Array of strings|data_train||*Optional* Whitelist of columns to use for features|
|
|columns|Array of strings|data_train||*Optional* Whitelist of columns to use for features|
|
||||||
|cv_splits_indices|Array of integers|data_train||*Optional* List of indexes to split the data for cross validation|
|
|cv_splits_indices|Array of integers|data_train||*Optional* List of indexes to split the data for cross validation|
|
||||||
|
|
||||||
<a name="preprocessing"></a>
|
## Data pre-processing and featurization <a name="preprocessing"></a>
|
||||||
## Data pre-processing and featurization
|
If you use "preprocess=True", the following data preprocessing steps are performed automatically for you:
|
||||||
If you use `preprocess=True`, the following data preprocessing steps are performed automatically for you:
|
### 1. Dropping high cardinality or no variance features
|
||||||
|
|
||||||
1. Dropping high cardinality or no variance features
|
|
||||||
- Features with no useful information are dropped from training and validation sets. These include features with all values missing, same value across all rows or with extremely high cardinality (e.g., hashes, IDs or GUIDs).
|
- Features with no useful information are dropped from training and validation sets. These include features with all values missing, same value across all rows or with extremely high cardinality (e.g., hashes, IDs or GUIDs).
|
||||||
2. Missing value imputation
|
### 2. Missing value imputation
|
||||||
- For numerical features, missing values are imputed with average of values in the column.
|
- For numerical features, missing values are imputed with average of values in the column.
|
||||||
- For categorical features, missing values are imputed with most frequent value.
|
- For categorical features, missing values are imputed with most frequent value.
|
||||||
3. Generating additional features
|
### 3. Generating additional features
|
||||||
- For DateTime features: Year, Month, Day, Day of week, Day of year, Quarter, Week of the year, Hour, Minute, Second.
|
- For DateTime features: Year, Month, Day, Day of week, Day of year, Quarter, Week of the year, Hour, Minute, Second.
|
||||||
- For Text features: Term frequency based on bi-grams and tri-grams, Count vectorizer.
|
- For Text features: Term frequency based on bi-grams and tri-grams, Count vectorizer.
|
||||||
4. Transformations and encodings
|
### 4. Transformations and encodings
|
||||||
- Numeric features with very few unique values are transformed into categorical features.
|
- Numeric features with very few unique values are transformed into categorical features.
|
||||||
|
- Depending on cardinality of categorical features label encoding or (hashing) one-hot encoding is performed.
|
||||||
|
|
||||||
<a name="pythoncommand"></a>
|
# Running using python command <a name="pythoncommand"></a>
|
||||||
# Running using python command
|
|
||||||
Jupyter notebook provides a File / Download as / Python (.py) option for saving the notebook as a Python file.
|
Jupyter notebook provides a File / Download as / Python (.py) option for saving the notebook as a Python file.
|
||||||
You can then run this file using the python command.
|
You can then run this file using the python command.
|
||||||
However, on Windows the file needs to be modified before it can be run.
|
However, on Windows the file needs to be modified before it can be run.
|
||||||
@@ -293,14 +220,13 @@ The following condition must be added to the main code in the file:
|
|||||||
|
|
||||||
The main code of the file must be indented so that it is under this condition.
|
The main code of the file must be indented so that it is under this condition.
|
||||||
|
|
||||||
<a name="troubleshooting"></a>
|
# Troubleshooting <a name="troubleshooting"></a>
|
||||||
# Troubleshooting
|
|
||||||
## Iterations fail and the log contains "MemoryError"
|
## Iterations fail and the log contains "MemoryError"
|
||||||
This can be caused by insufficient memory on the DSVM. AutoML loads all training data into memory. So, the available memory should be more than the training data size.
|
This can be caused by insufficient memory on the DSVM. AutoML loads all training data into memory. So, the available memory should be more than the training data size.
|
||||||
If you are using a remote DSVM, memory is needed for each concurrent iteration. The max_concurrent_iterations setting specifies the maximum concurrent iterations. For example, if the training data size is 8Gb and max_concurrent_iterations is set to 10, the minimum memory required is at least 80Gb.
|
If you are using a remote DSVM, memory is needed for each concurrent iteration. The concurrent_iterations setting specifies the maximum concurrent iterations. For example, if the training data size is 8Gb and concurrent_iterations is set to 10, the minimum memory required is at least 80Gb.
|
||||||
To resolve this issue, allocate a DSVM with more memory or reduce the value specified for max_concurrent_iterations.
|
To resolve this issue, allocate a DSVM with more memory or reduce the value specified for concurrent_iterations.
|
||||||
|
|
||||||
## Iterations show as "Not Responding" in the RunDetails widget.
|
## Iterations show as "Not Responding" in the RunDetails widget.
|
||||||
This can be caused by too many concurrent iterations for a remote DSVM. Each concurrent iteration usually takes 100% of a core when it is running. Some iterations can use multiple cores. So, the max_concurrent_iterations setting should always be less than the number of cores of the DSVM.
|
This can be caused by too many concurrent iterations for a remote DSVM. Each concurrent iteration usually takes 100% of a core when it is running. Some iterations can use multiple cores. So, the concurrent_iterations setting should always be less than the number of cores of the DSVM.
|
||||||
To resolve this issue, try reducing the value specified for the max_concurrent_iterations setting.
|
To resolve this issue, try reducing the value specified for the concurrent_iterations setting.
|
||||||
|
|
||||||
|
|||||||
@@ -4,28 +4,16 @@ dependencies:
|
|||||||
# Currently Azure ML only supports 3.5.2 and later.
|
# Currently Azure ML only supports 3.5.2 and later.
|
||||||
- python=3.6
|
- python=3.6
|
||||||
- nb_conda
|
- nb_conda
|
||||||
- matplotlib==2.1.0
|
- matplotlib
|
||||||
- numpy>=1.11.0,<1.15.0
|
- numpy>=1.11.0,<1.16.0
|
||||||
- cython
|
|
||||||
- urllib3<1.24
|
|
||||||
- scipy>=0.19.0,<0.20.0
|
- scipy>=0.19.0,<0.20.0
|
||||||
- scikit-learn>=0.18.0,<=0.19.1
|
- scikit-learn>=0.18.0,<=0.19.1
|
||||||
- pandas>=0.22.0,<0.23.0
|
- pandas>=0.22.0,<0.23.0
|
||||||
|
|
||||||
# Required for azuremlftk
|
|
||||||
- dill
|
|
||||||
- pyodbc
|
|
||||||
- statsmodels
|
|
||||||
- numexpr
|
|
||||||
- keras
|
|
||||||
- distributed>=1.21.5,<1.24
|
|
||||||
|
|
||||||
- pip:
|
- pip:
|
||||||
|
|
||||||
# Required for azuremlftk
|
|
||||||
- https://azuremlpackages.blob.core.windows.net/forecasting/azuremlftk-0.1.18313.5a1-py3-none-any.whl
|
|
||||||
|
|
||||||
# Required packages for AzureML execution, history, and data preparation.
|
# Required packages for AzureML execution, history, and data preparation.
|
||||||
- azureml-sdk[automl,notebooks]
|
- --extra-index-url https://pypi.python.org/simple
|
||||||
|
- azureml-sdk[automl]
|
||||||
|
- azureml-train-widgets
|
||||||
- pandas_ml
|
- pandas_ml
|
||||||
|
|
||||||
|
|||||||
@@ -1,31 +0,0 @@
|
|||||||
name: azure_automl
|
|
||||||
dependencies:
|
|
||||||
# The python interpreter version.
|
|
||||||
# Currently Azure ML only supports 3.5.2 and later.
|
|
||||||
- python=3.6
|
|
||||||
- nb_conda
|
|
||||||
- matplotlib==2.1.0
|
|
||||||
- numpy>=1.15.3
|
|
||||||
- cython
|
|
||||||
- urllib3<1.24
|
|
||||||
- scipy>=0.19.0,<0.20.0
|
|
||||||
- scikit-learn>=0.18.0,<=0.19.1
|
|
||||||
- pandas>=0.22.0,<0.23.0
|
|
||||||
|
|
||||||
# Required for azuremlftk
|
|
||||||
- dill
|
|
||||||
- pyodbc
|
|
||||||
- statsmodels
|
|
||||||
- numexpr
|
|
||||||
- keras
|
|
||||||
- distributed>=1.21.5,<1.24
|
|
||||||
|
|
||||||
- pip:
|
|
||||||
|
|
||||||
# Required for azuremlftk
|
|
||||||
- https://azuremlpackages.blob.core.windows.net/forecasting/azuremlftk-0.1.18313.5a1-py3-none-any.whl
|
|
||||||
# Required packages for AzureML execution, history, and data preparation.
|
|
||||||
- azureml-sdk[automl,notebooks]
|
|
||||||
- pandas_ml
|
|
||||||
|
|
||||||
|
|
||||||
@@ -1,21 +1,16 @@
|
|||||||
@echo off
|
@echo off
|
||||||
set conda_env_name=%1
|
set conda_env_name=%1
|
||||||
set automl_env_file=%2
|
|
||||||
set PIP_NO_WARN_SCRIPT_LOCATION=0
|
|
||||||
|
|
||||||
IF "%conda_env_name%"=="" SET conda_env_name="azure_automl"
|
IF "%conda_env_name%"=="" SET conda_env_name="azure_automl"
|
||||||
IF "%automl_env_file%"=="" SET automl_env_file="automl_env.yml"
|
|
||||||
|
|
||||||
IF NOT EXIST %automl_env_file% GOTO YmlMissing
|
|
||||||
|
|
||||||
call conda activate %conda_env_name% 2>nul:
|
call conda activate %conda_env_name% 2>nul:
|
||||||
|
|
||||||
if not errorlevel 1 (
|
if not errorlevel 1 (
|
||||||
echo Upgrading azureml-sdk[automl] in existing conda environment %conda_env_name%
|
echo Upgrading azureml-sdk[automl] in existing conda environment %conda_env_name%
|
||||||
call pip install --upgrade azureml-sdk[automl,notebooks]
|
call pip install --upgrade azureml-sdk[automl]
|
||||||
if errorlevel 1 goto ErrorExit
|
if errorlevel 1 goto ErrorExit
|
||||||
) else (
|
) else (
|
||||||
call conda env create -f %automl_env_file% -n %conda_env_name%
|
call conda env create -f automl_env.yml -n %conda_env_name%
|
||||||
)
|
)
|
||||||
|
|
||||||
call conda activate %conda_env_name% 2>nul:
|
call conda activate %conda_env_name% 2>nul:
|
||||||
@@ -23,12 +18,10 @@ if errorlevel 1 goto ErrorExit
|
|||||||
|
|
||||||
call pip install psutil
|
call pip install psutil
|
||||||
|
|
||||||
call python -m ipykernel install --user --name %conda_env_name% --display-name "Python (%conda_env_name%)"
|
call jupyter nbextension install --py azureml.train.widgets
|
||||||
|
|
||||||
call jupyter nbextension install --py azureml.widgets --user
|
|
||||||
if errorlevel 1 goto ErrorExit
|
if errorlevel 1 goto ErrorExit
|
||||||
|
|
||||||
call jupyter nbextension enable --py azureml.widgets --user
|
call jupyter nbextension enable --py azureml.train.widgets
|
||||||
if errorlevel 1 goto ErrorExit
|
if errorlevel 1 goto ErrorExit
|
||||||
|
|
||||||
echo.
|
echo.
|
||||||
@@ -43,9 +36,6 @@ jupyter notebook --log-level=50
|
|||||||
|
|
||||||
goto End
|
goto End
|
||||||
|
|
||||||
:YmlMissing
|
|
||||||
echo File %automl_env_file% not found.
|
|
||||||
|
|
||||||
:ErrorExit
|
:ErrorExit
|
||||||
echo Install failed
|
echo Install failed
|
||||||
|
|
||||||
|
|||||||
@@ -1,34 +1,21 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
CONDA_ENV_NAME=$1
|
CONDA_ENV_NAME=$1
|
||||||
AUTOML_ENV_FILE=$2
|
|
||||||
PIP_NO_WARN_SCRIPT_LOCATION=0
|
|
||||||
|
|
||||||
if [ "$CONDA_ENV_NAME" == "" ]
|
if [ "$CONDA_ENV_NAME" == "" ]
|
||||||
then
|
then
|
||||||
CONDA_ENV_NAME="azure_automl"
|
CONDA_ENV_NAME="azure_automl"
|
||||||
fi
|
fi
|
||||||
|
|
||||||
if [ "$AUTOML_ENV_FILE" == "" ]
|
|
||||||
then
|
|
||||||
AUTOML_ENV_FILE="automl_env.yml"
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ ! -f $AUTOML_ENV_FILE ]; then
|
|
||||||
echo "File $AUTOML_ENV_FILE not found"
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
|
|
||||||
if source activate $CONDA_ENV_NAME 2> /dev/null
|
if source activate $CONDA_ENV_NAME 2> /dev/null
|
||||||
then
|
then
|
||||||
echo "Upgrading azureml-sdk[automl] in existing conda environment" $CONDA_ENV_NAME
|
echo "Upgrading azureml-sdk[automl] in existing conda environment" $CONDA_ENV_NAME
|
||||||
pip install --upgrade azureml-sdk[automl,notebooks]
|
pip install --upgrade azureml-sdk[automl]
|
||||||
else
|
else
|
||||||
conda env create -f $AUTOML_ENV_FILE -n $CONDA_ENV_NAME &&
|
conda env create -f automl_env.yml -n $CONDA_ENV_NAME &&
|
||||||
source activate $CONDA_ENV_NAME &&
|
source activate $CONDA_ENV_NAME &&
|
||||||
python -m ipykernel install --user --name $CONDA_ENV_NAME --display-name "Python ($CONDA_ENV_NAME)" &&
|
jupyter nbextension install --py azureml.train.widgets --user &&
|
||||||
jupyter nbextension install --py azureml.widgets --user &&
|
jupyter nbextension enable --py azureml.train.widgets --user &&
|
||||||
jupyter nbextension enable --py azureml.widgets --user &&
|
|
||||||
echo "" &&
|
echo "" &&
|
||||||
echo "" &&
|
echo "" &&
|
||||||
echo "***************************************" &&
|
echo "***************************************" &&
|
||||||
|
|||||||
@@ -1,36 +1,22 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
CONDA_ENV_NAME=$1
|
CONDA_ENV_NAME=$1
|
||||||
AUTOML_ENV_FILE=$2
|
|
||||||
PIP_NO_WARN_SCRIPT_LOCATION=0
|
|
||||||
|
|
||||||
if [ "$CONDA_ENV_NAME" == "" ]
|
if [ "$CONDA_ENV_NAME" == "" ]
|
||||||
then
|
then
|
||||||
CONDA_ENV_NAME="azure_automl"
|
CONDA_ENV_NAME="azure_automl"
|
||||||
fi
|
fi
|
||||||
|
|
||||||
if [ "$AUTOML_ENV_FILE" == "" ]
|
|
||||||
then
|
|
||||||
AUTOML_ENV_FILE="automl_env_mac.yml"
|
|
||||||
fi
|
|
||||||
|
|
||||||
if [ ! -f $AUTOML_ENV_FILE ]; then
|
|
||||||
echo "File $AUTOML_ENV_FILE not found"
|
|
||||||
exit 1
|
|
||||||
fi
|
|
||||||
|
|
||||||
if source activate $CONDA_ENV_NAME 2> /dev/null
|
if source activate $CONDA_ENV_NAME 2> /dev/null
|
||||||
then
|
then
|
||||||
echo "Upgrading azureml-sdk[automl] in existing conda environment" $CONDA_ENV_NAME
|
echo "Upgrading azureml-sdk[automl] in existing conda environment" $CONDA_ENV_NAME
|
||||||
pip install --upgrade azureml-sdk[automl,notebooks]
|
pip install --upgrade azureml-sdk[automl]
|
||||||
else
|
else
|
||||||
conda env create -f $AUTOML_ENV_FILE -n $CONDA_ENV_NAME &&
|
conda env create -f automl_env.yml -n $CONDA_ENV_NAME &&
|
||||||
source activate $CONDA_ENV_NAME &&
|
source activate $CONDA_ENV_NAME &&
|
||||||
conda install lightgbm -c conda-forge -y &&
|
conda install lightgbm -c conda-forge -y &&
|
||||||
python -m ipykernel install --user --name $CONDA_ENV_NAME --display-name "Python ($CONDA_ENV_NAME)" &&
|
jupyter nbextension install --py azureml.train.widgets --user &&
|
||||||
jupyter nbextension install --py azureml.widgets --user &&
|
jupyter nbextension enable --py azureml.train.widgets --user &&
|
||||||
jupyter nbextension enable --py azureml.widgets --user &&
|
|
||||||
pip install numpy==1.15.3
|
|
||||||
echo "" &&
|
echo "" &&
|
||||||
echo "" &&
|
echo "" &&
|
||||||
echo "***************************************" &&
|
echo "***************************************" &&
|
||||||
@@ -48,4 +34,3 @@ then
|
|||||||
fi
|
fi
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
File diff suppressed because it is too large
Load Diff
174
ignore/doc-qa/how-to-deploy-to-aci/how-to-deploy-to-aci.py
Normal file
174
ignore/doc-qa/how-to-deploy-to-aci/how-to-deploy-to-aci.py
Normal file
@@ -0,0 +1,174 @@
|
|||||||
|
#!/usr/bin/env python
|
||||||
|
# coding: utf-8
|
||||||
|
|
||||||
|
import azureml.core
|
||||||
|
print('SDK version' + azureml.core.VERSION)
|
||||||
|
|
||||||
|
# PREREQ: load workspace info
|
||||||
|
# import azureml.core
|
||||||
|
|
||||||
|
# <loadWorkspace>
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.from_config()
|
||||||
|
# </loadWorkspace>
|
||||||
|
|
||||||
|
scorepy_content = "import json\nimport numpy as np\nimport os\nimport pickle\nfrom sklearn.externals import joblib\nfrom sklearn.linear_model import LogisticRegression\n\nfrom azureml.core.model import Model\n\ndef init():\n global model\n # retreive the path to the model file using the model name\n model_path = Model.get_model_path('sklearn_mnist')\n model = joblib.load(model_path)\n\ndef run(raw_data):\n data = np.array(json.loads(raw_data)['data'])\n # make prediction\n y_hat = model.predict(data)\n return json.dumps(y_hat.tolist())"
|
||||||
|
print(scorepy_content)
|
||||||
|
with open("score.py","w") as f:
|
||||||
|
f.write(scorepy_content)
|
||||||
|
|
||||||
|
|
||||||
|
# PREREQ: create environment file
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
myenv = CondaDependencies()
|
||||||
|
myenv.add_conda_package("scikit-learn")
|
||||||
|
|
||||||
|
with open("myenv.yml","w") as f:
|
||||||
|
f.write(myenv.serialize_to_string())
|
||||||
|
|
||||||
|
#<configImage>
|
||||||
|
from azureml.core.image import ContainerImage
|
||||||
|
|
||||||
|
image_config = ContainerImage.image_configuration(execution_script = "score.py",
|
||||||
|
runtime = "python",
|
||||||
|
conda_file = "myenv.yml",
|
||||||
|
description = "Image with mnist model",
|
||||||
|
tags = {"data": "mnist", "type": "classification"}
|
||||||
|
)
|
||||||
|
#</configImage>
|
||||||
|
|
||||||
|
# <configAci>
|
||||||
|
from azureml.core.webservice import AciWebservice
|
||||||
|
|
||||||
|
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
|
||||||
|
memory_gb = 1,
|
||||||
|
tags = {"data": "mnist", "type": "classification"},
|
||||||
|
description = 'Handwriting recognition')
|
||||||
|
# </configAci>
|
||||||
|
|
||||||
|
#<registerModel>
|
||||||
|
from azureml.core.model import Model
|
||||||
|
|
||||||
|
model_name = "sklearn_mnist"
|
||||||
|
model = Model.register(model_path = "sklearn_mnist_model.pkl",
|
||||||
|
model_name = model_name,
|
||||||
|
tags = {"data": "mnist", "type": "classification"},
|
||||||
|
description = "Mnist handwriting recognition",
|
||||||
|
workspace = ws)
|
||||||
|
#</registerModel>
|
||||||
|
|
||||||
|
# <retrieveModel>
|
||||||
|
from azureml.core.model import Model
|
||||||
|
|
||||||
|
model_name = "sklearn_mnist"
|
||||||
|
model=Model(ws, model_name)
|
||||||
|
# </retrieveModel>
|
||||||
|
|
||||||
|
|
||||||
|
# ## DEPLOY FROM REGISTERED MODEL
|
||||||
|
|
||||||
|
# <option2Deploy>
|
||||||
|
from azureml.core.webservice import Webservice
|
||||||
|
|
||||||
|
service_name = 'aci-mnist-2'
|
||||||
|
service = Webservice.deploy_from_model(deployment_config = aciconfig,
|
||||||
|
image_config = image_config,
|
||||||
|
models = [model], # this is the registered model object
|
||||||
|
name = service_name,
|
||||||
|
workspace = ws)
|
||||||
|
service.wait_for_deployment(show_output = True)
|
||||||
|
print(service.state)
|
||||||
|
# </option2Deploy>
|
||||||
|
|
||||||
|
service.delete()
|
||||||
|
|
||||||
|
# ## DEPLOY FROM IMAGE
|
||||||
|
|
||||||
|
|
||||||
|
# <option3CreateImage>
|
||||||
|
from azureml.core.image import ContainerImage
|
||||||
|
|
||||||
|
image = ContainerImage.create(name = "myimage1",
|
||||||
|
models = [model], # this is the registered model object
|
||||||
|
image_config = image_config,
|
||||||
|
workspace = ws)
|
||||||
|
|
||||||
|
image.wait_for_creation(show_output = True)
|
||||||
|
# </option3CreateImage>
|
||||||
|
|
||||||
|
# <option3Deploy>
|
||||||
|
from azureml.core.webservice import Webservice
|
||||||
|
|
||||||
|
service_name = 'aci-mnist-13'
|
||||||
|
service = Webservice.deploy_from_image(deployment_config = aciconfig,
|
||||||
|
image = image,
|
||||||
|
name = service_name,
|
||||||
|
workspace = ws)
|
||||||
|
service.wait_for_deployment(show_output = True)
|
||||||
|
print(service.state)
|
||||||
|
# </option3Deploy>
|
||||||
|
|
||||||
|
service.delete()
|
||||||
|
|
||||||
|
|
||||||
|
# ## DEPLOY FROM MODEL FILE
|
||||||
|
# First change score.py!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
scorepy_content = "import json\nimport numpy as np\nimport os\nimport pickle\nfrom sklearn.externals import joblib\nfrom sklearn.linear_model import LogisticRegression\n\nfrom azureml.core.model import Model\n\ndef init():\n global model\n # retreive the path to the model file using the model name\n model_path = Model.get_model_path('sklearn_mnist_model.pkl')\n model = joblib.load(model_path)\n\ndef run(raw_data):\n data = np.array(json.loads(raw_data)['data'])\n # make prediction\n y_hat = model.predict(data)\n return json.dumps(y_hat.tolist())"
|
||||||
|
with open("score.py","w") as f:
|
||||||
|
f.write(scorepy_content)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# <option1Deploy>
|
||||||
|
from azureml.core.webservice import Webservice
|
||||||
|
|
||||||
|
service_name = 'aci-mnist-1'
|
||||||
|
service = Webservice.deploy(deployment_config = aciconfig,
|
||||||
|
image_config = image_config,
|
||||||
|
model_paths = ['sklearn_mnist_model.pkl'],
|
||||||
|
name = service_name,
|
||||||
|
workspace = ws)
|
||||||
|
|
||||||
|
service.wait_for_deployment(show_output = True)
|
||||||
|
print(service.state)
|
||||||
|
# </option1Deploy>
|
||||||
|
|
||||||
|
# <testService>
|
||||||
|
# Load Data
|
||||||
|
import os
|
||||||
|
import urllib
|
||||||
|
|
||||||
|
os.makedirs('./data', exist_ok = True)
|
||||||
|
|
||||||
|
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz', filename = './data/test-images.gz')
|
||||||
|
|
||||||
|
from utils import load_data
|
||||||
|
X_test = load_data('./data/test-images.gz', False) / 255.0
|
||||||
|
|
||||||
|
from sklearn import datasets
|
||||||
|
import numpy as np
|
||||||
|
import json
|
||||||
|
|
||||||
|
# find 5 random samples from test set
|
||||||
|
n = 5
|
||||||
|
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
|
||||||
|
|
||||||
|
test_samples = json.dumps({"data": X_test[sample_indices].tolist()})
|
||||||
|
test_samples = bytes(test_samples, encoding = 'utf8')
|
||||||
|
|
||||||
|
# predict using the deployed model
|
||||||
|
prediction = service.run(input_data = test_samples)
|
||||||
|
print(prediction)
|
||||||
|
# </testService>
|
||||||
|
|
||||||
|
# <deleteService>
|
||||||
|
service.delete()
|
||||||
|
# </deleteService>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
BIN
ignore/doc-qa/how-to-deploy-to-aci/sklearn_mnist_model.pkl
Normal file
BIN
ignore/doc-qa/how-to-deploy-to-aci/sklearn_mnist_model.pkl
Normal file
Binary file not shown.
27
ignore/doc-qa/how-to-deploy-to-aci/utils.py
Normal file
27
ignore/doc-qa/how-to-deploy-to-aci/utils.py
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
# Copyright (c) Microsoft Corporation. All rights reserved.
|
||||||
|
# Licensed under the MIT License.
|
||||||
|
|
||||||
|
import gzip
|
||||||
|
import numpy as np
|
||||||
|
import struct
|
||||||
|
|
||||||
|
|
||||||
|
# load compressed MNIST gz files and return numpy arrays
|
||||||
|
def load_data(filename, label=False):
|
||||||
|
with gzip.open(filename) as gz:
|
||||||
|
struct.unpack('I', gz.read(4))
|
||||||
|
n_items = struct.unpack('>I', gz.read(4))
|
||||||
|
if not label:
|
||||||
|
n_rows = struct.unpack('>I', gz.read(4))[0]
|
||||||
|
n_cols = struct.unpack('>I', gz.read(4))[0]
|
||||||
|
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols), dtype=np.uint8)
|
||||||
|
res = res.reshape(n_items[0], n_rows * n_cols)
|
||||||
|
else:
|
||||||
|
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
|
||||||
|
res = res.reshape(n_items[0], 1)
|
||||||
|
return res
|
||||||
|
|
||||||
|
|
||||||
|
# one-hot encode a 1-D array
|
||||||
|
def one_hot_encode(array, num_of_classes):
|
||||||
|
return np.eye(num_of_classes)[array.reshape(-1)]
|
||||||
39
ignore/doc-qa/how-to-set-up-training-targets/Local.py
Normal file
39
ignore/doc-qa/how-to-set-up-training-targets/Local.py
Normal file
@@ -0,0 +1,39 @@
|
|||||||
|
# Code for Local computer and Submit training run sections
|
||||||
|
|
||||||
|
# Check core SDK version number
|
||||||
|
import azureml.core
|
||||||
|
|
||||||
|
print("SDK version:", azureml.core.VERSION)
|
||||||
|
|
||||||
|
#<run_local>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
|
||||||
|
# Edit a run configuration property on the fly.
|
||||||
|
run_local = RunConfiguration()
|
||||||
|
|
||||||
|
run_local.environment.python.user_managed_dependencies = True
|
||||||
|
#</run_local>
|
||||||
|
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.from_config()
|
||||||
|
|
||||||
|
|
||||||
|
# Set up an experiment
|
||||||
|
# <experiment>
|
||||||
|
from azureml.core import Experiment
|
||||||
|
experiment_name = 'my_experiment'
|
||||||
|
|
||||||
|
exp = Experiment(workspace=ws, name=experiment_name)
|
||||||
|
# </experiment>
|
||||||
|
|
||||||
|
# Submit the experiment using the run configuration
|
||||||
|
#<local_submit>
|
||||||
|
from azureml.core import ScriptRunConfig
|
||||||
|
import os
|
||||||
|
|
||||||
|
script_folder = os.getcwd()
|
||||||
|
src = ScriptRunConfig(source_directory = script_folder, script = 'train.py', run_config = run_local)
|
||||||
|
run = exp.submit(src)
|
||||||
|
run.wait_for_completion(show_output = True)
|
||||||
|
#</local_submit>
|
||||||
|
|
||||||
48
ignore/doc-qa/how-to-set-up-training-targets/amlcompute.py
Normal file
48
ignore/doc-qa/how-to-set-up-training-targets/amlcompute.py
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
# Code for Azure Machine Learning Compute - Run-based creation
|
||||||
|
|
||||||
|
# Check core SDK version number
|
||||||
|
import azureml.core
|
||||||
|
|
||||||
|
print("SDK version:", azureml.core.VERSION)
|
||||||
|
|
||||||
|
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.from_config()
|
||||||
|
|
||||||
|
|
||||||
|
# Set up an experiment
|
||||||
|
from azureml.core import Experiment
|
||||||
|
experiment_name = 'my-experiment'
|
||||||
|
script_folder= "./"
|
||||||
|
|
||||||
|
exp = Experiment(workspace=ws, name=experiment_name)
|
||||||
|
|
||||||
|
|
||||||
|
#<run_temp_compute>
|
||||||
|
from azureml.core.compute import ComputeTarget, AmlCompute
|
||||||
|
|
||||||
|
# First, list the supported VM families for Azure Machine Learning Compute
|
||||||
|
print(AmlCompute.supported_vmsizes(workspace=ws))
|
||||||
|
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
# Create a new runconfig object
|
||||||
|
run_temp_compute = RunConfiguration()
|
||||||
|
|
||||||
|
# Signal that you want to use AmlCompute to execute the script
|
||||||
|
run_temp_compute.target = "amlcompute"
|
||||||
|
|
||||||
|
# AmlCompute is created in the same region as your workspace
|
||||||
|
# Set the VM size for AmlCompute from the list of supported_vmsizes
|
||||||
|
run_temp_compute.amlcompute.vm_size = 'STANDARD_D2_V2'
|
||||||
|
#</run_temp_compute>
|
||||||
|
|
||||||
|
|
||||||
|
# Submit the experiment using the run configuration
|
||||||
|
from azureml.core import ScriptRunConfig
|
||||||
|
|
||||||
|
src = ScriptRunConfig(source_directory = script_folder, script = 'train.py', run_config = run_temp_compute)
|
||||||
|
run = exp.submit(src)
|
||||||
|
run.wait_for_completion(show_output = True)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
70
ignore/doc-qa/how-to-set-up-training-targets/amlcompute2.py
Normal file
70
ignore/doc-qa/how-to-set-up-training-targets/amlcompute2.py
Normal file
@@ -0,0 +1,70 @@
|
|||||||
|
# Code for Azure Machine Learning Compute - Persistent compute
|
||||||
|
|
||||||
|
# Check core SDK version number
|
||||||
|
import azureml.core
|
||||||
|
|
||||||
|
print("SDK version:", azureml.core.VERSION)
|
||||||
|
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.from_config()
|
||||||
|
|
||||||
|
|
||||||
|
# Set up an experiment
|
||||||
|
from azureml.core import Experiment
|
||||||
|
experiment_name = 'my-experiment'
|
||||||
|
script_folder= "./"
|
||||||
|
|
||||||
|
exp = Experiment(workspace=ws, name=experiment_name)
|
||||||
|
|
||||||
|
#<cpu_cluster>
|
||||||
|
from azureml.core.compute import ComputeTarget, AmlCompute
|
||||||
|
from azureml.core.compute_target import ComputeTargetException
|
||||||
|
|
||||||
|
# Choose a name for your CPU cluster
|
||||||
|
cpu_cluster_name = "cpucluster"
|
||||||
|
|
||||||
|
# Verify that cluster does not exist already
|
||||||
|
try:
|
||||||
|
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
|
||||||
|
print('Found existing cluster, use it.')
|
||||||
|
except ComputeTargetException:
|
||||||
|
# To use a different region for the compute, add a location='<region>' parameter
|
||||||
|
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
|
||||||
|
max_nodes=4)
|
||||||
|
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
|
||||||
|
|
||||||
|
cpu_cluster.wait_for_completion(show_output=True)
|
||||||
|
#</cpu_cluster>
|
||||||
|
|
||||||
|
#<run_amlcompute>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
from azureml.core.runconfig import DEFAULT_CPU_IMAGE
|
||||||
|
|
||||||
|
# Create a new runconfig object
|
||||||
|
run_amlcompute = RunConfiguration()
|
||||||
|
|
||||||
|
# Use the cpu_cluster you created above.
|
||||||
|
run_amlcompute.target = cpu_cluster
|
||||||
|
|
||||||
|
# Enable Docker
|
||||||
|
run_amlcompute.environment.docker.enabled = True
|
||||||
|
|
||||||
|
# Set Docker base image to the default CPU-based image
|
||||||
|
run_amlcompute.environment.docker.base_image = DEFAULT_CPU_IMAGE
|
||||||
|
|
||||||
|
# Use conda_dependencies.yml to create a conda environment in the Docker image for execution
|
||||||
|
run_amlcompute.environment.python.user_managed_dependencies = False
|
||||||
|
|
||||||
|
# Specify CondaDependencies obj, add necessary packages
|
||||||
|
run_amlcompute.environment.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn'])
|
||||||
|
#</run_amlcompute>
|
||||||
|
|
||||||
|
# Submit the experiment using the run configuration
|
||||||
|
#<amlcompute_submit>
|
||||||
|
from azureml.core import ScriptRunConfig
|
||||||
|
|
||||||
|
src = ScriptRunConfig(source_directory = script_folder, script = 'train.py', run_config = run_amlcompute)
|
||||||
|
run = exp.submit(src)
|
||||||
|
run.wait_for_completion(show_output = True)
|
||||||
|
#</amlcompute_submit>
|
||||||
26
ignore/doc-qa/how-to-set-up-training-targets/dsvm.py
Normal file
26
ignore/doc-qa/how-to-set-up-training-targets/dsvm.py
Normal file
@@ -0,0 +1,26 @@
|
|||||||
|
# Code for Remote virtual machines
|
||||||
|
|
||||||
|
compute_target_name = "sheri-linuxvm"
|
||||||
|
|
||||||
|
#<run_dsvm>
|
||||||
|
import azureml.core
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
run_dsvm = RunConfiguration(framework = "python")
|
||||||
|
|
||||||
|
# Set the compute target to the Linux DSVM
|
||||||
|
run_dsvm.target = compute_target_name
|
||||||
|
|
||||||
|
# Use Docker in the remote VM
|
||||||
|
run_dsvm.environment.docker.enabled = True
|
||||||
|
|
||||||
|
# Use the CPU base image
|
||||||
|
# To use GPU in DSVM, you must also use the GPU base Docker image "azureml.core.runconfig.DEFAULT_GPU_IMAGE"
|
||||||
|
run_dsvm.environment.docker.base_image = azureml.core.runconfig.DEFAULT_CPU_IMAGE
|
||||||
|
print('Base Docker image is:', run_dsvm.environment.docker.base_image)
|
||||||
|
|
||||||
|
# Specify the CondaDependencies object
|
||||||
|
run_dsvm.environment.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn'])
|
||||||
|
#</run_dsvm>
|
||||||
|
print(run_dsvm)
|
||||||
27
ignore/doc-qa/how-to-set-up-training-targets/hdi.py
Normal file
27
ignore/doc-qa/how-to-set-up-training-targets/hdi.py
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.from_config()
|
||||||
|
|
||||||
|
from azureml.core.compute import ComputeTarget
|
||||||
|
|
||||||
|
# refers to an existing compute resource attached to the workspace!
|
||||||
|
hdi_compute = ComputeTarget(workspace=ws, name='sherihdi')
|
||||||
|
|
||||||
|
|
||||||
|
#<run_hdi>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
|
||||||
|
# use pyspark framework
|
||||||
|
run_hdi = RunConfiguration(framework="pyspark")
|
||||||
|
|
||||||
|
# Set compute target to the HDI cluster
|
||||||
|
run_hdi.target = hdi_compute.name
|
||||||
|
|
||||||
|
# specify CondaDependencies object to ask system installing numpy
|
||||||
|
cd = CondaDependencies()
|
||||||
|
cd.add_conda_package('numpy')
|
||||||
|
run_hdi.environment.python.conda_dependencies = cd
|
||||||
|
#</run_hdi>
|
||||||
|
print(run_hdi)
|
||||||
9
ignore/doc-qa/how-to-set-up-training-targets/mylib.py
Normal file
9
ignore/doc-qa/how-to-set-up-training-targets/mylib.py
Normal file
@@ -0,0 +1,9 @@
|
|||||||
|
# Copyright (c) Microsoft. All rights reserved.
|
||||||
|
# Licensed under the MIT license.
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
|
def get_alphas():
|
||||||
|
# list of numbers from 0.0 to 1.0 with a 0.05 interval
|
||||||
|
return np.arange(0.0, 1.0, 0.05)
|
||||||
52
ignore/doc-qa/how-to-set-up-training-targets/remote.py
Normal file
52
ignore/doc-qa/how-to-set-up-training-targets/remote.py
Normal file
@@ -0,0 +1,52 @@
|
|||||||
|
# Code for Remote virtual machines
|
||||||
|
|
||||||
|
compute_target_name = "attach-dsvm"
|
||||||
|
|
||||||
|
#<run_dsvm>
|
||||||
|
import azureml.core
|
||||||
|
from azureml.core.runconfig import RunConfiguration, DEFAULT_CPU_IMAGE
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
run_dsvm = RunConfiguration(framework = "python")
|
||||||
|
|
||||||
|
# Set the compute target to the Linux DSVM
|
||||||
|
run_dsvm.target = compute_target_name
|
||||||
|
|
||||||
|
# Use Docker in the remote VM
|
||||||
|
run_dsvm.environment.docker.enabled = True
|
||||||
|
|
||||||
|
# Use the CPU base image
|
||||||
|
# To use GPU in DSVM, you must also use the GPU base Docker image "azureml.core.runconfig.DEFAULT_GPU_IMAGE"
|
||||||
|
run_dsvm.environment.docker.base_image = azureml.core.runconfig.DEFAULT_CPU_IMAGE
|
||||||
|
print('Base Docker image is:', run_dsvm.environment.docker.base_image)
|
||||||
|
|
||||||
|
# Prepare the Docker and conda environment automatically when they're used for the first time
|
||||||
|
run_dsvm.prepare_environment = True
|
||||||
|
|
||||||
|
# Specify the CondaDependencies object
|
||||||
|
run_dsvm.environment.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn'])
|
||||||
|
#</run_dsvm>
|
||||||
|
hdi_compute.name = "blah"
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
|
||||||
|
# use pyspark framework
|
||||||
|
hdi_run_config = RunConfiguration(framework="pyspark")
|
||||||
|
|
||||||
|
# Set compute target to the HDI cluster
|
||||||
|
hdi_run_config.target = hdi_compute.name
|
||||||
|
|
||||||
|
# specify CondaDependencies object to ask system installing numpy
|
||||||
|
cd = CondaDependencies()
|
||||||
|
cd.add_conda_package('numpy')
|
||||||
|
hdi_run_config.environment.python.conda_dependencies = cd
|
||||||
|
|
||||||
|
#<run_hdi>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
# Configure the HDInsight run
|
||||||
|
# Load the runconfig object from the myhdi.runconfig file generated in the previous attach operation
|
||||||
|
run_hdi = RunConfiguration.load(project_object = project, run_name = 'myhdi')
|
||||||
|
|
||||||
|
# Ask the system to prepare the conda environment automatically when it's used for the first time
|
||||||
|
run_hdi.auto_prepare_environment = True>
|
||||||
25
ignore/doc-qa/how-to-set-up-training-targets/runconfig.py
Normal file
25
ignore/doc-qa/how-to-set-up-training-targets/runconfig.py
Normal file
@@ -0,0 +1,25 @@
|
|||||||
|
# Code for What's a run configuration
|
||||||
|
|
||||||
|
# <run_system_managed>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
from azureml.core.conda_dependencies import CondaDependencies
|
||||||
|
|
||||||
|
run_system_managed = RunConfiguration()
|
||||||
|
|
||||||
|
# Specify the conda dependencies with scikit-learn
|
||||||
|
run_system_managed.environment.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn'])
|
||||||
|
# </run_system_managed>
|
||||||
|
print(run_system_managed)
|
||||||
|
|
||||||
|
|
||||||
|
# <run_user_managed>
|
||||||
|
from azureml.core.runconfig import RunConfiguration
|
||||||
|
|
||||||
|
run_user_managed = RunConfiguration()
|
||||||
|
run_user_managed.environment.python.user_managed_dependencies = True
|
||||||
|
|
||||||
|
# Choose a specific Python environment by pointing to a Python path. For example:
|
||||||
|
# run_config.environment.python.interpreter_path = '/home/ninghai/miniconda3/envs/sdk2/bin/python'
|
||||||
|
# </run_user_managed>
|
||||||
|
print(run_user_managed)
|
||||||
|
|
||||||
45
ignore/doc-qa/how-to-set-up-training-targets/train.py
Normal file
45
ignore/doc-qa/how-to-set-up-training-targets/train.py
Normal file
@@ -0,0 +1,45 @@
|
|||||||
|
# Copyright (c) Microsoft. All rights reserved.
|
||||||
|
# Licensed under the MIT license.
|
||||||
|
|
||||||
|
from sklearn.datasets import load_diabetes
|
||||||
|
from sklearn.linear_model import Ridge
|
||||||
|
from sklearn.metrics import mean_squared_error
|
||||||
|
from sklearn.model_selection import train_test_split
|
||||||
|
from azureml.core.run import Run
|
||||||
|
from sklearn.externals import joblib
|
||||||
|
import os
|
||||||
|
import numpy as np
|
||||||
|
import mylib
|
||||||
|
|
||||||
|
os.makedirs('./outputs', exist_ok=True)
|
||||||
|
|
||||||
|
X, y = load_diabetes(return_X_y=True)
|
||||||
|
|
||||||
|
run = Run.get_context()
|
||||||
|
|
||||||
|
X_train, X_test, y_train, y_test = train_test_split(X, y,
|
||||||
|
test_size=0.2,
|
||||||
|
random_state=0)
|
||||||
|
data = {"train": {"X": X_train, "y": y_train},
|
||||||
|
"test": {"X": X_test, "y": y_test}}
|
||||||
|
|
||||||
|
# list of numbers from 0.0 to 1.0 with a 0.05 interval
|
||||||
|
alphas = mylib.get_alphas()
|
||||||
|
|
||||||
|
for alpha in alphas:
|
||||||
|
# Use Ridge algorithm to create a regression model
|
||||||
|
reg = Ridge(alpha=alpha)
|
||||||
|
reg.fit(data["train"]["X"], data["train"]["y"])
|
||||||
|
|
||||||
|
preds = reg.predict(data["test"]["X"])
|
||||||
|
mse = mean_squared_error(preds, data["test"]["y"])
|
||||||
|
run.log('alpha', alpha)
|
||||||
|
run.log('mse', mse)
|
||||||
|
|
||||||
|
model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha)
|
||||||
|
# save model in the outputs folder so it automatically get uploaded
|
||||||
|
with open(model_file_name, "wb") as file:
|
||||||
|
joblib.dump(value=reg, filename=os.path.join('./outputs/',
|
||||||
|
model_file_name))
|
||||||
|
|
||||||
|
print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))
|
||||||
@@ -0,0 +1,55 @@
|
|||||||
|
# code snippets for the quickstart-create-workspace-with-python article
|
||||||
|
# <import>
|
||||||
|
import azureml.core
|
||||||
|
print(azureml.core.VERSION)
|
||||||
|
# </import>
|
||||||
|
|
||||||
|
# this is NOT a snippet. If this code changes, go fix it in the article!
|
||||||
|
from azureml.core import Workspace
|
||||||
|
ws = Workspace.create(name='myworkspace',
|
||||||
|
subscription_id='<subscription-id>',
|
||||||
|
resource_group='myresourcegroup',
|
||||||
|
create_resource_group=True,
|
||||||
|
location='eastus2' # or other supported Azure region
|
||||||
|
)
|
||||||
|
|
||||||
|
# <getDetails>
|
||||||
|
ws.get_details()
|
||||||
|
# </getDetails>
|
||||||
|
|
||||||
|
# <writeConfig>
|
||||||
|
# Create the configuration file.
|
||||||
|
ws.write_config()
|
||||||
|
|
||||||
|
# Use this code to load the workspace from
|
||||||
|
# other scripts and notebooks in this directory.
|
||||||
|
# ws = Workspace.from_config()
|
||||||
|
# </writeConfig>
|
||||||
|
|
||||||
|
# <useWs>
|
||||||
|
from azureml.core import Experiment
|
||||||
|
|
||||||
|
# Create a new experiment in your workspace.
|
||||||
|
exp = Experiment(workspace=ws, name='myexp')
|
||||||
|
|
||||||
|
# Start a run and start the logging service.
|
||||||
|
run = exp.start_logging()
|
||||||
|
|
||||||
|
# Log a single number.
|
||||||
|
run.log('my magic number', 42)
|
||||||
|
|
||||||
|
# Log a list (Fibonacci numbers).
|
||||||
|
run.log_list('my list', [1, 1, 2, 3, 5, 8, 13, 21, 34, 55])
|
||||||
|
|
||||||
|
# Finish the run.
|
||||||
|
run.complete()
|
||||||
|
# </useWs>
|
||||||
|
|
||||||
|
# <viewLog>
|
||||||
|
print(run.get_portal_url())
|
||||||
|
# </viewLog>
|
||||||
|
|
||||||
|
|
||||||
|
# <delete>
|
||||||
|
ws.delete(delete_dependent_resources=True)
|
||||||
|
# </delete>
|
||||||
67
ignore/doc-qa/testnotebook.ipynb
Normal file
67
ignore/doc-qa/testnotebook.ipynb
Normal file
@@ -0,0 +1,67 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Testing notebook include"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 1,
|
||||||
|
"metadata": {
|
||||||
|
"name": "import"
|
||||||
|
},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"Azure ML SDK Version: 1.0.83\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"%matplotlib inline\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import matplotlib.pyplot as plt\n",
|
||||||
|
"\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"from azureml.core import Workspace\n",
|
||||||
|
"\n",
|
||||||
|
"# check core SDK version number\n",
|
||||||
|
"print(\"Azure ML SDK Version: \", azureml.core.VERSION)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"celltoolbar": "Edit Metadata",
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6 - AzureML",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python3-azureml"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.9"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 26 KiB |
@@ -1,14 +1,14 @@
|
|||||||
# ONNX on Azure Machine Learning
|
# ONNX on Azure Machine Learning
|
||||||
|
|
||||||
These tutorials show how to create and deploy [ONNX](http://onnx.ai) models in Azure Machine Learning environments using [ONNX Runtime](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-build-deploy-onnx) for inference. Once deployed as a web service, you can ping the model with your own set of images to be analyzed!
|
These tutorials show how to create and deploy [ONNX](http://onnx.ai) models using Azure Machine Learning and the [ONNX Runtime](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-build-deploy-onnx).
|
||||||
|
Once deployed as web services, you can ping the models with your own images to be analyzed!
|
||||||
|
|
||||||
## Tutorials
|
## Tutorials
|
||||||
- [Obtain ONNX model from ONNX Model Zoo and deploy with ONNX Runtime inference - Handwritten Digit Classification (MNIST)](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-inference-mnist-deploy.ipynb)
|
- [Obtain ONNX model from ONNX Model Zoo and deploy - ResNet50](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-modelzoo-aml-deploy-resnet50.ipynb)
|
||||||
- [Obtain ONNX model from ONNX Model Zoo and deploy with ONNX Runtime inference - Facial Expression Recognition (Emotion FER+)](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-inference-facial-emotion-recognition-deploy.ipynb)
|
|
||||||
- [Obtain ONNX model from ONNX Model Zoo and deploy with ONNX Runtime inference - Image Recognition (ResNet50)](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-modelzoo-aml-deploy-resnet50.ipynb)
|
|
||||||
- [Convert ONNX model from CoreML and deploy - TinyYOLO](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-convert-aml-deploy-tinyyolo.ipynb)
|
- [Convert ONNX model from CoreML and deploy - TinyYOLO](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-convert-aml-deploy-tinyyolo.ipynb)
|
||||||
- [Train ONNX model in PyTorch and deploy - MNIST](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-train-pytorch-aml-deploy-mnist.ipynb)
|
- [Train ONNX model in PyTorch and deploy - MNIST](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-train-pytorch-aml-deploy-mnist.ipynb)
|
||||||
|
- [Handwritten Digit Classification (MNIST) using ONNX Runtime on AzureML](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-inference-mnist.ipynb)
|
||||||
|
- [Facial Expression Recognition using ONNX Runtime on AzureML](https://github.com/Azure/MachineLearningNotebooks/blob/master/onnx/onnx-inference-emotion-recognition.ipynb)
|
||||||
|
|
||||||
## Documentation
|
## Documentation
|
||||||
- [ONNX Runtime Python API Documentation](http://aka.ms/onnxruntime-python)
|
- [ONNX Runtime Python API Documentation](http://aka.ms/onnxruntime-python)
|
||||||
@@ -21,8 +21,7 @@ These tutorials show how to create and deploy [ONNX](http://onnx.ai) models in A
|
|||||||
|
|
||||||
|
|
||||||
## License
|
## License
|
||||||
|
|
||||||
Copyright (c) Microsoft Corporation. All rights reserved.
|
Copyright (c) Microsoft Corporation. All rights reserved.
|
||||||
Licensed under the MIT License.
|
Licensed under the MIT License.
|
||||||
|
|
||||||
## Acknowledgements
|
|
||||||
These tutorials were developed by Vinitra Swamy and Prasanth Pulavarthi of the Microsoft AI Frameworks team and adapted for presentation at Microsoft Ignite 2018.
|
|
||||||
|
|||||||
@@ -59,9 +59,8 @@
|
|||||||
"You'll need to run the following commands to use this tutorial:\n",
|
"You'll need to run the following commands to use this tutorial:\n",
|
||||||
"\n",
|
"\n",
|
||||||
"```sh\n",
|
"```sh\n",
|
||||||
|
"pip install coremltools\n",
|
||||||
"pip install onnxmltools\n",
|
"pip install onnxmltools\n",
|
||||||
"pip install coremltools # use this on Linux and Mac\n",
|
|
||||||
"pip install git+https://github.com/apple/coremltools # use this on Windows\n",
|
|
||||||
"```"
|
"```"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -80,10 +79,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import urllib.request\n",
|
"!wget https://s3-us-west-2.amazonaws.com/coreml-models/TinyYOLO.mlmodel"
|
||||||
"\n",
|
|
||||||
"onnx_model_url = \"https://s3-us-west-2.amazonaws.com/coreml-models/TinyYOLO.mlmodel\"\n",
|
|
||||||
"urllib.request.urlretrieve(onnx_model_url, filename=\"TinyYOLO.mlmodel\")\n"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -177,9 +173,9 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"models = ws.models\n",
|
"models = ws.models()\n",
|
||||||
"for name, m in models.items():\n",
|
"for m in models:\n",
|
||||||
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
" print(\"Name:\", m.name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -248,7 +244,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
"\n",
|
"\n",
|
||||||
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\",\"azureml-core\"])\n",
|
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\"])\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
" f.write(myenv.serialize_to_string())"
|
" f.write(myenv.serialize_to_string())"
|
||||||
|
|||||||
812
onnx/onnx-inference-emotion-recognition.ipynb
Normal file
812
onnx/onnx-inference-emotion-recognition.ipynb
Normal file
@@ -0,0 +1,812 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Copyright (c) Microsoft Corporation. All rights reserved. \n",
|
||||||
|
"Licensed under the MIT License."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Facial Expression Recognition (Emotion FER+) using ONNX Runtime on Azure ML\n",
|
||||||
|
"\n",
|
||||||
|
"This example shows how to deploy an image classification neural network using the Facial Expression Recognition ([FER](https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data)) dataset and Open Neural Network eXchange format ([ONNX](http://aka.ms/onnxdocarticle)) on the Azure Machine Learning platform. This tutorial will show you how to deploy a FER+ model from the [ONNX model zoo](https://github.com/onnx/models), use it to make predictions using ONNX Runtime Inference, and deploy it as a web service in Azure.\n",
|
||||||
|
"\n",
|
||||||
|
"Throughout this tutorial, we will be referring to ONNX, a neural network exchange format used to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools (CNTK, PyTorch, Caffe, MXNet, TensorFlow) and choose the combination that is best for them. ONNX is developed and supported by a community of partners including Microsoft AI, Facebook, and Amazon. For more information, explore the [ONNX website](http://onnx.ai) and [open source files](https://github.com/onnx).\n",
|
||||||
|
"\n",
|
||||||
|
"[ONNX Runtime](https://aka.ms/onnxruntime-python) is the runtime engine that enables evaluation of trained machine learning (Traditional ML and Deep Learning) models with high performance and low resource utilization. We use the CPU version of ONNX Runtime in this tutorial, but will soon be releasing an additional tutorial for deploying this model using ONNX Runtime GPU.\n",
|
||||||
|
"\n",
|
||||||
|
"#### Tutorial Objectives:\n",
|
||||||
|
"\n",
|
||||||
|
"1. Describe the FER+ dataset and pretrained Convolutional Neural Net ONNX model for Emotion Recognition, stored in the ONNX model zoo.\n",
|
||||||
|
"2. Deploy and run the pretrained FER+ ONNX model on an Azure Machine Learning instance\n",
|
||||||
|
"3. Predict labels for test set data points in the cloud using ONNX Runtime and Azure ML"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Prerequisites\n",
|
||||||
|
"\n",
|
||||||
|
"### 1. Install Azure ML SDK and create a new workspace\n",
|
||||||
|
"Please follow [Azure ML configuration notebook](https://github.com/Azure/MachineLearningNotebooks/blob/master/00.configuration.ipynb) to set up your environment.\n",
|
||||||
|
"\n",
|
||||||
|
"### 2. Install additional packages needed for this Notebook\n",
|
||||||
|
"You need to install the popular plotting library `matplotlib`, the image manipulation library `opencv`, and the `onnx` library in the conda environment where Azure Maching Learning SDK is installed.\n",
|
||||||
|
"\n",
|
||||||
|
"```sh\n",
|
||||||
|
"(myenv) $ pip install matplotlib onnx opencv-python\n",
|
||||||
|
"```\n",
|
||||||
|
"\n",
|
||||||
|
"**Debugging tip**: Make sure that to activate your virtual environment (myenv) before you re-launch this notebook using the `jupyter notebook` comand. Choose the respective Python kernel for your new virtual environment using the `Kernel > Change Kernel` menu above. If you have completed the steps correctly, the upper right corner of your screen should state `Python [conda env:myenv]` instead of `Python [default]`.\n",
|
||||||
|
"\n",
|
||||||
|
"### 3. Download sample data and pre-trained ONNX model from ONNX Model Zoo.\n",
|
||||||
|
"\n",
|
||||||
|
"In the following lines of code, we download [the trained ONNX Emotion FER+ model and corresponding test data](https://github.com/onnx/models/tree/master/emotion_ferplus) and place them in the same folder as this tutorial notebook. For more information about the FER+ dataset, please visit Microsoft Researcher Emad Barsoum's [FER+ source data repository](https://github.com/ebarsoum/FERPlus)."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# urllib is a built-in Python library to download files from URLs\n",
|
||||||
|
"\n",
|
||||||
|
"# Objective: retrieve the latest version of the ONNX Emotion FER+ model files from the\n",
|
||||||
|
"# ONNX Model Zoo and save it in the same folder as this tutorial\n",
|
||||||
|
"\n",
|
||||||
|
"import urllib.request\n",
|
||||||
|
"\n",
|
||||||
|
"onnx_model_url = \"https://www.cntk.ai/OnnxModels/emotion_ferplus/opset_7/emotion_ferplus.tar.gz\"\n",
|
||||||
|
"\n",
|
||||||
|
"urllib.request.urlretrieve(onnx_model_url, filename=\"emotion_ferplus.tar.gz\")\n",
|
||||||
|
"\n",
|
||||||
|
"# the ! magic command tells our jupyter notebook kernel to run the following line of \n",
|
||||||
|
"# code from the command line instead of the notebook kernel\n",
|
||||||
|
"\n",
|
||||||
|
"# We use tar and xvcf to unzip the files we just retrieved from the ONNX model zoo\n",
|
||||||
|
"\n",
|
||||||
|
"!tar xvzf emotion_ferplus.tar.gz"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Deploy a VM with your ONNX model in the Cloud\n",
|
||||||
|
"\n",
|
||||||
|
"### Load Azure ML workspace\n",
|
||||||
|
"\n",
|
||||||
|
"We begin by instantiating a workspace object from the existing workspace created earlier in the configuration notebook."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Check core SDK version number\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"\n",
|
||||||
|
"print(\"SDK version:\", azureml.core.VERSION)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core import Workspace\n",
|
||||||
|
"\n",
|
||||||
|
"ws = Workspace.from_config()\n",
|
||||||
|
"print(ws.name, ws.location, ws.resource_group, sep = '\\n')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Registering your model with Azure ML"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"model_dir = \"emotion_ferplus\" # replace this with the location of your model files\n",
|
||||||
|
"\n",
|
||||||
|
"# leave as is if it's in the same folder as this notebook"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.model import Model\n",
|
||||||
|
"\n",
|
||||||
|
"model = Model.register(model_path = model_dir + \"/\" + \"model.onnx\",\n",
|
||||||
|
" model_name = \"onnx_emotion\",\n",
|
||||||
|
" tags = {\"onnx\": \"demo\"},\n",
|
||||||
|
" description = \"FER+ emotion recognition CNN from ONNX Model Zoo\",\n",
|
||||||
|
" workspace = ws)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Optional: Displaying your registered models\n",
|
||||||
|
"\n",
|
||||||
|
"This step is not required, so feel free to skip it."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"models = ws.models()\n",
|
||||||
|
"for name, m in models.items():\n",
|
||||||
|
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### ONNX FER+ Model Methodology\n",
|
||||||
|
"\n",
|
||||||
|
"The image classification model we are using is pre-trained using Microsoft's deep learning cognitive toolkit, [CNTK](https://github.com/Microsoft/CNTK), from the [ONNX model zoo](http://github.com/onnx/models). The model zoo has many other models that can be deployed on cloud providers like AzureML without any additional training. To ensure that our cloud deployed model works, we use testing data from the well-known FER+ data set, provided as part of the [trained Emotion Recognition model](https://github.com/onnx/models/tree/master/emotion_ferplus) in the ONNX model zoo.\n",
|
||||||
|
"\n",
|
||||||
|
"The original Facial Emotion Recognition (FER) Dataset was released in 2013 by Pierre-Luc Carrier and Aaron Courville as part of a [Kaggle Competition](https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data), but some of the labels are not entirely appropriate for the expression. In the FER+ Dataset, each photo was evaluated by at least 10 croud sourced reviewers, creating a more accurate basis for ground truth. \n",
|
||||||
|
"\n",
|
||||||
|
"You can see the difference of label quality in the sample model input below. The FER labels are the first word below each image, and the FER+ labels are the second word below each image.\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"***Input: Photos of cropped faces from FER+ Dataset***\n",
|
||||||
|
"\n",
|
||||||
|
"***Task: Classify each facial image into its appropriate emotions in the emotion table***\n",
|
||||||
|
"\n",
|
||||||
|
"``` emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, 'anger':4, 'disgust':5, 'fear':6, 'contempt':7} ```\n",
|
||||||
|
"\n",
|
||||||
|
"***Output: Emotion prediction for input image***\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"Remember, once the application is deployed in Azure ML, you can use your own images as input for the model to classify."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# for images and plots in this notebook\n",
|
||||||
|
"import matplotlib.pyplot as plt \n",
|
||||||
|
"from IPython.display import Image\n",
|
||||||
|
"\n",
|
||||||
|
"# display images inline\n",
|
||||||
|
"%matplotlib inline"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Model Description\n",
|
||||||
|
"\n",
|
||||||
|
"The FER+ model from the ONNX Model Zoo is summarized by the graphic below. You can see the entire workflow of our pre-trained model in the following image from Barsoum et. al's paper [\"Training Deep Networks for Facial Expression Recognition\n",
|
||||||
|
"with Crowd-Sourced Label Distribution\"](https://arxiv.org/pdf/1608.01041.pdf), with our (64 x 64) input images and our output probabilities for each of the labels."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"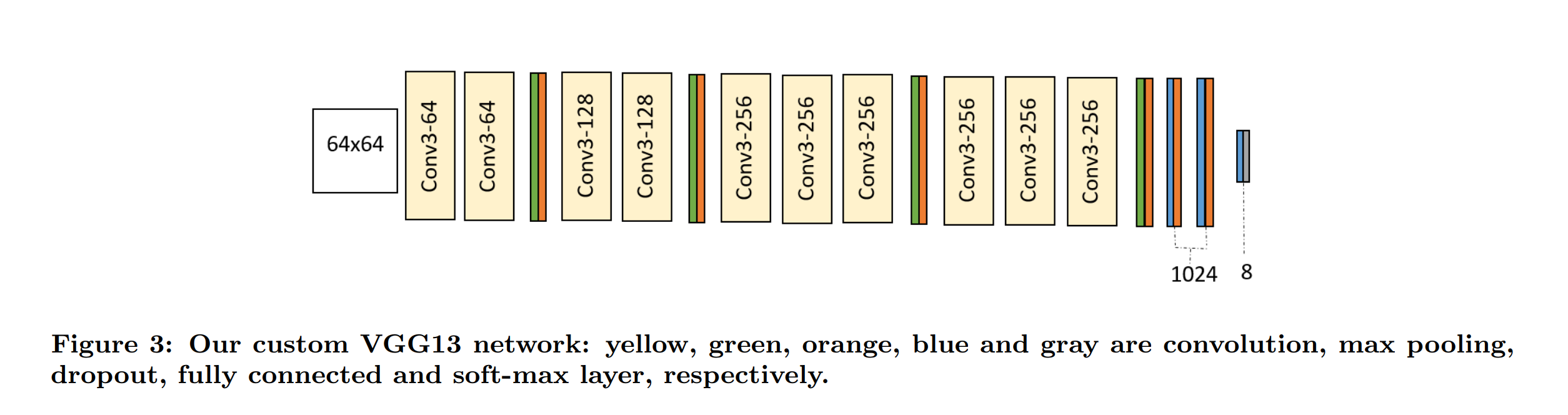"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Specify our Score and Environment Files"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"We are now going to deploy our ONNX Model on AML with inference in ONNX Runtime. We begin by writing a score.py file, which will help us run the model in our Azure ML virtual machine (VM), and then specify our environment by writing a yml file. You will also notice that we import the onnxruntime library to do runtime inference on our ONNX models (passing in input and evaluating out model's predicted output). More information on the API and commands can be found in the [ONNX Runtime documentation](https://aka.ms/onnxruntime).\n",
|
||||||
|
"\n",
|
||||||
|
"### Write Score File\n",
|
||||||
|
"\n",
|
||||||
|
"A score file is what tells our Azure cloud service what to do. After initializing our model using azureml.core.model, we start an ONNX Runtime inference session to evaluate the data passed in on our function calls."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"%%writefile score.py\n",
|
||||||
|
"import json\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import onnxruntime\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import os\n",
|
||||||
|
"from azureml.core.model import Model\n",
|
||||||
|
"import time\n",
|
||||||
|
"\n",
|
||||||
|
"def init():\n",
|
||||||
|
" global session, input_name, output_name\n",
|
||||||
|
" model = Model.get_model_path(model_name = 'onnx_emotion')\n",
|
||||||
|
" session = onnxruntime.InferenceSession(model, None)\n",
|
||||||
|
" input_name = session.get_inputs()[0].name\n",
|
||||||
|
" output_name = session.get_outputs()[0].name \n",
|
||||||
|
" \n",
|
||||||
|
"def run(input_data):\n",
|
||||||
|
" '''Purpose: evaluate test input in Azure Cloud using onnxruntime.\n",
|
||||||
|
" We will call the run function later from our Jupyter Notebook \n",
|
||||||
|
" so our azure service can evaluate our model input in the cloud. '''\n",
|
||||||
|
"\n",
|
||||||
|
" try:\n",
|
||||||
|
" # load in our data, convert to readable format\n",
|
||||||
|
" data = np.array(json.loads(input_data)['data']).astype('float32')\n",
|
||||||
|
" \n",
|
||||||
|
" start = time.time()\n",
|
||||||
|
" r = session.run([output_name], {input_name : data})\n",
|
||||||
|
" end = time.time()\n",
|
||||||
|
" \n",
|
||||||
|
" result = emotion_map(postprocess(r[0]))\n",
|
||||||
|
" \n",
|
||||||
|
" result_dict = {\"result\": result,\n",
|
||||||
|
" \"time_in_sec\": [end - start]}\n",
|
||||||
|
" except Exception as e:\n",
|
||||||
|
" result_dict = {\"error\": str(e)}\n",
|
||||||
|
" \n",
|
||||||
|
" return json.dumps(result_dict)\n",
|
||||||
|
"\n",
|
||||||
|
"def emotion_map(classes, N=1):\n",
|
||||||
|
" \"\"\"Take the most probable labels (output of postprocess) and returns the \n",
|
||||||
|
" top N emotional labels that fit the picture.\"\"\"\n",
|
||||||
|
" \n",
|
||||||
|
" emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, \n",
|
||||||
|
" 'anger':4, 'disgust':5, 'fear':6, 'contempt':7}\n",
|
||||||
|
" \n",
|
||||||
|
" emotion_keys = list(emotion_table.keys())\n",
|
||||||
|
" emotions = []\n",
|
||||||
|
" for i in range(N):\n",
|
||||||
|
" emotions.append(emotion_keys[classes[i]])\n",
|
||||||
|
" return emotions\n",
|
||||||
|
"\n",
|
||||||
|
"def softmax(x):\n",
|
||||||
|
" \"\"\"Compute softmax values (probabilities from 0 to 1) for each possible label.\"\"\"\n",
|
||||||
|
" x = x.reshape(-1)\n",
|
||||||
|
" e_x = np.exp(x - np.max(x))\n",
|
||||||
|
" return e_x / e_x.sum(axis=0)\n",
|
||||||
|
"\n",
|
||||||
|
"def postprocess(scores):\n",
|
||||||
|
" \"\"\"This function takes the scores generated by the network and \n",
|
||||||
|
" returns the class IDs in decreasing order of probability.\"\"\"\n",
|
||||||
|
" prob = softmax(scores)\n",
|
||||||
|
" prob = np.squeeze(prob)\n",
|
||||||
|
" classes = np.argsort(prob)[::-1]\n",
|
||||||
|
" return classes"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Write Environment File"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
|
"\n",
|
||||||
|
"myenv = CondaDependencies()\n",
|
||||||
|
"myenv.add_pip_package(\"numpy\")\n",
|
||||||
|
"myenv.add_pip_package(\"azureml-core\")\n",
|
||||||
|
"myenv.add_pip_package(\"onnxruntime\")\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
|
" f.write(myenv.serialize_to_string())"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Create the Container Image\n",
|
||||||
|
"\n",
|
||||||
|
"This step will likely take a few minutes."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.image import ContainerImage\n",
|
||||||
|
"\n",
|
||||||
|
"image_config = ContainerImage.image_configuration(execution_script = \"score.py\",\n",
|
||||||
|
" runtime = \"python\",\n",
|
||||||
|
" conda_file = \"myenv.yml\",\n",
|
||||||
|
" description = \"Emotion ONNX Runtime container\",\n",
|
||||||
|
" tags = {\"demo\": \"onnx\"})\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"image = ContainerImage.create(name = \"onnxtest\",\n",
|
||||||
|
" # this is the model object\n",
|
||||||
|
" models = [model],\n",
|
||||||
|
" image_config = image_config,\n",
|
||||||
|
" workspace = ws)\n",
|
||||||
|
"\n",
|
||||||
|
"image.wait_for_creation(show_output = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"In case you need to debug your code, the next line of code accesses the log file."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"print(image.image_build_log_uri)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"We're all done specifying what we want our virtual machine to do. Let's configure and deploy our container image.\n",
|
||||||
|
"\n",
|
||||||
|
"### Deploy the container image"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.webservice import AciWebservice\n",
|
||||||
|
"\n",
|
||||||
|
"aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1, \n",
|
||||||
|
" memory_gb = 1, \n",
|
||||||
|
" tags = {'demo': 'onnx'}, \n",
|
||||||
|
" description = 'ONNX for emotion recognition model')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.webservice import Webservice\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service_name = 'onnx-demo-emotion'\n",
|
||||||
|
"print(\"Service\", aci_service_name)\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service = Webservice.deploy_from_image(deployment_config = aciconfig,\n",
|
||||||
|
" image = image,\n",
|
||||||
|
" name = aci_service_name,\n",
|
||||||
|
" workspace = ws)\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service.wait_for_deployment(True)\n",
|
||||||
|
"print(aci_service.state)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"The following cell will likely take a few minutes to run as well."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"if aci_service.state != 'Healthy':\n",
|
||||||
|
" # run this command for debugging.\n",
|
||||||
|
" print(aci_service.get_logs())\n",
|
||||||
|
"\n",
|
||||||
|
" # If your deployment fails, make sure to delete your aci_service before trying again!\n",
|
||||||
|
" # aci_service.delete()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Success!\n",
|
||||||
|
"\n",
|
||||||
|
"If you've made it this far, you've deployed a working VM with a facial emotion recognition model running in the cloud using Azure ML. Congratulations!\n",
|
||||||
|
"\n",
|
||||||
|
"Let's see how well our model deals with our test images."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Testing and Evaluation\n",
|
||||||
|
"\n",
|
||||||
|
"### Useful Helper Functions\n",
|
||||||
|
"\n",
|
||||||
|
"We preprocess and postprocess our data (see score.py file) using the helper functions specified in the [ONNX FER+ Model page in the Model Zoo repository](https://github.com/onnx/models/tree/master/emotion_ferplus)."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"def emotion_map(classes, N=1):\n",
|
||||||
|
" \"\"\"Take the most probable labels (output of postprocess) and returns the \n",
|
||||||
|
" top N emotional labels that fit the picture.\"\"\"\n",
|
||||||
|
" \n",
|
||||||
|
" emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, \n",
|
||||||
|
" 'anger':4, 'disgust':5, 'fear':6, 'contempt':7}\n",
|
||||||
|
" \n",
|
||||||
|
" emotion_keys = list(emotion_table.keys())\n",
|
||||||
|
" emotions = []\n",
|
||||||
|
" for i in range(N):\n",
|
||||||
|
" emotions.append(emotion_keys[classes[i]])\n",
|
||||||
|
" \n",
|
||||||
|
" return emotions\n",
|
||||||
|
"\n",
|
||||||
|
"def softmax(x):\n",
|
||||||
|
" \"\"\"Compute softmax values (probabilities from 0 to 1) for each possible label.\"\"\"\n",
|
||||||
|
" x = x.reshape(-1)\n",
|
||||||
|
" e_x = np.exp(x - np.max(x))\n",
|
||||||
|
" return e_x / e_x.sum(axis=0)\n",
|
||||||
|
"\n",
|
||||||
|
"def postprocess(scores):\n",
|
||||||
|
" \"\"\"This function takes the scores generated by the network and \n",
|
||||||
|
" returns the class IDs in decreasing order of probability.\"\"\"\n",
|
||||||
|
" prob = softmax(scores)\n",
|
||||||
|
" prob = np.squeeze(prob)\n",
|
||||||
|
" classes = np.argsort(prob)[::-1]\n",
|
||||||
|
" return classes"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Load Test Data\n",
|
||||||
|
"\n",
|
||||||
|
"These are already in your directory from your ONNX model download (from the model zoo).\n",
|
||||||
|
"\n",
|
||||||
|
"Notice that our Model Zoo files have a .pb extension. This is because they are [protobuf files (Protocol Buffers)](https://developers.google.com/protocol-buffers/docs/pythontutorial), so we need to read in our data through our ONNX TensorProto reader into a format we can work with, like numerical arrays."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# to manipulate our arrays\n",
|
||||||
|
"import numpy as np \n",
|
||||||
|
"\n",
|
||||||
|
"# read in test data protobuf files included with the model\n",
|
||||||
|
"import onnx\n",
|
||||||
|
"from onnx import numpy_helper\n",
|
||||||
|
"\n",
|
||||||
|
"# to use parsers to read in our model/data\n",
|
||||||
|
"import json\n",
|
||||||
|
"import os\n",
|
||||||
|
"\n",
|
||||||
|
"test_inputs = []\n",
|
||||||
|
"test_outputs = []\n",
|
||||||
|
"\n",
|
||||||
|
"# read in 3 testing images from .pb files\n",
|
||||||
|
"test_data_size = 3\n",
|
||||||
|
"\n",
|
||||||
|
"for i in np.arange(test_data_size):\n",
|
||||||
|
" input_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'input_0.pb')\n",
|
||||||
|
" output_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'output_0.pb')\n",
|
||||||
|
" \n",
|
||||||
|
" # convert protobuf tensors to np arrays using the TensorProto reader from ONNX\n",
|
||||||
|
" tensor = onnx.TensorProto()\n",
|
||||||
|
" with open(input_test_data, 'rb') as f:\n",
|
||||||
|
" tensor.ParseFromString(f.read())\n",
|
||||||
|
" \n",
|
||||||
|
" input_data = numpy_helper.to_array(tensor)\n",
|
||||||
|
" test_inputs.append(input_data)\n",
|
||||||
|
" \n",
|
||||||
|
" with open(output_test_data, 'rb') as f:\n",
|
||||||
|
" tensor.ParseFromString(f.read())\n",
|
||||||
|
" \n",
|
||||||
|
" output_data = numpy_helper.to_array(tensor)\n",
|
||||||
|
" output_processed = emotion_map(postprocess(output_data))[0]\n",
|
||||||
|
" test_outputs.append(output_processed)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {
|
||||||
|
"nbpresent": {
|
||||||
|
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"source": [
|
||||||
|
"### Show some sample images\n",
|
||||||
|
"We use `matplotlib` to plot 3 test images from the dataset."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {
|
||||||
|
"nbpresent": {
|
||||||
|
"id": "396d478b-34aa-4afa-9898-cdce8222a516"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"plt.figure(figsize = (20, 20))\n",
|
||||||
|
"for test_image in np.arange(3):\n",
|
||||||
|
" test_inputs[test_image].reshape(1, 64, 64)\n",
|
||||||
|
" plt.subplot(1, 8, test_image+1)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
" plt.text(x = 10, y = -10, s = test_outputs[test_image], fontsize = 18)\n",
|
||||||
|
" plt.imshow(test_inputs[test_image].reshape(64, 64), cmap = plt.cm.gray)\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Run evaluation / prediction"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"plt.figure(figsize = (16, 6), frameon=False)\n",
|
||||||
|
"plt.subplot(1, 8, 1)\n",
|
||||||
|
"\n",
|
||||||
|
"plt.text(x = 0, y = -30, s = \"True Label: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 0, y = -20, s = \"Result: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 0, y = -10, s = \"Inference Time: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 3, y = 14, s = \"Model Input\", fontsize = 12, color = 'black')\n",
|
||||||
|
"plt.text(x = 6, y = 18, s = \"(64 x 64)\", fontsize = 12, color = 'black')\n",
|
||||||
|
"plt.imshow(np.ones((28,28)), cmap=plt.cm.Greys) \n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"for i in np.arange(test_data_size):\n",
|
||||||
|
" \n",
|
||||||
|
" input_data = json.dumps({'data': test_inputs[i].tolist()})\n",
|
||||||
|
"\n",
|
||||||
|
" # predict using the deployed model\n",
|
||||||
|
" r = json.loads(aci_service.run(input_data))\n",
|
||||||
|
" \n",
|
||||||
|
" if \"error\" in r:\n",
|
||||||
|
" print(r['error'])\n",
|
||||||
|
" break\n",
|
||||||
|
" \n",
|
||||||
|
" result = r['result'][0]\n",
|
||||||
|
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
||||||
|
" \n",
|
||||||
|
" ground_truth = test_outputs[i]\n",
|
||||||
|
" \n",
|
||||||
|
" # compare actual value vs. the predicted values:\n",
|
||||||
|
" plt.subplot(1, 8, i+2)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
"\n",
|
||||||
|
" # use different color for misclassified sample\n",
|
||||||
|
" font_color = 'red' if ground_truth != result else 'black'\n",
|
||||||
|
" clr_map = plt.cm.Greys if ground_truth != result else plt.cm.gray\n",
|
||||||
|
"\n",
|
||||||
|
" # ground truth labels are in blue\n",
|
||||||
|
" plt.text(x = 10, y = -70, s = ground_truth, fontsize = 18, color = 'blue')\n",
|
||||||
|
" \n",
|
||||||
|
" # predictions are in black if correct, red if incorrect\n",
|
||||||
|
" plt.text(x = 10, y = -45, s = result, fontsize = 18, color = font_color)\n",
|
||||||
|
" plt.text(x = 5, y = -22, s = str(time_ms) + ' ms', fontsize = 14, color = font_color)\n",
|
||||||
|
"\n",
|
||||||
|
" \n",
|
||||||
|
" plt.imshow(test_inputs[i].reshape(64, 64), cmap = clr_map)\n",
|
||||||
|
"\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Try classifying your own images!"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Preprocessing functions take your image and format it so it can be passed\n",
|
||||||
|
"# as input into our ONNX model\n",
|
||||||
|
"\n",
|
||||||
|
"import cv2\n",
|
||||||
|
"\n",
|
||||||
|
"def rgb2gray(rgb):\n",
|
||||||
|
" \"\"\"Convert the input image into grayscale\"\"\"\n",
|
||||||
|
" return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])\n",
|
||||||
|
"\n",
|
||||||
|
"def resize_img(img):\n",
|
||||||
|
" \"\"\"Resize image to MNIST model input dimensions\"\"\"\n",
|
||||||
|
" img = cv2.resize(img, dsize=(64, 64), interpolation=cv2.INTER_AREA)\n",
|
||||||
|
" img.resize((1, 1, 64, 64))\n",
|
||||||
|
" return img\n",
|
||||||
|
"\n",
|
||||||
|
"def preprocess(img):\n",
|
||||||
|
" \"\"\"Resize input images and convert them to grayscale.\"\"\"\n",
|
||||||
|
" if img.shape == (64, 64):\n",
|
||||||
|
" img.resize((1, 1, 64, 64))\n",
|
||||||
|
" return img\n",
|
||||||
|
" \n",
|
||||||
|
" grayscale = rgb2gray(img)\n",
|
||||||
|
" processed_img = resize_img(grayscale)\n",
|
||||||
|
" return processed_img"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Replace the following string with your own path/test image\n",
|
||||||
|
"# Make sure your image is square and the dimensions are equal (i.e. 100 * 100 pixels or 28 * 28 pixels)\n",
|
||||||
|
"\n",
|
||||||
|
"# Any PNG or JPG image file should work\n",
|
||||||
|
"# Make sure to include the entire path with // instead of /\n",
|
||||||
|
"\n",
|
||||||
|
"# e.g. your_test_image = \"C://Users//vinitra.swamy//Pictures//emotion_test_images//img_1.png\"\n",
|
||||||
|
"\n",
|
||||||
|
"import matplotlib.image as mpimg\n",
|
||||||
|
"\n",
|
||||||
|
"if your_test_image != \"<path to file>\":\n",
|
||||||
|
" img = mpimg.imread(your_test_image)\n",
|
||||||
|
" plt.subplot(1,3,1)\n",
|
||||||
|
" plt.imshow(img, cmap = plt.cm.Greys)\n",
|
||||||
|
" print(\"Old Dimensions: \", img.shape)\n",
|
||||||
|
" img = preprocess(img)\n",
|
||||||
|
" print(\"New Dimensions: \", img.shape)\n",
|
||||||
|
"else:\n",
|
||||||
|
" img = None"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"if img is None:\n",
|
||||||
|
" print(\"Add the path for your image data.\")\n",
|
||||||
|
"else:\n",
|
||||||
|
" input_data = json.dumps({'data': img.tolist()})\n",
|
||||||
|
"\n",
|
||||||
|
" try:\n",
|
||||||
|
" r = json.loads(aci_service.run(input_data))\n",
|
||||||
|
" result = r['result'][0]\n",
|
||||||
|
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
||||||
|
" except Exception as e:\n",
|
||||||
|
" print(str(e))\n",
|
||||||
|
"\n",
|
||||||
|
" plt.figure(figsize = (16, 6))\n",
|
||||||
|
" plt.subplot(1,8,1)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
" plt.text(x = -10, y = -40, s = \"Model prediction: \", fontsize = 14)\n",
|
||||||
|
" plt.text(x = -10, y = -25, s = \"Inference time: \", fontsize = 14)\n",
|
||||||
|
" plt.text(x = 100, y = -40, s = str(result), fontsize = 14)\n",
|
||||||
|
" plt.text(x = 100, y = -25, s = str(time_ms) + \" ms\", fontsize = 14)\n",
|
||||||
|
" plt.text(x = -10, y = -10, s = \"Model Input image: \", fontsize = 14)\n",
|
||||||
|
" plt.imshow(img.reshape((64, 64)), cmap = plt.cm.gray) \n",
|
||||||
|
" "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# remember to delete your service after you are done using it!\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service.delete()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Conclusion\n",
|
||||||
|
"\n",
|
||||||
|
"Congratulations!\n",
|
||||||
|
"\n",
|
||||||
|
"In this tutorial, you have:\n",
|
||||||
|
"- familiarized yourself with ONNX Runtime inference and the pretrained models in the ONNX model zoo\n",
|
||||||
|
"- understood a state-of-the-art convolutional neural net image classification model (FER+ in ONNX) and deployed it in the Azure ML cloud\n",
|
||||||
|
"- ensured that your deep learning model is working perfectly (in the cloud) on test data, and checked it against some of your own!\n",
|
||||||
|
"\n",
|
||||||
|
"Next steps:\n",
|
||||||
|
"- If you have not already, check out another interesting ONNX/AML application that lets you set up a state-of-the-art [handwritten image classification model (MNIST)](https://github.com/Azure/MachineLearningNotebooks/tree/master/onnx/onnx-inference-mnist.ipynb) in the cloud! This tutorial deploys a pre-trained ONNX Computer Vision model for handwritten digit classification in an Azure ML virtual machine.\n",
|
||||||
|
"- Keep an eye out for an updated version of this tutorial that uses ONNX Runtime GPU.\n",
|
||||||
|
"- Contribute to our [open source ONNX repository on github](http://github.com/onnx/onnx) and/or add to our [ONNX model zoo](http://github.com/onnx/models)"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"authors": [
|
||||||
|
{
|
||||||
|
"name": "viswamy"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python36"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.6"
|
||||||
|
},
|
||||||
|
"msauthor": "vinitra.swamy"
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -1,809 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved. \n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# Facial Expression Recognition (FER+) using ONNX Runtime on Azure ML\n",
|
|
||||||
"\n",
|
|
||||||
"This example shows how to deploy an image classification neural network using the Facial Expression Recognition ([FER](https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data)) dataset and Open Neural Network eXchange format ([ONNX](http://aka.ms/onnxdocarticle)) on the Azure Machine Learning platform. This tutorial will show you how to deploy a FER+ model from the [ONNX model zoo](https://github.com/onnx/models), use it to make predictions using ONNX Runtime Inference, and deploy it as a web service in Azure.\n",
|
|
||||||
"\n",
|
|
||||||
"Throughout this tutorial, we will be referring to ONNX, a neural network exchange format used to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools (CNTK, PyTorch, Caffe, MXNet, TensorFlow) and choose the combination that is best for them. ONNX is developed and supported by a community of partners including Microsoft AI, Facebook, and Amazon. For more information, explore the [ONNX website](http://onnx.ai) and [open source files](https://github.com/onnx).\n",
|
|
||||||
"\n",
|
|
||||||
"[ONNX Runtime](https://aka.ms/onnxruntime-python) is the runtime engine that enables evaluation of trained machine learning (Traditional ML and Deep Learning) models with high performance and low resource utilization. We use the CPU version of ONNX Runtime in this tutorial, but will soon be releasing an additional tutorial for deploying this model using ONNX Runtime GPU.\n",
|
|
||||||
"\n",
|
|
||||||
"#### Tutorial Objectives:\n",
|
|
||||||
"\n",
|
|
||||||
"1. Describe the FER+ dataset and pretrained Convolutional Neural Net ONNX model for Emotion Recognition, stored in the ONNX model zoo.\n",
|
|
||||||
"2. Deploy and run the pretrained FER+ ONNX model on an Azure Machine Learning instance\n",
|
|
||||||
"3. Predict labels for test set data points in the cloud using ONNX Runtime and Azure ML"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Prerequisites\n",
|
|
||||||
"\n",
|
|
||||||
"### 1. Install Azure ML SDK and create a new workspace\n",
|
|
||||||
"Please follow [Azure ML configuration notebook](https://github.com/Azure/MachineLearningNotebooks/blob/master/00.configuration.ipynb) to set up your environment.\n",
|
|
||||||
"\n",
|
|
||||||
"### 2. Install additional packages needed for this Notebook\n",
|
|
||||||
"You need to install the popular plotting library `matplotlib`, the image manipulation library `opencv`, and the `onnx` library in the conda environment where Azure Maching Learning SDK is installed.\n",
|
|
||||||
"\n",
|
|
||||||
"```sh\n",
|
|
||||||
"(myenv) $ pip install matplotlib onnx opencv-python\n",
|
|
||||||
"```\n",
|
|
||||||
"\n",
|
|
||||||
"**Debugging tip**: Make sure that to activate your virtual environment (myenv) before you re-launch this notebook using the `jupyter notebook` comand. Choose the respective Python kernel for your new virtual environment using the `Kernel > Change Kernel` menu above. If you have completed the steps correctly, the upper right corner of your screen should state `Python [conda env:myenv]` instead of `Python [default]`.\n",
|
|
||||||
"\n",
|
|
||||||
"### 3. Download sample data and pre-trained ONNX model from ONNX Model Zoo.\n",
|
|
||||||
"\n",
|
|
||||||
"In the following lines of code, we download [the trained ONNX Emotion FER+ model and corresponding test data](https://github.com/onnx/models/tree/master/emotion_ferplus) and place them in the same folder as this tutorial notebook. For more information about the FER+ dataset, please visit Microsoft Researcher Emad Barsoum's [FER+ source data repository](https://github.com/ebarsoum/FERPlus)."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# urllib is a built-in Python library to download files from URLs\n",
|
|
||||||
"\n",
|
|
||||||
"# Objective: retrieve the latest version of the ONNX Emotion FER+ model files from the\n",
|
|
||||||
"# ONNX Model Zoo and save it in the same folder as this tutorial\n",
|
|
||||||
"\n",
|
|
||||||
"import urllib.request\n",
|
|
||||||
"\n",
|
|
||||||
"onnx_model_url = \"https://www.cntk.ai/OnnxModels/emotion_ferplus/opset_7/emotion_ferplus.tar.gz\"\n",
|
|
||||||
"\n",
|
|
||||||
"urllib.request.urlretrieve(onnx_model_url, filename=\"emotion_ferplus.tar.gz\")\n",
|
|
||||||
"\n",
|
|
||||||
"# the ! magic command tells our jupyter notebook kernel to run the following line of \n",
|
|
||||||
"# code from the command line instead of the notebook kernel\n",
|
|
||||||
"\n",
|
|
||||||
"# We use tar and xvcf to unzip the files we just retrieved from the ONNX model zoo\n",
|
|
||||||
"\n",
|
|
||||||
"!tar xvzf emotion_ferplus.tar.gz"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Deploy a VM with your ONNX model in the Cloud\n",
|
|
||||||
"\n",
|
|
||||||
"### Load Azure ML workspace\n",
|
|
||||||
"\n",
|
|
||||||
"We begin by instantiating a workspace object from the existing workspace created earlier in the configuration notebook."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Check core SDK version number\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"\n",
|
|
||||||
"print(\"SDK version:\", azureml.core.VERSION)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core import Workspace\n",
|
|
||||||
"\n",
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"print(ws.name, ws.location, ws.resource_group, sep = '\\n')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Registering your model with Azure ML"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"model_dir = \"emotion_ferplus\" # replace this with the location of your model files\n",
|
|
||||||
"\n",
|
|
||||||
"# leave as is if it's in the same folder as this notebook"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.model import Model\n",
|
|
||||||
"\n",
|
|
||||||
"model = Model.register(model_path = model_dir + \"/\" + \"model.onnx\",\n",
|
|
||||||
" model_name = \"onnx_emotion\",\n",
|
|
||||||
" tags = {\"onnx\": \"demo\"},\n",
|
|
||||||
" description = \"FER+ emotion recognition CNN from ONNX Model Zoo\",\n",
|
|
||||||
" workspace = ws)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Optional: Displaying your registered models\n",
|
|
||||||
"\n",
|
|
||||||
"This step is not required, so feel free to skip it."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"models = ws.models\n",
|
|
||||||
"for name, m in models.items():\n",
|
|
||||||
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### ONNX FER+ Model Methodology\n",
|
|
||||||
"\n",
|
|
||||||
"The image classification model we are using is pre-trained using Microsoft's deep learning cognitive toolkit, [CNTK](https://github.com/Microsoft/CNTK), from the [ONNX model zoo](http://github.com/onnx/models). The model zoo has many other models that can be deployed on cloud providers like AzureML without any additional training. To ensure that our cloud deployed model works, we use testing data from the well-known FER+ data set, provided as part of the [trained Emotion Recognition model](https://github.com/onnx/models/tree/master/emotion_ferplus) in the ONNX model zoo.\n",
|
|
||||||
"\n",
|
|
||||||
"The original Facial Emotion Recognition (FER) Dataset was released in 2013 by Pierre-Luc Carrier and Aaron Courville as part of a [Kaggle Competition](https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data), but some of the labels are not entirely appropriate for the expression. In the FER+ Dataset, each photo was evaluated by at least 10 croud sourced reviewers, creating a more accurate basis for ground truth. \n",
|
|
||||||
"\n",
|
|
||||||
"You can see the difference of label quality in the sample model input below. The FER labels are the first word below each image, and the FER+ labels are the second word below each image.\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"***Input: Photos of cropped faces from FER+ Dataset***\n",
|
|
||||||
"\n",
|
|
||||||
"***Task: Classify each facial image into its appropriate emotions in the emotion table***\n",
|
|
||||||
"\n",
|
|
||||||
"``` emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, 'anger':4, 'disgust':5, 'fear':6, 'contempt':7} ```\n",
|
|
||||||
"\n",
|
|
||||||
"***Output: Emotion prediction for input image***\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"Remember, once the application is deployed in Azure ML, you can use your own images as input for the model to classify."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# for images and plots in this notebook\n",
|
|
||||||
"import matplotlib.pyplot as plt \n",
|
|
||||||
"from IPython.display import Image\n",
|
|
||||||
"\n",
|
|
||||||
"# display images inline\n",
|
|
||||||
"%matplotlib inline"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Model Description\n",
|
|
||||||
"\n",
|
|
||||||
"The FER+ model from the ONNX Model Zoo is summarized by the graphic below. You can see the entire workflow of our pre-trained model in the following image from Barsoum et. al's paper [\"Training Deep Networks for Facial Expression Recognition\n",
|
|
||||||
"with Crowd-Sourced Label Distribution\"](https://arxiv.org/pdf/1608.01041.pdf), with our (64 x 64) input images and our output probabilities for each of the labels."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
""
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Specify our Score and Environment Files"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"We are now going to deploy our ONNX Model on AML with inference in ONNX Runtime. We begin by writing a score.py file, which will help us run the model in our Azure ML virtual machine (VM), and then specify our environment by writing a yml file. You will also notice that we import the onnxruntime library to do runtime inference on our ONNX models (passing in input and evaluating out model's predicted output). More information on the API and commands can be found in the [ONNX Runtime documentation](https://aka.ms/onnxruntime).\n",
|
|
||||||
"\n",
|
|
||||||
"### Write Score File\n",
|
|
||||||
"\n",
|
|
||||||
"A score file is what tells our Azure cloud service what to do. After initializing our model using azureml.core.model, we start an ONNX Runtime inference session to evaluate the data passed in on our function calls."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%%writefile score.py\n",
|
|
||||||
"import json\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import onnxruntime\n",
|
|
||||||
"import sys\n",
|
|
||||||
"import os\n",
|
|
||||||
"from azureml.core.model import Model\n",
|
|
||||||
"import time\n",
|
|
||||||
"\n",
|
|
||||||
"def init():\n",
|
|
||||||
" global session, input_name, output_name\n",
|
|
||||||
" model = Model.get_model_path(model_name = 'onnx_emotion')\n",
|
|
||||||
" session = onnxruntime.InferenceSession(model, None)\n",
|
|
||||||
" input_name = session.get_inputs()[0].name\n",
|
|
||||||
" output_name = session.get_outputs()[0].name \n",
|
|
||||||
" \n",
|
|
||||||
"def run(input_data):\n",
|
|
||||||
" '''Purpose: evaluate test input in Azure Cloud using onnxruntime.\n",
|
|
||||||
" We will call the run function later from our Jupyter Notebook \n",
|
|
||||||
" so our azure service can evaluate our model input in the cloud. '''\n",
|
|
||||||
"\n",
|
|
||||||
" try:\n",
|
|
||||||
" # load in our data, convert to readable format\n",
|
|
||||||
" data = np.array(json.loads(input_data)['data']).astype('float32')\n",
|
|
||||||
" \n",
|
|
||||||
" start = time.time()\n",
|
|
||||||
" r = session.run([output_name], {input_name : data})\n",
|
|
||||||
" end = time.time()\n",
|
|
||||||
" \n",
|
|
||||||
" result = emotion_map(postprocess(r[0]))\n",
|
|
||||||
" \n",
|
|
||||||
" result_dict = {\"result\": result,\n",
|
|
||||||
" \"time_in_sec\": [end - start]}\n",
|
|
||||||
" except Exception as e:\n",
|
|
||||||
" result_dict = {\"error\": str(e)}\n",
|
|
||||||
" \n",
|
|
||||||
" return json.dumps(result_dict)\n",
|
|
||||||
"\n",
|
|
||||||
"def emotion_map(classes, N=1):\n",
|
|
||||||
" \"\"\"Take the most probable labels (output of postprocess) and returns the \n",
|
|
||||||
" top N emotional labels that fit the picture.\"\"\"\n",
|
|
||||||
" \n",
|
|
||||||
" emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, \n",
|
|
||||||
" 'anger':4, 'disgust':5, 'fear':6, 'contempt':7}\n",
|
|
||||||
" \n",
|
|
||||||
" emotion_keys = list(emotion_table.keys())\n",
|
|
||||||
" emotions = []\n",
|
|
||||||
" for i in range(N):\n",
|
|
||||||
" emotions.append(emotion_keys[classes[i]])\n",
|
|
||||||
" return emotions\n",
|
|
||||||
"\n",
|
|
||||||
"def softmax(x):\n",
|
|
||||||
" \"\"\"Compute softmax values (probabilities from 0 to 1) for each possible label.\"\"\"\n",
|
|
||||||
" x = x.reshape(-1)\n",
|
|
||||||
" e_x = np.exp(x - np.max(x))\n",
|
|
||||||
" return e_x / e_x.sum(axis=0)\n",
|
|
||||||
"\n",
|
|
||||||
"def postprocess(scores):\n",
|
|
||||||
" \"\"\"This function takes the scores generated by the network and \n",
|
|
||||||
" returns the class IDs in decreasing order of probability.\"\"\"\n",
|
|
||||||
" prob = softmax(scores)\n",
|
|
||||||
" prob = np.squeeze(prob)\n",
|
|
||||||
" classes = np.argsort(prob)[::-1]\n",
|
|
||||||
" return classes"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Write Environment File"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
|
||||||
"\n",
|
|
||||||
"myenv = CondaDependencies.create(pip_packages=[\"numpy\", \"onnxruntime\", \"azureml-core\"])\n",
|
|
||||||
"\n",
|
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
|
||||||
" f.write(myenv.serialize_to_string())"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Create the Container Image\n",
|
|
||||||
"\n",
|
|
||||||
"This step will likely take a few minutes."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.image import ContainerImage\n",
|
|
||||||
"\n",
|
|
||||||
"image_config = ContainerImage.image_configuration(execution_script = \"score.py\",\n",
|
|
||||||
" runtime = \"python\",\n",
|
|
||||||
" conda_file = \"myenv.yml\",\n",
|
|
||||||
" description = \"Emotion ONNX Runtime container\",\n",
|
|
||||||
" tags = {\"demo\": \"onnx\"})\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"image = ContainerImage.create(name = \"onnximage\",\n",
|
|
||||||
" # this is the model object\n",
|
|
||||||
" models = [model],\n",
|
|
||||||
" image_config = image_config,\n",
|
|
||||||
" workspace = ws)\n",
|
|
||||||
"\n",
|
|
||||||
"image.wait_for_creation(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"In case you need to debug your code, the next line of code accesses the log file."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(image.image_build_log_uri)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"We're all done specifying what we want our virtual machine to do. Let's configure and deploy our container image.\n",
|
|
||||||
"\n",
|
|
||||||
"### Deploy the container image"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.webservice import AciWebservice\n",
|
|
||||||
"\n",
|
|
||||||
"aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1, \n",
|
|
||||||
" memory_gb = 1, \n",
|
|
||||||
" tags = {'demo': 'onnx'}, \n",
|
|
||||||
" description = 'ONNX for emotion recognition model')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.webservice import Webservice\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service_name = 'onnx-demo-emotion'\n",
|
|
||||||
"print(\"Service\", aci_service_name)\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service = Webservice.deploy_from_image(deployment_config = aciconfig,\n",
|
|
||||||
" image = image,\n",
|
|
||||||
" name = aci_service_name,\n",
|
|
||||||
" workspace = ws)\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service.wait_for_deployment(True)\n",
|
|
||||||
"print(aci_service.state)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"The following cell will likely take a few minutes to run as well."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if aci_service.state != 'Healthy':\n",
|
|
||||||
" # run this command for debugging.\n",
|
|
||||||
" print(aci_service.get_logs())\n",
|
|
||||||
"\n",
|
|
||||||
" # If your deployment fails, make sure to delete your aci_service before trying again!\n",
|
|
||||||
" # aci_service.delete()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Success!\n",
|
|
||||||
"\n",
|
|
||||||
"If you've made it this far, you've deployed a working VM with a facial emotion recognition model running in the cloud using Azure ML. Congratulations!\n",
|
|
||||||
"\n",
|
|
||||||
"Let's see how well our model deals with our test images."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Testing and Evaluation\n",
|
|
||||||
"\n",
|
|
||||||
"### Useful Helper Functions\n",
|
|
||||||
"\n",
|
|
||||||
"We preprocess and postprocess our data (see score.py file) using the helper functions specified in the [ONNX FER+ Model page in the Model Zoo repository](https://github.com/onnx/models/tree/master/emotion_ferplus)."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"def emotion_map(classes, N=1):\n",
|
|
||||||
" \"\"\"Take the most probable labels (output of postprocess) and returns the \n",
|
|
||||||
" top N emotional labels that fit the picture.\"\"\"\n",
|
|
||||||
" \n",
|
|
||||||
" emotion_table = {'neutral':0, 'happiness':1, 'surprise':2, 'sadness':3, \n",
|
|
||||||
" 'anger':4, 'disgust':5, 'fear':6, 'contempt':7}\n",
|
|
||||||
" \n",
|
|
||||||
" emotion_keys = list(emotion_table.keys())\n",
|
|
||||||
" emotions = []\n",
|
|
||||||
" for i in range(N):\n",
|
|
||||||
" emotions.append(emotion_keys[classes[i]])\n",
|
|
||||||
" return emotions\n",
|
|
||||||
"\n",
|
|
||||||
"def softmax(x):\n",
|
|
||||||
" \"\"\"Compute softmax values (probabilities from 0 to 1) for each possible label.\"\"\"\n",
|
|
||||||
" x = x.reshape(-1)\n",
|
|
||||||
" e_x = np.exp(x - np.max(x))\n",
|
|
||||||
" return e_x / e_x.sum(axis=0)\n",
|
|
||||||
"\n",
|
|
||||||
"def postprocess(scores):\n",
|
|
||||||
" \"\"\"This function takes the scores generated by the network and \n",
|
|
||||||
" returns the class IDs in decreasing order of probability.\"\"\"\n",
|
|
||||||
" prob = softmax(scores)\n",
|
|
||||||
" prob = np.squeeze(prob)\n",
|
|
||||||
" classes = np.argsort(prob)[::-1]\n",
|
|
||||||
" return classes"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Load Test Data\n",
|
|
||||||
"\n",
|
|
||||||
"These are already in your directory from your ONNX model download (from the model zoo).\n",
|
|
||||||
"\n",
|
|
||||||
"Notice that our Model Zoo files have a .pb extension. This is because they are [protobuf files (Protocol Buffers)](https://developers.google.com/protocol-buffers/docs/pythontutorial), so we need to read in our data through our ONNX TensorProto reader into a format we can work with, like numerical arrays."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# to manipulate our arrays\n",
|
|
||||||
"import numpy as np \n",
|
|
||||||
"\n",
|
|
||||||
"# read in test data protobuf files included with the model\n",
|
|
||||||
"import onnx\n",
|
|
||||||
"from onnx import numpy_helper\n",
|
|
||||||
"\n",
|
|
||||||
"# to use parsers to read in our model/data\n",
|
|
||||||
"import json\n",
|
|
||||||
"import os\n",
|
|
||||||
"\n",
|
|
||||||
"test_inputs = []\n",
|
|
||||||
"test_outputs = []\n",
|
|
||||||
"\n",
|
|
||||||
"# read in 3 testing images from .pb files\n",
|
|
||||||
"test_data_size = 3\n",
|
|
||||||
"\n",
|
|
||||||
"for i in np.arange(test_data_size):\n",
|
|
||||||
" input_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'input_0.pb')\n",
|
|
||||||
" output_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'output_0.pb')\n",
|
|
||||||
" \n",
|
|
||||||
" # convert protobuf tensors to np arrays using the TensorProto reader from ONNX\n",
|
|
||||||
" tensor = onnx.TensorProto()\n",
|
|
||||||
" with open(input_test_data, 'rb') as f:\n",
|
|
||||||
" tensor.ParseFromString(f.read())\n",
|
|
||||||
" \n",
|
|
||||||
" input_data = numpy_helper.to_array(tensor)\n",
|
|
||||||
" test_inputs.append(input_data)\n",
|
|
||||||
" \n",
|
|
||||||
" with open(output_test_data, 'rb') as f:\n",
|
|
||||||
" tensor.ParseFromString(f.read())\n",
|
|
||||||
" \n",
|
|
||||||
" output_data = numpy_helper.to_array(tensor)\n",
|
|
||||||
" output_processed = emotion_map(postprocess(output_data[0]))[0]\n",
|
|
||||||
" test_outputs.append(output_processed)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {
|
|
||||||
"nbpresent": {
|
|
||||||
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"source": [
|
|
||||||
"### Show some sample images\n",
|
|
||||||
"We use `matplotlib` to plot 3 test images from the dataset."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {
|
|
||||||
"nbpresent": {
|
|
||||||
"id": "396d478b-34aa-4afa-9898-cdce8222a516"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"plt.figure(figsize = (20, 20))\n",
|
|
||||||
"for test_image in np.arange(3):\n",
|
|
||||||
" test_inputs[test_image].reshape(1, 64, 64)\n",
|
|
||||||
" plt.subplot(1, 8, test_image+1)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
" plt.text(x = 10, y = -10, s = test_outputs[test_image], fontsize = 18)\n",
|
|
||||||
" plt.imshow(test_inputs[test_image].reshape(64, 64), cmap = plt.cm.gray)\n",
|
|
||||||
"plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Run evaluation / prediction"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"plt.figure(figsize = (16, 6), frameon=False)\n",
|
|
||||||
"plt.subplot(1, 8, 1)\n",
|
|
||||||
"\n",
|
|
||||||
"plt.text(x = 0, y = -30, s = \"True Label: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 0, y = -20, s = \"Result: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 0, y = -10, s = \"Inference Time: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 3, y = 14, s = \"Model Input\", fontsize = 12, color = 'black')\n",
|
|
||||||
"plt.text(x = 6, y = 18, s = \"(64 x 64)\", fontsize = 12, color = 'black')\n",
|
|
||||||
"plt.imshow(np.ones((28,28)), cmap=plt.cm.Greys) \n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"for i in np.arange(test_data_size):\n",
|
|
||||||
" \n",
|
|
||||||
" input_data = json.dumps({'data': test_inputs[i].tolist()})\n",
|
|
||||||
"\n",
|
|
||||||
" # predict using the deployed model\n",
|
|
||||||
" r = json.loads(aci_service.run(input_data))\n",
|
|
||||||
" \n",
|
|
||||||
" if \"error\" in r:\n",
|
|
||||||
" print(r['error'])\n",
|
|
||||||
" break\n",
|
|
||||||
" \n",
|
|
||||||
" result = r['result'][0]\n",
|
|
||||||
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
|
||||||
" \n",
|
|
||||||
" ground_truth = test_outputs[i]\n",
|
|
||||||
" \n",
|
|
||||||
" # compare actual value vs. the predicted values:\n",
|
|
||||||
" plt.subplot(1, 8, i+2)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
"\n",
|
|
||||||
" # use different color for misclassified sample\n",
|
|
||||||
" font_color = 'red' if ground_truth != result else 'black'\n",
|
|
||||||
" clr_map = plt.cm.Greys if ground_truth != result else plt.cm.gray\n",
|
|
||||||
"\n",
|
|
||||||
" # ground truth labels are in blue\n",
|
|
||||||
" plt.text(x = 10, y = -70, s = ground_truth, fontsize = 18, color = 'blue')\n",
|
|
||||||
" \n",
|
|
||||||
" # predictions are in black if correct, red if incorrect\n",
|
|
||||||
" plt.text(x = 10, y = -45, s = result, fontsize = 18, color = font_color)\n",
|
|
||||||
" plt.text(x = 5, y = -22, s = str(time_ms) + ' ms', fontsize = 14, color = font_color)\n",
|
|
||||||
"\n",
|
|
||||||
" \n",
|
|
||||||
" plt.imshow(test_inputs[i].reshape(64, 64), cmap = clr_map)\n",
|
|
||||||
"\n",
|
|
||||||
"plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Try classifying your own images!"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Preprocessing functions take your image and format it so it can be passed\n",
|
|
||||||
"# as input into our ONNX model\n",
|
|
||||||
"\n",
|
|
||||||
"import cv2\n",
|
|
||||||
"\n",
|
|
||||||
"def rgb2gray(rgb):\n",
|
|
||||||
" \"\"\"Convert the input image into grayscale\"\"\"\n",
|
|
||||||
" return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])\n",
|
|
||||||
"\n",
|
|
||||||
"def resize_img(img):\n",
|
|
||||||
" \"\"\"Resize image to MNIST model input dimensions\"\"\"\n",
|
|
||||||
" img = cv2.resize(img, dsize=(64, 64), interpolation=cv2.INTER_AREA)\n",
|
|
||||||
" img.resize((1, 1, 64, 64))\n",
|
|
||||||
" return img\n",
|
|
||||||
"\n",
|
|
||||||
"def preprocess(img):\n",
|
|
||||||
" \"\"\"Resize input images and convert them to grayscale.\"\"\"\n",
|
|
||||||
" if img.shape == (64, 64):\n",
|
|
||||||
" img.resize((1, 1, 64, 64))\n",
|
|
||||||
" return img\n",
|
|
||||||
" \n",
|
|
||||||
" grayscale = rgb2gray(img)\n",
|
|
||||||
" processed_img = resize_img(grayscale)\n",
|
|
||||||
" return processed_img"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Replace the following string with your own path/test image\n",
|
|
||||||
"# Make sure your image is square and the dimensions are equal (i.e. 100 * 100 pixels or 28 * 28 pixels)\n",
|
|
||||||
"\n",
|
|
||||||
"# Any PNG or JPG image file should work\n",
|
|
||||||
"# Make sure to include the entire path with // instead of /\n",
|
|
||||||
"\n",
|
|
||||||
"# e.g. your_test_image = \"C:/Users/vinitra.swamy/Pictures/face.png\"\n",
|
|
||||||
"\n",
|
|
||||||
"your_test_image = \"<path to file>\"\n",
|
|
||||||
"\n",
|
|
||||||
"import matplotlib.image as mpimg\n",
|
|
||||||
"\n",
|
|
||||||
"if your_test_image != \"<path to file>\":\n",
|
|
||||||
" img = mpimg.imread(your_test_image)\n",
|
|
||||||
" plt.subplot(1,3,1)\n",
|
|
||||||
" plt.imshow(img, cmap = plt.cm.Greys)\n",
|
|
||||||
" print(\"Old Dimensions: \", img.shape)\n",
|
|
||||||
" img = preprocess(img)\n",
|
|
||||||
" print(\"New Dimensions: \", img.shape)\n",
|
|
||||||
"else:\n",
|
|
||||||
" img = None"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if img is None:\n",
|
|
||||||
" print(\"Add the path for your image data.\")\n",
|
|
||||||
"else:\n",
|
|
||||||
" input_data = json.dumps({'data': img.tolist()})\n",
|
|
||||||
"\n",
|
|
||||||
" try:\n",
|
|
||||||
" r = json.loads(aci_service.run(input_data))\n",
|
|
||||||
" result = r['result'][0]\n",
|
|
||||||
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
|
||||||
" except Exception as e:\n",
|
|
||||||
" print(str(e))\n",
|
|
||||||
"\n",
|
|
||||||
" plt.figure(figsize = (16, 6))\n",
|
|
||||||
" plt.subplot(1,8,1)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
" plt.text(x = -10, y = -40, s = \"Model prediction: \", fontsize = 14)\n",
|
|
||||||
" plt.text(x = -10, y = -25, s = \"Inference time: \", fontsize = 14)\n",
|
|
||||||
" plt.text(x = 100, y = -40, s = str(result), fontsize = 14)\n",
|
|
||||||
" plt.text(x = 100, y = -25, s = str(time_ms) + \" ms\", fontsize = 14)\n",
|
|
||||||
" plt.text(x = -10, y = -10, s = \"Model Input image: \", fontsize = 14)\n",
|
|
||||||
" plt.imshow(img.reshape((64, 64)), cmap = plt.cm.gray) \n",
|
|
||||||
" "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# remember to delete your service after you are done using it!\n",
|
|
||||||
"\n",
|
|
||||||
"# aci_service.delete()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Conclusion\n",
|
|
||||||
"\n",
|
|
||||||
"Congratulations!\n",
|
|
||||||
"\n",
|
|
||||||
"In this tutorial, you have:\n",
|
|
||||||
"- familiarized yourself with ONNX Runtime inference and the pretrained models in the ONNX model zoo\n",
|
|
||||||
"- understood a state-of-the-art convolutional neural net image classification model (FER+ in ONNX) and deployed it in the Azure ML cloud\n",
|
|
||||||
"- ensured that your deep learning model is working perfectly (in the cloud) on test data, and checked it against some of your own!\n",
|
|
||||||
"\n",
|
|
||||||
"Next steps:\n",
|
|
||||||
"- If you have not already, check out another interesting ONNX/AML application that lets you set up a state-of-the-art [handwritten image classification model (MNIST)](https://github.com/Azure/MachineLearningNotebooks/tree/master/onnx/onnx-inference-mnist.ipynb) in the cloud! This tutorial deploys a pre-trained ONNX Computer Vision model for handwritten digit classification in an Azure ML virtual machine.\n",
|
|
||||||
"- Keep an eye out for an updated version of this tutorial that uses ONNX Runtime GPU.\n",
|
|
||||||
"- Contribute to our [open source ONNX repository on github](http://github.com/onnx/onnx) and/or add to our [ONNX model zoo](http://github.com/onnx/models)"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "viswamy"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
},
|
|
||||||
"msauthor": "vinitra.swamy"
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
@@ -1,792 +0,0 @@
|
|||||||
{
|
|
||||||
"cells": [
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Copyright (c) Microsoft Corporation. All rights reserved. \n",
|
|
||||||
"Licensed under the MIT License."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"# Handwritten Digit Classification (MNIST) using ONNX Runtime on Azure ML\n",
|
|
||||||
"\n",
|
|
||||||
"This example shows how to deploy an image classification neural network using the Modified National Institute of Standards and Technology ([MNIST](http://yann.lecun.com/exdb/mnist/)) dataset and Open Neural Network eXchange format ([ONNX](http://aka.ms/onnxdocarticle)) on the Azure Machine Learning platform. MNIST is a popular dataset consisting of 70,000 grayscale images. Each image is a handwritten digit of 28x28 pixels, representing number from 0 to 9. This tutorial will show you how to deploy a MNIST model from the [ONNX model zoo](https://github.com/onnx/models), use it to make predictions using ONNX Runtime Inference, and deploy it as a web service in Azure.\n",
|
|
||||||
"\n",
|
|
||||||
"Throughout this tutorial, we will be referring to ONNX, a neural network exchange format used to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools (CNTK, PyTorch, Caffe, MXNet, TensorFlow) and choose the combination that is best for them. ONNX is developed and supported by a community of partners including Microsoft AI, Facebook, and Amazon. For more information, explore the [ONNX website](http://onnx.ai) and [open source files](https://github.com/onnx).\n",
|
|
||||||
"\n",
|
|
||||||
"[ONNX Runtime](https://aka.ms/onnxruntime-python) is the runtime engine that enables evaluation of trained machine learning (Traditional ML and Deep Learning) models with high performance and low resource utilization.\n",
|
|
||||||
"\n",
|
|
||||||
"#### Tutorial Objectives:\n",
|
|
||||||
"\n",
|
|
||||||
"- Describe the MNIST dataset and pretrained Convolutional Neural Net ONNX model, stored in the ONNX model zoo.\n",
|
|
||||||
"- Deploy and run the pretrained MNIST ONNX model on an Azure Machine Learning instance\n",
|
|
||||||
"- Predict labels for test set data points in the cloud using ONNX Runtime and Azure ML"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Prerequisites\n",
|
|
||||||
"\n",
|
|
||||||
"### 1. Install Azure ML SDK and create a new workspace\n",
|
|
||||||
"Please follow [Azure ML configuration notebook](https://github.com/Azure/MachineLearningNotebooks/blob/master/00.configuration.ipynb) to set up your environment.\n",
|
|
||||||
"\n",
|
|
||||||
"### 2. Install additional packages needed for this tutorial notebook\n",
|
|
||||||
"You need to install the popular plotting library `matplotlib`, the image manipulation library `opencv`, and the `onnx` library in the conda environment where Azure Maching Learning SDK is installed. \n",
|
|
||||||
"\n",
|
|
||||||
"```sh\n",
|
|
||||||
"(myenv) $ pip install matplotlib onnx opencv-python\n",
|
|
||||||
"```\n",
|
|
||||||
"\n",
|
|
||||||
"**Debugging tip**: Make sure that you run the \"jupyter notebook\" command to launch this notebook after activating your virtual environment. Choose the respective Python kernel for your new virtual environment using the `Kernel > Change Kernel` menu above. If you have completed the steps correctly, the upper right corner of your screen should state `Python [conda env:myenv]` instead of `Python [default]`.\n",
|
|
||||||
"\n",
|
|
||||||
"### 3. Download sample data and pre-trained ONNX model from ONNX Model Zoo.\n",
|
|
||||||
"\n",
|
|
||||||
"In the following lines of code, we download [the trained ONNX MNIST model and corresponding test data](https://github.com/onnx/models/tree/master/mnist) and place them in the same folder as this tutorial notebook. For more information about the MNIST dataset, please visit [Yan LeCun's website](http://yann.lecun.com/exdb/mnist/)."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# urllib is a built-in Python library to download files from URLs\n",
|
|
||||||
"\n",
|
|
||||||
"# Objective: retrieve the latest version of the ONNX MNIST model files from the\n",
|
|
||||||
"# ONNX Model Zoo and save it in the same folder as this tutorial\n",
|
|
||||||
"\n",
|
|
||||||
"import urllib.request\n",
|
|
||||||
"\n",
|
|
||||||
"onnx_model_url = \"https://www.cntk.ai/OnnxModels/mnist/opset_7/mnist.tar.gz\"\n",
|
|
||||||
"\n",
|
|
||||||
"urllib.request.urlretrieve(onnx_model_url, filename=\"mnist.tar.gz\")"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# the ! magic command tells our jupyter notebook kernel to run the following line of \n",
|
|
||||||
"# code from the command line instead of the notebook kernel\n",
|
|
||||||
"\n",
|
|
||||||
"# We use tar and xvcf to unzip the files we just retrieved from the ONNX model zoo\n",
|
|
||||||
"\n",
|
|
||||||
"!tar xvzf mnist.tar.gz"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Deploy a VM with your ONNX model in the Cloud\n",
|
|
||||||
"\n",
|
|
||||||
"### Load Azure ML workspace\n",
|
|
||||||
"\n",
|
|
||||||
"We begin by instantiating a workspace object from the existing workspace created earlier in the configuration notebook."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Check core SDK version number\n",
|
|
||||||
"import azureml.core\n",
|
|
||||||
"\n",
|
|
||||||
"print(\"SDK version:\", azureml.core.VERSION)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core import Workspace\n",
|
|
||||||
"\n",
|
|
||||||
"ws = Workspace.from_config()\n",
|
|
||||||
"print(ws.name, ws.resource_group, ws.location, sep = '\\n')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Registering your model with Azure ML"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"model_dir = \"mnist\" # replace this with the location of your model files\n",
|
|
||||||
"\n",
|
|
||||||
"# leave as is if it's in the same folder as this notebook"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.model import Model\n",
|
|
||||||
"\n",
|
|
||||||
"model = Model.register(workspace = ws,\n",
|
|
||||||
" model_path = model_dir + \"/\" + \"model.onnx\",\n",
|
|
||||||
" model_name = \"mnist_1\",\n",
|
|
||||||
" tags = {\"onnx\": \"demo\"},\n",
|
|
||||||
" description = \"MNIST image classification CNN from ONNX Model Zoo\",)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Optional: Displaying your registered models\n",
|
|
||||||
"\n",
|
|
||||||
"This step is not required, so feel free to skip it."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"models = ws.models\n",
|
|
||||||
"for name, m in models.items():\n",
|
|
||||||
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {
|
|
||||||
"nbpresent": {
|
|
||||||
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"source": [
|
|
||||||
"### ONNX MNIST Model Methodology\n",
|
|
||||||
"\n",
|
|
||||||
"The image classification model we are using is pre-trained using Microsoft's deep learning cognitive toolkit, [CNTK](https://github.com/Microsoft/CNTK), from the [ONNX model zoo](http://github.com/onnx/models). The model zoo has many other models that can be deployed on cloud providers like AzureML without any additional training. To ensure that our cloud deployed model works, we use testing data from the famous MNIST data set, provided as part of the [trained MNIST model](https://github.com/onnx/models/tree/master/mnist) in the ONNX model zoo.\n",
|
|
||||||
"\n",
|
|
||||||
"***Input: Handwritten Images from MNIST Dataset***\n",
|
|
||||||
"\n",
|
|
||||||
"***Task: Classify each MNIST image into an appropriate digit***\n",
|
|
||||||
"\n",
|
|
||||||
"***Output: Digit prediction for input image***\n",
|
|
||||||
"\n",
|
|
||||||
"Run the cell below to look at some of the sample images from the MNIST dataset that we used to train this ONNX model. Remember, once the application is deployed in Azure ML, you can use your own images as input for the model to classify!"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# for images and plots in this notebook\n",
|
|
||||||
"import matplotlib.pyplot as plt \n",
|
|
||||||
"from IPython.display import Image\n",
|
|
||||||
"\n",
|
|
||||||
"# display images inline\n",
|
|
||||||
"%matplotlib inline"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"Image(url=\"http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png\", width=200, height=200)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Specify our Score and Environment Files"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"We are now going to deploy our ONNX Model on AML with inference in ONNX Runtime. We begin by writing a score.py file, which will help us run the model in our Azure ML virtual machine (VM), and then specify our environment by writing a yml file. You will also notice that we import the onnxruntime library to do runtime inference on our ONNX models (passing in input and evaluating out model's predicted output). More information on the API and commands can be found in the [ONNX Runtime documentation](https://aka.ms/onnxruntime).\n",
|
|
||||||
"\n",
|
|
||||||
"### Write Score File\n",
|
|
||||||
"\n",
|
|
||||||
"A score file is what tells our Azure cloud service what to do. After initializing our model using azureml.core.model, we start an ONNX Runtime inference session to evaluate the data passed in on our function calls."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"%%writefile score.py\n",
|
|
||||||
"import json\n",
|
|
||||||
"import numpy as np\n",
|
|
||||||
"import onnxruntime\n",
|
|
||||||
"import sys\n",
|
|
||||||
"import os\n",
|
|
||||||
"from azureml.core.model import Model\n",
|
|
||||||
"import time\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"def init():\n",
|
|
||||||
" global session, input_name, output_name\n",
|
|
||||||
" model = Model.get_model_path(model_name = 'mnist_1')\n",
|
|
||||||
" session = onnxruntime.InferenceSession(model, None)\n",
|
|
||||||
" input_name = session.get_inputs()[0].name\n",
|
|
||||||
" output_name = session.get_outputs()[0].name \n",
|
|
||||||
" \n",
|
|
||||||
"def run(input_data):\n",
|
|
||||||
" '''Purpose: evaluate test input in Azure Cloud using onnxruntime.\n",
|
|
||||||
" We will call the run function later from our Jupyter Notebook \n",
|
|
||||||
" so our azure service can evaluate our model input in the cloud. '''\n",
|
|
||||||
"\n",
|
|
||||||
" try:\n",
|
|
||||||
" # load in our data, convert to readable format\n",
|
|
||||||
" data = np.array(json.loads(input_data)['data']).astype('float32')\n",
|
|
||||||
"\n",
|
|
||||||
" start = time.time()\n",
|
|
||||||
" r = session.run([output_name], {input_name: data})[0]\n",
|
|
||||||
" end = time.time()\n",
|
|
||||||
" result = choose_class(r[0])\n",
|
|
||||||
" result_dict = {\"result\": [result],\n",
|
|
||||||
" \"time_in_sec\": [end - start]}\n",
|
|
||||||
" except Exception as e:\n",
|
|
||||||
" result_dict = {\"error\": str(e)}\n",
|
|
||||||
" \n",
|
|
||||||
" return json.dumps(result_dict)\n",
|
|
||||||
"\n",
|
|
||||||
"def choose_class(result_prob):\n",
|
|
||||||
" \"\"\"We use argmax to determine the right label to choose from our output\"\"\"\n",
|
|
||||||
" return int(np.argmax(result_prob, axis=0))"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Write Environment File\n",
|
|
||||||
"\n",
|
|
||||||
"This step creates a YAML environment file that specifies which dependencies we would like to see in our Linux Virtual Machine."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
|
||||||
"\n",
|
|
||||||
"myenv = CondaDependencies.create(pip_packages=[\"numpy\", \"onnxruntime\", \"azureml-core\"])\n",
|
|
||||||
"\n",
|
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
|
||||||
" f.write(myenv.serialize_to_string())"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Create the Container Image\n",
|
|
||||||
"This step will likely take a few minutes."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.image import ContainerImage\n",
|
|
||||||
"\n",
|
|
||||||
"image_config = ContainerImage.image_configuration(execution_script = \"score.py\",\n",
|
|
||||||
" runtime = \"python\",\n",
|
|
||||||
" conda_file = \"myenv.yml\",\n",
|
|
||||||
" description = \"MNIST ONNX Runtime container\",\n",
|
|
||||||
" tags = {\"demo\": \"onnx\"}) \n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"image = ContainerImage.create(name = \"onnximage\",\n",
|
|
||||||
" # this is the model object\n",
|
|
||||||
" models = [model],\n",
|
|
||||||
" image_config = image_config,\n",
|
|
||||||
" workspace = ws)\n",
|
|
||||||
"\n",
|
|
||||||
"image.wait_for_creation(show_output = True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"In case you need to debug your code, the next line of code accesses the log file."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"print(image.image_build_log_uri)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"We're all done specifying what we want our virtual machine to do. Let's configure and deploy our container image.\n",
|
|
||||||
"\n",
|
|
||||||
"### Deploy the container image"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.webservice import AciWebservice\n",
|
|
||||||
"\n",
|
|
||||||
"aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1, \n",
|
|
||||||
" memory_gb = 1, \n",
|
|
||||||
" tags = {'demo': 'onnx'}, \n",
|
|
||||||
" description = 'ONNX for mnist model')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"The following cell will likely take a few minutes to run as well."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"from azureml.core.webservice import Webservice\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service_name = 'onnx-demo-mnist'\n",
|
|
||||||
"print(\"Service\", aci_service_name)\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service = Webservice.deploy_from_image(deployment_config = aciconfig,\n",
|
|
||||||
" image = image,\n",
|
|
||||||
" name = aci_service_name,\n",
|
|
||||||
" workspace = ws)\n",
|
|
||||||
"\n",
|
|
||||||
"aci_service.wait_for_deployment(True)\n",
|
|
||||||
"print(aci_service.state)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if aci_service.state != 'Healthy':\n",
|
|
||||||
" # run this command for debugging.\n",
|
|
||||||
" print(aci_service.get_logs())\n",
|
|
||||||
"\n",
|
|
||||||
" # If your deployment fails, make sure to delete your aci_service or rename your service before trying again!\n",
|
|
||||||
" # aci_service.delete()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Success!\n",
|
|
||||||
"\n",
|
|
||||||
"If you've made it this far, you've deployed a working VM with a handwritten digit classifier running in the cloud using Azure ML. Congratulations!\n",
|
|
||||||
"\n",
|
|
||||||
"Let's see how well our model deals with our test images."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Testing and Evaluation\n",
|
|
||||||
"\n",
|
|
||||||
"### Load Test Data\n",
|
|
||||||
"\n",
|
|
||||||
"These are already in your directory from your ONNX model download (from the model zoo).\n",
|
|
||||||
"\n",
|
|
||||||
"Notice that our Model Zoo files have a .pb extension. This is because they are [protobuf files (Protocol Buffers)](https://developers.google.com/protocol-buffers/docs/pythontutorial), so we need to read in our data through our ONNX TensorProto reader into a format we can work with, like numerical arrays."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# to manipulate our arrays\n",
|
|
||||||
"import numpy as np \n",
|
|
||||||
"\n",
|
|
||||||
"# read in test data protobuf files included with the model\n",
|
|
||||||
"import onnx\n",
|
|
||||||
"from onnx import numpy_helper\n",
|
|
||||||
"\n",
|
|
||||||
"# to use parsers to read in our model/data\n",
|
|
||||||
"import json\n",
|
|
||||||
"import os\n",
|
|
||||||
"\n",
|
|
||||||
"test_inputs = []\n",
|
|
||||||
"test_outputs = []\n",
|
|
||||||
"\n",
|
|
||||||
"# read in 3 testing images from .pb files\n",
|
|
||||||
"test_data_size = 3\n",
|
|
||||||
"\n",
|
|
||||||
"for i in np.arange(test_data_size):\n",
|
|
||||||
" input_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'input_0.pb')\n",
|
|
||||||
" output_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'output_0.pb')\n",
|
|
||||||
" \n",
|
|
||||||
" # convert protobuf tensors to np arrays using the TensorProto reader from ONNX\n",
|
|
||||||
" tensor = onnx.TensorProto()\n",
|
|
||||||
" with open(input_test_data, 'rb') as f:\n",
|
|
||||||
" tensor.ParseFromString(f.read())\n",
|
|
||||||
" \n",
|
|
||||||
" input_data = numpy_helper.to_array(tensor)\n",
|
|
||||||
" test_inputs.append(input_data)\n",
|
|
||||||
" \n",
|
|
||||||
" with open(output_test_data, 'rb') as f:\n",
|
|
||||||
" tensor.ParseFromString(f.read())\n",
|
|
||||||
" \n",
|
|
||||||
" output_data = numpy_helper.to_array(tensor)\n",
|
|
||||||
" test_outputs.append(output_data)\n",
|
|
||||||
" \n",
|
|
||||||
"if len(test_inputs) == test_data_size:\n",
|
|
||||||
" print('Test data loaded successfully.')"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {
|
|
||||||
"nbpresent": {
|
|
||||||
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"source": [
|
|
||||||
"### Show some sample images\n",
|
|
||||||
"We use `matplotlib` to plot 3 test images from the dataset."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {
|
|
||||||
"nbpresent": {
|
|
||||||
"id": "396d478b-34aa-4afa-9898-cdce8222a516"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"plt.figure(figsize = (16, 6))\n",
|
|
||||||
"for test_image in np.arange(3):\n",
|
|
||||||
" plt.subplot(1, 15, test_image+1)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
" plt.imshow(test_inputs[test_image].reshape(28, 28), cmap = plt.cm.Greys)\n",
|
|
||||||
"plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Run evaluation / prediction"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"plt.figure(figsize = (16, 6), frameon=False)\n",
|
|
||||||
"plt.subplot(1, 8, 1)\n",
|
|
||||||
"\n",
|
|
||||||
"plt.text(x = 0, y = -30, s = \"True Label: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 0, y = -20, s = \"Result: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 0, y = -10, s = \"Inference Time: \", fontsize = 13, color = 'black')\n",
|
|
||||||
"plt.text(x = 3, y = 14, s = \"Model Input\", fontsize = 12, color = 'black')\n",
|
|
||||||
"plt.text(x = 6, y = 18, s = \"(28 x 28)\", fontsize = 12, color = 'black')\n",
|
|
||||||
"plt.imshow(np.ones((28,28)), cmap=plt.cm.Greys) \n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"for i in np.arange(test_data_size):\n",
|
|
||||||
" \n",
|
|
||||||
" input_data = json.dumps({'data': test_inputs[i].tolist()})\n",
|
|
||||||
" \n",
|
|
||||||
" # predict using the deployed model\n",
|
|
||||||
" r = json.loads(aci_service.run(input_data))\n",
|
|
||||||
" \n",
|
|
||||||
" if \"error\" in r:\n",
|
|
||||||
" print(r['error'])\n",
|
|
||||||
" break\n",
|
|
||||||
" \n",
|
|
||||||
" result = r['result'][0]\n",
|
|
||||||
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
|
||||||
" \n",
|
|
||||||
" ground_truth = int(np.argmax(test_outputs[i]))\n",
|
|
||||||
" \n",
|
|
||||||
" # compare actual value vs. the predicted values:\n",
|
|
||||||
" plt.subplot(1, 8, i+2)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
"\n",
|
|
||||||
" # use different color for misclassified sample\n",
|
|
||||||
" font_color = 'red' if ground_truth != result else 'black'\n",
|
|
||||||
" clr_map = plt.cm.gray if ground_truth != result else plt.cm.Greys\n",
|
|
||||||
"\n",
|
|
||||||
" # ground truth labels are in blue\n",
|
|
||||||
" plt.text(x = 10, y = -30, s = ground_truth, fontsize = 18, color = 'blue')\n",
|
|
||||||
" \n",
|
|
||||||
" # predictions are in black if correct, red if incorrect\n",
|
|
||||||
" plt.text(x = 10, y = -20, s = result, fontsize = 18, color = font_color)\n",
|
|
||||||
" plt.text(x = 5, y = -10, s = str(time_ms) + ' ms', fontsize = 14, color = font_color)\n",
|
|
||||||
"\n",
|
|
||||||
" \n",
|
|
||||||
" plt.imshow(test_inputs[i].reshape(28, 28), cmap = clr_map)\n",
|
|
||||||
"\n",
|
|
||||||
"plt.show()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Try classifying your own images!\n",
|
|
||||||
"\n",
|
|
||||||
"Create your own handwritten image and pass it into the model."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Preprocessing functions take your image and format it so it can be passed\n",
|
|
||||||
"# as input into our ONNX model\n",
|
|
||||||
"\n",
|
|
||||||
"import cv2\n",
|
|
||||||
"\n",
|
|
||||||
"def rgb2gray(rgb):\n",
|
|
||||||
" \"\"\"Convert the input image into grayscale\"\"\"\n",
|
|
||||||
" return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])\n",
|
|
||||||
"\n",
|
|
||||||
"def resize_img(img):\n",
|
|
||||||
" \"\"\"Resize image to MNIST model input dimensions\"\"\"\n",
|
|
||||||
" img = cv2.resize(img, dsize=(28, 28), interpolation=cv2.INTER_AREA)\n",
|
|
||||||
" img.resize((1, 1, 28, 28))\n",
|
|
||||||
" return img\n",
|
|
||||||
"\n",
|
|
||||||
"def preprocess(img):\n",
|
|
||||||
" \"\"\"Resize input images and convert them to grayscale.\"\"\"\n",
|
|
||||||
" if img.shape == (28, 28):\n",
|
|
||||||
" img.resize((1, 1, 28, 28))\n",
|
|
||||||
" return img\n",
|
|
||||||
" \n",
|
|
||||||
" grayscale = rgb2gray(img)\n",
|
|
||||||
" processed_img = resize_img(grayscale)\n",
|
|
||||||
" return processed_img"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# Replace this string with your own path/test image\n",
|
|
||||||
"# Make sure your image is square and the dimensions are equal (i.e. 100 * 100 pixels or 28 * 28 pixels)\n",
|
|
||||||
"\n",
|
|
||||||
"# Any PNG or JPG image file should work\n",
|
|
||||||
"\n",
|
|
||||||
"your_test_image = \"<path to file>\"\n",
|
|
||||||
"\n",
|
|
||||||
"# e.g. your_test_image = \"C:/Users/vinitra.swamy/Pictures/handwritten_digit.png\"\n",
|
|
||||||
"\n",
|
|
||||||
"import matplotlib.image as mpimg\n",
|
|
||||||
"\n",
|
|
||||||
"if your_test_image != \"<path to file>\":\n",
|
|
||||||
" img = mpimg.imread(your_test_image)\n",
|
|
||||||
" plt.subplot(1,3,1)\n",
|
|
||||||
" plt.imshow(img, cmap = plt.cm.Greys)\n",
|
|
||||||
" print(\"Old Dimensions: \", img.shape)\n",
|
|
||||||
" img = preprocess(img)\n",
|
|
||||||
" print(\"New Dimensions: \", img.shape)\n",
|
|
||||||
"else:\n",
|
|
||||||
" img = None"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"if img is None:\n",
|
|
||||||
" print(\"Add the path for your image data.\")\n",
|
|
||||||
"else:\n",
|
|
||||||
" input_data = json.dumps({'data': img.tolist()})\n",
|
|
||||||
"\n",
|
|
||||||
" try:\n",
|
|
||||||
" r = json.loads(aci_service.run(input_data))\n",
|
|
||||||
" result = r['result'][0]\n",
|
|
||||||
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
|
||||||
" except Exception as e:\n",
|
|
||||||
" print(str(e))\n",
|
|
||||||
"\n",
|
|
||||||
" plt.figure(figsize = (16, 6))\n",
|
|
||||||
" plt.subplot(1, 15,1)\n",
|
|
||||||
" plt.axhline('')\n",
|
|
||||||
" plt.axvline('')\n",
|
|
||||||
" plt.text(x = -100, y = -20, s = \"Model prediction: \", fontsize = 14)\n",
|
|
||||||
" plt.text(x = -100, y = -10, s = \"Inference time: \", fontsize = 14)\n",
|
|
||||||
" plt.text(x = 0, y = -20, s = str(result), fontsize = 14)\n",
|
|
||||||
" plt.text(x = 0, y = -10, s = str(time_ms) + \" ms\", fontsize = 14)\n",
|
|
||||||
" plt.text(x = -100, y = 14, s = \"Input image: \", fontsize = 14)\n",
|
|
||||||
" plt.imshow(img.reshape(28, 28), cmap = plt.cm.gray) "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Optional: How does our ONNX MNIST model work? \n",
|
|
||||||
"#### A brief explanation of Convolutional Neural Networks\n",
|
|
||||||
"\n",
|
|
||||||
"A [convolutional neural network](https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN, or ConvNet) is a type of [feed-forward](https://en.wikipedia.org/wiki/Feedforward_neural_network) artificial neural network made up of neurons that have learnable weights and biases. The CNNs take advantage of the spatial nature of the data. In nature, we perceive different objects by their shapes, size and colors. For example, objects in a natural scene are typically edges, corners/vertices (defined by two of more edges), color patches etc. These primitives are often identified using different detectors (e.g., edge detection, color detector) or combination of detectors interacting to facilitate image interpretation (object classification, region of interest detection, scene description etc.) in real world vision related tasks. These detectors are also known as filters. Convolution is a mathematical operator that takes an image and a filter as input and produces a filtered output (representing say edges, corners, or colors in the input image). \n",
|
|
||||||
"\n",
|
|
||||||
"Historically, these filters are a set of weights that were often hand crafted or modeled with mathematical functions (e.g., [Gaussian](https://en.wikipedia.org/wiki/Gaussian_filter) / [Laplacian](http://homepages.inf.ed.ac.uk/rbf/HIPR2/log.htm) / [Canny](https://en.wikipedia.org/wiki/Canny_edge_detector) filter). The filter outputs are mapped through non-linear activation functions mimicking human brain cells called [neurons](https://en.wikipedia.org/wiki/Neuron). Popular deep CNNs or ConvNets (such as [AlexNet](https://en.wikipedia.org/wiki/AlexNet), [VGG](https://arxiv.org/abs/1409.1556), [Inception](http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf), [ResNet](https://arxiv.org/pdf/1512.03385v1.pdf)) that are used for various [computer vision](https://en.wikipedia.org/wiki/Computer_vision) tasks have many of these architectural primitives (inspired from biology). \n",
|
|
||||||
"\n",
|
|
||||||
"### Convolution Layer\n",
|
|
||||||
"\n",
|
|
||||||
"A convolution layer is a set of filters. Each filter is defined by a weight (**W**) matrix, and bias ($b$).\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"\n",
|
|
||||||
"These filters are scanned across the image performing the dot product between the weights and corresponding input value ($x$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"Image(url=\"https://www.cntk.ai/jup/cntk103d_conv2d_final.gif\", width= 200)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"### Model Description\n",
|
|
||||||
"\n",
|
|
||||||
"The MNIST model from the ONNX Model Zoo uses maxpooling to update the weights in its convolutions, summarized by the graphic below. You can see the entire workflow of our pre-trained model in the following image, with our input images and our output probabilities of each of our 10 labels. If you're interested in exploring the logic behind creating a Deep Learning model further, please look at the [training tutorial for our ONNX MNIST Convolutional Neural Network](https://github.com/Microsoft/CNTK/blob/master/Tutorials/CNTK_103D_MNIST_ConvolutionalNeuralNetwork.ipynb). "
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Max-Pooling for Convolutional Neural Nets\n",
|
|
||||||
"\n",
|
|
||||||
""
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"#### Pre-Trained Model Architecture\n",
|
|
||||||
"\n",
|
|
||||||
""
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# remember to delete your service after you are done using it!\n",
|
|
||||||
"\n",
|
|
||||||
"# aci_service.delete()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"## Conclusion\n",
|
|
||||||
"\n",
|
|
||||||
"Congratulations!\n",
|
|
||||||
"\n",
|
|
||||||
"In this tutorial, you have:\n",
|
|
||||||
"- familiarized yourself with ONNX Runtime inference and the pretrained models in the ONNX model zoo\n",
|
|
||||||
"- understood a state-of-the-art convolutional neural net image classification model (MNIST in ONNX) and deployed it in Azure ML cloud\n",
|
|
||||||
"- ensured that your deep learning model is working perfectly (in the cloud) on test data, and checked it against some of your own!\n",
|
|
||||||
"\n",
|
|
||||||
"Next steps:\n",
|
|
||||||
"- Check out another interesting application based on a Microsoft Research computer vision paper that lets you set up a [facial emotion recognition model](https://github.com/Azure/MachineLearningNotebooks/tree/master/onnx/onnx-inference-emotion-recognition.ipynb) in the cloud! This tutorial deploys a pre-trained ONNX Computer Vision model in an Azure ML virtual machine.\n",
|
|
||||||
"- Contribute to our [open source ONNX repository on github](http://github.com/onnx/onnx) and/or add to our [ONNX model zoo](http://github.com/onnx/models)"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"metadata": {
|
|
||||||
"authors": [
|
|
||||||
{
|
|
||||||
"name": "viswamy"
|
|
||||||
}
|
|
||||||
],
|
|
||||||
"kernelspec": {
|
|
||||||
"display_name": "Python 3.6",
|
|
||||||
"language": "python",
|
|
||||||
"name": "python36"
|
|
||||||
},
|
|
||||||
"language_info": {
|
|
||||||
"codemirror_mode": {
|
|
||||||
"name": "ipython",
|
|
||||||
"version": 3
|
|
||||||
},
|
|
||||||
"file_extension": ".py",
|
|
||||||
"mimetype": "text/x-python",
|
|
||||||
"name": "python",
|
|
||||||
"nbconvert_exporter": "python",
|
|
||||||
"pygments_lexer": "ipython3",
|
|
||||||
"version": "3.6.6"
|
|
||||||
},
|
|
||||||
"msauthor": "vinitra.swamy"
|
|
||||||
},
|
|
||||||
"nbformat": 4,
|
|
||||||
"nbformat_minor": 2
|
|
||||||
}
|
|
||||||
804
onnx/onnx-inference-mnist.ipynb
Normal file
804
onnx/onnx-inference-mnist.ipynb
Normal file
@@ -0,0 +1,804 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Copyright (c) Microsoft Corporation. All rights reserved. \n",
|
||||||
|
"Licensed under the MIT License."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"# Handwritten Digit Classification (MNIST) using ONNX Runtime on Azure ML\n",
|
||||||
|
"\n",
|
||||||
|
"This example shows how to deploy an image classification neural network using the Modified National Institute of Standards and Technology ([MNIST](http://yann.lecun.com/exdb/mnist/)) dataset and Open Neural Network eXchange format ([ONNX](http://aka.ms/onnxdocarticle)) on the Azure Machine Learning platform. MNIST is a popular dataset consisting of 70,000 grayscale images. Each image is a handwritten digit of 28x28 pixels, representing number from 0 to 9. This tutorial will show you how to deploy a MNIST model from the [ONNX model zoo](https://github.com/onnx/models), use it to make predictions using ONNX Runtime Inference, and deploy it as a web service in Azure.\n",
|
||||||
|
"\n",
|
||||||
|
"Throughout this tutorial, we will be referring to ONNX, a neural network exchange format used to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools (CNTK, PyTorch, Caffe, MXNet, TensorFlow) and choose the combination that is best for them. ONNX is developed and supported by a community of partners including Microsoft AI, Facebook, and Amazon. For more information, explore the [ONNX website](http://onnx.ai) and [open source files](https://github.com/onnx).\n",
|
||||||
|
"\n",
|
||||||
|
"[ONNX Runtime](https://aka.ms/onnxruntime-python) is the runtime engine that enables evaluation of trained machine learning (Traditional ML and Deep Learning) models with high performance and low resource utilization.\n",
|
||||||
|
"\n",
|
||||||
|
"#### Tutorial Objectives:\n",
|
||||||
|
"\n",
|
||||||
|
"- Describe the MNIST dataset and pretrained Convolutional Neural Net ONNX model, stored in the ONNX model zoo.\n",
|
||||||
|
"- Deploy and run the pretrained MNIST ONNX model on an Azure Machine Learning instance\n",
|
||||||
|
"- Predict labels for test set data points in the cloud using ONNX Runtime and Azure ML"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Prerequisites\n",
|
||||||
|
"\n",
|
||||||
|
"### 1. Install Azure ML SDK and create a new workspace\n",
|
||||||
|
"Please follow [Azure ML configuration notebook](https://github.com/Azure/MachineLearningNotebooks/blob/master/00.configuration.ipynb) to set up your environment.\n",
|
||||||
|
"\n",
|
||||||
|
"### 2. Install additional packages needed for this tutorial notebook\n",
|
||||||
|
"You need to install the popular plotting library `matplotlib`, the image manipulation library `opencv`, and the `onnx` library in the conda environment where Azure Maching Learning SDK is installed. \n",
|
||||||
|
"\n",
|
||||||
|
"```sh\n",
|
||||||
|
"(myenv) $ pip install matplotlib onnx opencv-python\n",
|
||||||
|
"```\n",
|
||||||
|
"\n",
|
||||||
|
"**Debugging tip**: Make sure that you run the \"jupyter notebook\" command to launch this notebook after activating your virtual environment. Choose the respective Python kernel for your new virtual environment using the `Kernel > Change Kernel` menu above. If you have completed the steps correctly, the upper right corner of your screen should state `Python [conda env:myenv]` instead of `Python [default]`.\n",
|
||||||
|
"\n",
|
||||||
|
"### 3. Download sample data and pre-trained ONNX model from ONNX Model Zoo.\n",
|
||||||
|
"\n",
|
||||||
|
"In the following lines of code, we download [the trained ONNX MNIST model and corresponding test data](https://github.com/onnx/models/tree/master/mnist) and place them in the same folder as this tutorial notebook. For more information about the MNIST dataset, please visit [Yan LeCun's website](http://yann.lecun.com/exdb/mnist/)."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# urllib is a built-in Python library to download files from URLs\n",
|
||||||
|
"\n",
|
||||||
|
"# Objective: retrieve the latest version of the ONNX MNIST model files from the\n",
|
||||||
|
"# ONNX Model Zoo and save it in the same folder as this tutorial\n",
|
||||||
|
"\n",
|
||||||
|
"import urllib.request\n",
|
||||||
|
"\n",
|
||||||
|
"onnx_model_url = \"https://www.cntk.ai/OnnxModels/mnist/opset_7/mnist.tar.gz\"\n",
|
||||||
|
"\n",
|
||||||
|
"urllib.request.urlretrieve(onnx_model_url, filename=\"mnist.tar.gz\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# the ! magic command tells our jupyter notebook kernel to run the following line of \n",
|
||||||
|
"# code from the command line instead of the notebook kernel\n",
|
||||||
|
"\n",
|
||||||
|
"# We use tar and xvcf to unzip the files we just retrieved from the ONNX model zoo\n",
|
||||||
|
"\n",
|
||||||
|
"!tar xvzf mnist.tar.gz"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Deploy a VM with your ONNX model in the Cloud\n",
|
||||||
|
"\n",
|
||||||
|
"### Load Azure ML workspace\n",
|
||||||
|
"\n",
|
||||||
|
"We begin by instantiating a workspace object from the existing workspace created earlier in the configuration notebook."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Check core SDK version number\n",
|
||||||
|
"import azureml.core\n",
|
||||||
|
"\n",
|
||||||
|
"print(\"SDK version:\", azureml.core.VERSION)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core import Workspace\n",
|
||||||
|
"\n",
|
||||||
|
"ws = Workspace.from_config()\n",
|
||||||
|
"print(ws.name, ws.resource_group, ws.location, sep = '\\n')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Registering your model with Azure ML"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"model_dir = \"mnist\" # replace this with the location of your model files\n",
|
||||||
|
"\n",
|
||||||
|
"# leave as is if it's in the same folder as this notebook"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.model import Model\n",
|
||||||
|
"\n",
|
||||||
|
"model = Model.register(workspace = ws,\n",
|
||||||
|
" model_path = model_dir + \"/\" + \"model.onnx\",\n",
|
||||||
|
" model_name = \"mnist_1\",\n",
|
||||||
|
" tags = {\"onnx\": \"demo\"},\n",
|
||||||
|
" description = \"MNIST image classification CNN from ONNX Model Zoo\",)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Optional: Displaying your registered models\n",
|
||||||
|
"\n",
|
||||||
|
"This step is not required, so feel free to skip it."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"models = ws.models()\n",
|
||||||
|
"for name, m in models.items():\n",
|
||||||
|
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {
|
||||||
|
"nbpresent": {
|
||||||
|
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"source": [
|
||||||
|
"### ONNX MNIST Model Methodology\n",
|
||||||
|
"\n",
|
||||||
|
"The image classification model we are using is pre-trained using Microsoft's deep learning cognitive toolkit, [CNTK](https://github.com/Microsoft/CNTK), from the [ONNX model zoo](http://github.com/onnx/models). The model zoo has many other models that can be deployed on cloud providers like AzureML without any additional training. To ensure that our cloud deployed model works, we use testing data from the famous MNIST data set, provided as part of the [trained MNIST model](https://github.com/onnx/models/tree/master/mnist) in the ONNX model zoo.\n",
|
||||||
|
"\n",
|
||||||
|
"***Input: Handwritten Images from MNIST Dataset***\n",
|
||||||
|
"\n",
|
||||||
|
"***Task: Classify each MNIST image into an appropriate digit***\n",
|
||||||
|
"\n",
|
||||||
|
"***Output: Digit prediction for input image***\n",
|
||||||
|
"\n",
|
||||||
|
"Run the cell below to look at some of the sample images from the MNIST dataset that we used to train this ONNX model. Remember, once the application is deployed in Azure ML, you can use your own images as input for the model to classify!"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# for images and plots in this notebook\n",
|
||||||
|
"import matplotlib.pyplot as plt \n",
|
||||||
|
"from IPython.display import Image\n",
|
||||||
|
"\n",
|
||||||
|
"# display images inline\n",
|
||||||
|
"%matplotlib inline"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"Image(url=\"http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png\", width=200, height=200)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Specify our Score and Environment Files"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"We are now going to deploy our ONNX Model on AML with inference in ONNX Runtime. We begin by writing a score.py file, which will help us run the model in our Azure ML virtual machine (VM), and then specify our environment by writing a yml file. You will also notice that we import the onnxruntime library to do runtime inference on our ONNX models (passing in input and evaluating out model's predicted output). More information on the API and commands can be found in the [ONNX Runtime documentation](https://aka.ms/onnxruntime).\n",
|
||||||
|
"\n",
|
||||||
|
"### Write Score File\n",
|
||||||
|
"\n",
|
||||||
|
"A score file is what tells our Azure cloud service what to do. After initializing our model using azureml.core.model, we start an ONNX Runtime inference session to evaluate the data passed in on our function calls."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"%%writefile score.py\n",
|
||||||
|
"import json\n",
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import onnxruntime\n",
|
||||||
|
"import sys\n",
|
||||||
|
"import os\n",
|
||||||
|
"from azureml.core.model import Model\n",
|
||||||
|
"import time\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"def init():\n",
|
||||||
|
" global session, input_name, output_name\n",
|
||||||
|
" model = Model.get_model_path(model_name = 'mnist_1')\n",
|
||||||
|
" session = onnxruntime.InferenceSession(model, None)\n",
|
||||||
|
" input_name = session.get_inputs()[0].name\n",
|
||||||
|
" output_name = session.get_outputs()[0].name \n",
|
||||||
|
" \n",
|
||||||
|
"def run(input_data):\n",
|
||||||
|
" '''Purpose: evaluate test input in Azure Cloud using onnxruntime.\n",
|
||||||
|
" We will call the run function later from our Jupyter Notebook \n",
|
||||||
|
" so our azure service can evaluate our model input in the cloud. '''\n",
|
||||||
|
"\n",
|
||||||
|
" try:\n",
|
||||||
|
" # load in our data, convert to readable format\n",
|
||||||
|
" data = np.array(json.loads(input_data)['data']).astype('float32')\n",
|
||||||
|
"\n",
|
||||||
|
" start = time.time()\n",
|
||||||
|
" r = session.run([output_name], {input_name: data})[0]\n",
|
||||||
|
" end = time.time()\n",
|
||||||
|
" result = choose_class(r[0])\n",
|
||||||
|
" result_dict = {\"result\": [result],\n",
|
||||||
|
" \"time_in_sec\": [end - start]}\n",
|
||||||
|
" except Exception as e:\n",
|
||||||
|
" result_dict = {\"error\": str(e)}\n",
|
||||||
|
" \n",
|
||||||
|
" return json.dumps(result_dict)\n",
|
||||||
|
"\n",
|
||||||
|
"def choose_class(result_prob):\n",
|
||||||
|
" \"\"\"We use argmax to determine the right label to choose from our output\"\"\"\n",
|
||||||
|
" return int(np.argmax(result_prob, axis=0))"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Write Environment File\n",
|
||||||
|
"\n",
|
||||||
|
"This step creates a YAML environment file that specifies which dependencies we would like to see in our Linux Virtual Machine."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
|
"\n",
|
||||||
|
"myenv = CondaDependencies()\n",
|
||||||
|
"myenv.add_pip_package(\"numpy\")\n",
|
||||||
|
"myenv.add_pip_package(\"azureml-core\")\n",
|
||||||
|
"myenv.add_pip_package(\"onnxruntime\")\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
|
" f.write(myenv.serialize_to_string())"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Create the Container Image\n",
|
||||||
|
"This step will likely take a few minutes."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.image import ContainerImage\n",
|
||||||
|
"help(ContainerImage.image_configuration)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.image import ContainerImage\n",
|
||||||
|
"\n",
|
||||||
|
"image_config = ContainerImage.image_configuration(execution_script = \"score.py\",\n",
|
||||||
|
" runtime = \"python\",\n",
|
||||||
|
" conda_file = \"myenv.yml\",\n",
|
||||||
|
" description = \"MNIST ONNX Runtime container\",\n",
|
||||||
|
" tags = {\"demo\": \"onnx\"}) \n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"image = ContainerImage.create(name = \"onnxtest\",\n",
|
||||||
|
" # this is the model object\n",
|
||||||
|
" models = [model],\n",
|
||||||
|
" image_config = image_config,\n",
|
||||||
|
" workspace = ws)\n",
|
||||||
|
"\n",
|
||||||
|
"image.wait_for_creation(show_output = True)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"In case you need to debug your code, the next line of code accesses the log file."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"print(image.image_build_log_uri)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"We're all done specifying what we want our virtual machine to do. Let's configure and deploy our container image.\n",
|
||||||
|
"\n",
|
||||||
|
"### Deploy the container image"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.webservice import AciWebservice\n",
|
||||||
|
"\n",
|
||||||
|
"aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1, \n",
|
||||||
|
" memory_gb = 1, \n",
|
||||||
|
" tags = {'demo': 'onnx'}, \n",
|
||||||
|
" description = 'ONNX for mnist model')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"The following cell will likely take a few minutes to run as well."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.webservice import Webservice\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service_name = 'onnx-demo-mnist20'\n",
|
||||||
|
"print(\"Service\", aci_service_name)\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service = Webservice.deploy_from_image(deployment_config = aciconfig,\n",
|
||||||
|
" image = image,\n",
|
||||||
|
" name = aci_service_name,\n",
|
||||||
|
" workspace = ws)\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service.wait_for_deployment(True)\n",
|
||||||
|
"print(aci_service.state)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"if aci_service.state != 'Healthy':\n",
|
||||||
|
" # run this command for debugging.\n",
|
||||||
|
" print(aci_service.get_logs())\n",
|
||||||
|
"\n",
|
||||||
|
" # If your deployment fails, make sure to delete your aci_service or rename your service before trying again!\n",
|
||||||
|
" # aci_service.delete()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Success!\n",
|
||||||
|
"\n",
|
||||||
|
"If you've made it this far, you've deployed a working VM with a handwritten digit classifier running in the cloud using Azure ML. Congratulations!\n",
|
||||||
|
"\n",
|
||||||
|
"Let's see how well our model deals with our test images."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Testing and Evaluation\n",
|
||||||
|
"\n",
|
||||||
|
"### Load Test Data\n",
|
||||||
|
"\n",
|
||||||
|
"These are already in your directory from your ONNX model download (from the model zoo).\n",
|
||||||
|
"\n",
|
||||||
|
"Notice that our Model Zoo files have a .pb extension. This is because they are [protobuf files (Protocol Buffers)](https://developers.google.com/protocol-buffers/docs/pythontutorial), so we need to read in our data through our ONNX TensorProto reader into a format we can work with, like numerical arrays."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# to manipulate our arrays\n",
|
||||||
|
"import numpy as np \n",
|
||||||
|
"\n",
|
||||||
|
"# read in test data protobuf files included with the model\n",
|
||||||
|
"import onnx\n",
|
||||||
|
"from onnx import numpy_helper\n",
|
||||||
|
"\n",
|
||||||
|
"# to use parsers to read in our model/data\n",
|
||||||
|
"import json\n",
|
||||||
|
"import os\n",
|
||||||
|
"\n",
|
||||||
|
"test_inputs = []\n",
|
||||||
|
"test_outputs = []\n",
|
||||||
|
"\n",
|
||||||
|
"# read in 3 testing images from .pb files\n",
|
||||||
|
"test_data_size = 3\n",
|
||||||
|
"\n",
|
||||||
|
"for i in np.arange(test_data_size):\n",
|
||||||
|
" input_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'input_0.pb')\n",
|
||||||
|
" output_test_data = os.path.join(model_dir, 'test_data_set_{0}'.format(i), 'output_0.pb')\n",
|
||||||
|
" \n",
|
||||||
|
" # convert protobuf tensors to np arrays using the TensorProto reader from ONNX\n",
|
||||||
|
" tensor = onnx.TensorProto()\n",
|
||||||
|
" with open(input_test_data, 'rb') as f:\n",
|
||||||
|
" tensor.ParseFromString(f.read())\n",
|
||||||
|
" \n",
|
||||||
|
" input_data = numpy_helper.to_array(tensor)\n",
|
||||||
|
" test_inputs.append(input_data)\n",
|
||||||
|
" \n",
|
||||||
|
" with open(output_test_data, 'rb') as f:\n",
|
||||||
|
" tensor.ParseFromString(f.read())\n",
|
||||||
|
" \n",
|
||||||
|
" output_data = numpy_helper.to_array(tensor)\n",
|
||||||
|
" test_outputs.append(output_data)\n",
|
||||||
|
" \n",
|
||||||
|
"if len(test_inputs) == test_data_size:\n",
|
||||||
|
" print('Test data loaded successfully.')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {
|
||||||
|
"nbpresent": {
|
||||||
|
"id": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"source": [
|
||||||
|
"### Show some sample images\n",
|
||||||
|
"We use `matplotlib` to plot 3 test images from the dataset."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {
|
||||||
|
"nbpresent": {
|
||||||
|
"id": "396d478b-34aa-4afa-9898-cdce8222a516"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"plt.figure(figsize = (16, 6))\n",
|
||||||
|
"for test_image in np.arange(3):\n",
|
||||||
|
" plt.subplot(1, 15, test_image+1)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
" plt.imshow(test_inputs[test_image].reshape(28, 28), cmap = plt.cm.Greys)\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Run evaluation / prediction"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"plt.figure(figsize = (16, 6), frameon=False)\n",
|
||||||
|
"plt.subplot(1, 8, 1)\n",
|
||||||
|
"\n",
|
||||||
|
"plt.text(x = 0, y = -30, s = \"True Label: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 0, y = -20, s = \"Result: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 0, y = -10, s = \"Inference Time: \", fontsize = 13, color = 'black')\n",
|
||||||
|
"plt.text(x = 3, y = 14, s = \"Model Input\", fontsize = 12, color = 'black')\n",
|
||||||
|
"plt.text(x = 6, y = 18, s = \"(28 x 28)\", fontsize = 12, color = 'black')\n",
|
||||||
|
"plt.imshow(np.ones((28,28)), cmap=plt.cm.Greys) \n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"for i in np.arange(test_data_size):\n",
|
||||||
|
" \n",
|
||||||
|
" input_data = json.dumps({'data': test_inputs[i].tolist()})\n",
|
||||||
|
" \n",
|
||||||
|
" # predict using the deployed model\n",
|
||||||
|
" r = json.loads(aci_service.run(input_data))\n",
|
||||||
|
" \n",
|
||||||
|
" if \"error\" in r:\n",
|
||||||
|
" print(r['error'])\n",
|
||||||
|
" break\n",
|
||||||
|
" \n",
|
||||||
|
" result = r['result'][0]\n",
|
||||||
|
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
||||||
|
" \n",
|
||||||
|
" ground_truth = int(np.argmax(test_outputs[i]))\n",
|
||||||
|
" \n",
|
||||||
|
" # compare actual value vs. the predicted values:\n",
|
||||||
|
" plt.subplot(1, 8, i+2)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
"\n",
|
||||||
|
" # use different color for misclassified sample\n",
|
||||||
|
" font_color = 'red' if ground_truth != result else 'black'\n",
|
||||||
|
" clr_map = plt.cm.gray if ground_truth != result else plt.cm.Greys\n",
|
||||||
|
"\n",
|
||||||
|
" # ground truth labels are in blue\n",
|
||||||
|
" plt.text(x = 10, y = -30, s = ground_truth, fontsize = 18, color = 'blue')\n",
|
||||||
|
" \n",
|
||||||
|
" # predictions are in black if correct, red if incorrect\n",
|
||||||
|
" plt.text(x = 10, y = -20, s = result, fontsize = 18, color = font_color)\n",
|
||||||
|
" plt.text(x = 5, y = -10, s = str(time_ms) + ' ms', fontsize = 14, color = font_color)\n",
|
||||||
|
"\n",
|
||||||
|
" \n",
|
||||||
|
" plt.imshow(test_inputs[i].reshape(28, 28), cmap = clr_map)\n",
|
||||||
|
"\n",
|
||||||
|
"plt.show()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Try classifying your own images!\n",
|
||||||
|
"\n",
|
||||||
|
"Create your own handwritten image and pass it into the model."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Preprocessing functions take your image and format it so it can be passed\n",
|
||||||
|
"# as input into our ONNX model\n",
|
||||||
|
"\n",
|
||||||
|
"import cv2\n",
|
||||||
|
"\n",
|
||||||
|
"def rgb2gray(rgb):\n",
|
||||||
|
" \"\"\"Convert the input image into grayscale\"\"\"\n",
|
||||||
|
" return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])\n",
|
||||||
|
"\n",
|
||||||
|
"def resize_img(img):\n",
|
||||||
|
" \"\"\"Resize image to MNIST model input dimensions\"\"\"\n",
|
||||||
|
" img = cv2.resize(img, dsize=(28, 28), interpolation=cv2.INTER_AREA)\n",
|
||||||
|
" img.resize((1, 1, 28, 28))\n",
|
||||||
|
" return img\n",
|
||||||
|
"\n",
|
||||||
|
"def preprocess(img):\n",
|
||||||
|
" \"\"\"Resize input images and convert them to grayscale.\"\"\"\n",
|
||||||
|
" if img.shape == (28, 28):\n",
|
||||||
|
" img.resize((1, 1, 28, 28))\n",
|
||||||
|
" return img\n",
|
||||||
|
" \n",
|
||||||
|
" grayscale = rgb2gray(img)\n",
|
||||||
|
" processed_img = resize_img(grayscale)\n",
|
||||||
|
" return processed_img"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# Replace this string with your own path/test image\n",
|
||||||
|
"# Make sure your image is square and the dimensions are equal (i.e. 100 * 100 pixels or 28 * 28 pixels)\n",
|
||||||
|
"\n",
|
||||||
|
"# Any PNG or JPG image file should work\n",
|
||||||
|
"\n",
|
||||||
|
"# e.g. your_test_image = \"C:/Users/vinitra.swamy/Pictures/handwritten_digit.png\"\n",
|
||||||
|
"\n",
|
||||||
|
"import matplotlib.image as mpimg\n",
|
||||||
|
"\n",
|
||||||
|
"if your_test_image != \"<path to file>\":\n",
|
||||||
|
" img = mpimg.imread(your_test_image)\n",
|
||||||
|
" plt.subplot(1,3,1)\n",
|
||||||
|
" plt.imshow(img, cmap = plt.cm.Greys)\n",
|
||||||
|
" print(\"Old Dimensions: \", img.shape)\n",
|
||||||
|
" img = preprocess(img)\n",
|
||||||
|
" print(\"New Dimensions: \", img.shape)\n",
|
||||||
|
"else:\n",
|
||||||
|
" img = None"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"if img is None:\n",
|
||||||
|
" print(\"Add the path for your image data.\")\n",
|
||||||
|
"else:\n",
|
||||||
|
" input_data = json.dumps({'data': img.tolist()})\n",
|
||||||
|
"\n",
|
||||||
|
" try:\n",
|
||||||
|
" r = json.loads(aci_service.run(input_data))\n",
|
||||||
|
" result = r['result'][0]\n",
|
||||||
|
" time_ms = np.round(r['time_in_sec'][0] * 1000, 2)\n",
|
||||||
|
" except Exception as e:\n",
|
||||||
|
" print(str(e))\n",
|
||||||
|
"\n",
|
||||||
|
" plt.figure(figsize = (16, 6))\n",
|
||||||
|
" plt.subplot(1, 15,1)\n",
|
||||||
|
" plt.axhline('')\n",
|
||||||
|
" plt.axvline('')\n",
|
||||||
|
" plt.text(x = -100, y = -20, s = \"Model prediction: \", fontsize = 14)\n",
|
||||||
|
" plt.text(x = -100, y = -10, s = \"Inference time: \", fontsize = 14)\n",
|
||||||
|
" plt.text(x = 0, y = -20, s = str(result), fontsize = 14)\n",
|
||||||
|
" plt.text(x = 0, y = -10, s = str(time_ms) + \" ms\", fontsize = 14)\n",
|
||||||
|
" plt.text(x = -100, y = 14, s = \"Input image: \", fontsize = 14)\n",
|
||||||
|
" plt.imshow(img.reshape(28, 28), cmap = plt.cm.gray) "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Optional: How does our ONNX MNIST model work? \n",
|
||||||
|
"#### A brief explanation of Convolutional Neural Networks\n",
|
||||||
|
"\n",
|
||||||
|
"A [convolutional neural network](https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN, or ConvNet) is a type of [feed-forward](https://en.wikipedia.org/wiki/Feedforward_neural_network) artificial neural network made up of neurons that have learnable weights and biases. The CNNs take advantage of the spatial nature of the data. In nature, we perceive different objects by their shapes, size and colors. For example, objects in a natural scene are typically edges, corners/vertices (defined by two of more edges), color patches etc. These primitives are often identified using different detectors (e.g., edge detection, color detector) or combination of detectors interacting to facilitate image interpretation (object classification, region of interest detection, scene description etc.) in real world vision related tasks. These detectors are also known as filters. Convolution is a mathematical operator that takes an image and a filter as input and produces a filtered output (representing say edges, corners, or colors in the input image). \n",
|
||||||
|
"\n",
|
||||||
|
"Historically, these filters are a set of weights that were often hand crafted or modeled with mathematical functions (e.g., [Gaussian](https://en.wikipedia.org/wiki/Gaussian_filter) / [Laplacian](http://homepages.inf.ed.ac.uk/rbf/HIPR2/log.htm) / [Canny](https://en.wikipedia.org/wiki/Canny_edge_detector) filter). The filter outputs are mapped through non-linear activation functions mimicking human brain cells called [neurons](https://en.wikipedia.org/wiki/Neuron). Popular deep CNNs or ConvNets (such as [AlexNet](https://en.wikipedia.org/wiki/AlexNet), [VGG](https://arxiv.org/abs/1409.1556), [Inception](http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf), [ResNet](https://arxiv.org/pdf/1512.03385v1.pdf)) that are used for various [computer vision](https://en.wikipedia.org/wiki/Computer_vision) tasks have many of these architectural primitives (inspired from biology). \n",
|
||||||
|
"\n",
|
||||||
|
"### Convolution Layer\n",
|
||||||
|
"\n",
|
||||||
|
"A convolution layer is a set of filters. Each filter is defined by a weight (**W**) matrix, and bias ($b$).\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"These filters are scanned across the image performing the dot product between the weights and corresponding input value ($x$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"Image(url=\"https://www.cntk.ai/jup/cntk103d_conv2d_final.gif\", width= 200)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Model Description\n",
|
||||||
|
"\n",
|
||||||
|
"The MNIST model from the ONNX Model Zoo uses maxpooling to update the weights in its convolutions, summarized by the graphic below. You can see the entire workflow of our pre-trained model in the following image, with our input images and our output probabilities of each of our 10 labels. If you're interested in exploring the logic behind creating a Deep Learning model further, please look at the [training tutorial for our ONNX MNIST Convolutional Neural Network](https://github.com/Microsoft/CNTK/blob/master/Tutorials/CNTK_103D_MNIST_ConvolutionalNeuralNetwork.ipynb). "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Max-Pooling for Convolutional Neural Nets\n",
|
||||||
|
"\n",
|
||||||
|
""
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"#### Pre-Trained Model Architecture\n",
|
||||||
|
"\n",
|
||||||
|
""
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# remember to delete your service after you are done using it!\n",
|
||||||
|
"\n",
|
||||||
|
"aci_service.delete()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Conclusion\n",
|
||||||
|
"\n",
|
||||||
|
"Congratulations!\n",
|
||||||
|
"\n",
|
||||||
|
"In this tutorial, you have:\n",
|
||||||
|
"- familiarized yourself with ONNX Runtime inference and the pretrained models in the ONNX model zoo\n",
|
||||||
|
"- understood a state-of-the-art convolutional neural net image classification model (MNIST in ONNX) and deployed it in Azure ML cloud\n",
|
||||||
|
"- ensured that your deep learning model is working perfectly (in the cloud) on test data, and checked it against some of your own!\n",
|
||||||
|
"\n",
|
||||||
|
"Next steps:\n",
|
||||||
|
"- Check out another interesting application based on a Microsoft Research computer vision paper that lets you set up a [facial emotion recognition model](https://github.com/Azure/MachineLearningNotebooks/tree/master/onnx/onnx-inference-emotion-recognition.ipynb) in the cloud! This tutorial deploys a pre-trained ONNX Computer Vision model in an Azure ML virtual machine.\n",
|
||||||
|
"- Contribute to our [open source ONNX repository on github](http://github.com/onnx/onnx) and/or add to our [ONNX model zoo](http://github.com/onnx/models)"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"authors": [
|
||||||
|
{
|
||||||
|
"name": "viswamy"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3.6",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python36"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.6.6"
|
||||||
|
},
|
||||||
|
"msauthor": "vinitra.swamy"
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 2
|
||||||
|
}
|
||||||
@@ -56,21 +56,11 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"#### Download pre-trained ONNX model from ONNX Model Zoo.\n",
|
"#### Download pre-trained ONNX model from ONNX Model Zoo.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Download the [ResNet50v2 model and test data](https://s3.amazonaws.com/onnx-model-zoo/resnet/resnet50v2/resnet50v2.tar.gz) and extract it in the same folder as this tutorial notebook.\n"
|
"Download the [ResNet50v2 model and test data](https://s3.amazonaws.com/onnx-model-zoo/resnet/resnet50v2/resnet50v2.tar.gz) and place it in the same folder as this tutorial notebook. You can unzip the file through the following line of code.\n",
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"import urllib.request\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"onnx_model_url = \"https://s3.amazonaws.com/onnx-model-zoo/resnet/resnet50v2/resnet50v2.tar.gz\"\n",
|
"```sh\n",
|
||||||
"urllib.request.urlretrieve(onnx_model_url, filename=\"resnet50v2.tar.gz\")\n",
|
"(myenv) $ tar xvzf resnet50v2.tar.gz\n",
|
||||||
"\n",
|
"```"
|
||||||
"!tar xvzf resnet50v2.tar.gz"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -140,9 +130,9 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"models = ws.models\n",
|
"models = ws.models()\n",
|
||||||
"for name, m in models.items():\n",
|
"for m in models:\n",
|
||||||
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
" print(\"Name:\", m.name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -232,7 +222,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
"\n",
|
"\n",
|
||||||
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\",\"azureml-core\"])\n",
|
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\"])\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
" f.write(myenv.serialize_to_string())"
|
" f.write(myenv.serialize_to_string())"
|
||||||
|
|||||||
@@ -76,9 +76,9 @@
|
|||||||
"## Train model\n",
|
"## Train model\n",
|
||||||
"\n",
|
"\n",
|
||||||
"### Create a remote compute target\n",
|
"### Create a remote compute target\n",
|
||||||
"You will need to create a [compute target](https://docs.microsoft.com/azure/machine-learning/service/concept-azure-machine-learning-architecture#compute-target) to execute your training script on. In this tutorial, you create AmlCompute as your training compute resource. This code creates new compute for you if it does not already exist in your workspace.\n",
|
"You will need to create a [compute target](https://docs.microsoft.com/azure/machine-learning/service/concept-azure-machine-learning-architecture#compute-target) to execute your training script on. In this tutorial, you create an [Azure Batch AI](https://docs.microsoft.com/azure/batch-ai/overview) cluster as your training compute resource. This code creates a cluster for you if it does not already exist in your workspace.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"**Creation of the compute takes approximately 5 minutes.** If the compute is already in your workspace this code will skip the creation process."
|
"**Creation of the cluster takes approximately 5 minutes.** If the cluster is already in your workspace this code will skip the cluster creation process."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -87,7 +87,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -98,8 +98,10 @@
|
|||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=4)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -249,26 +251,10 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Alternatively, you can block until the script has completed training before running more code."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
@@ -332,9 +318,9 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"models = ws.models\n",
|
"models = ws.models()\n",
|
||||||
"for name, m in models.items():\n",
|
"for m in models:\n",
|
||||||
" print(\"Name:\", name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
" print(\"Name:\", m.name,\"\\tVersion:\", m.version, \"\\tDescription:\", m.description, m.tags)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -406,7 +392,7 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
||||||
"\n",
|
"\n",
|
||||||
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\",\"azureml-core\"])\n",
|
"myenv = CondaDependencies.create(pip_packages=[\"numpy\",\"onnxruntime\"])\n",
|
||||||
"\n",
|
"\n",
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
"with open(\"myenv.yml\",\"w\") as f:\n",
|
||||||
" f.write(myenv.serialize_to_string())"
|
" f.write(myenv.serialize_to_string())"
|
||||||
@@ -585,7 +571,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.5.6"
|
||||||
},
|
},
|
||||||
"widgets": {
|
"widgets": {
|
||||||
"application/vnd.jupyter.widget-state+json": {
|
"application/vnd.jupyter.widget-state+json": {
|
||||||
@@ -597,7 +583,7 @@
|
|||||||
"state": {}
|
"state": {}
|
||||||
},
|
},
|
||||||
"d146cbdbd4e04710b3eebc15a66957ce": {
|
"d146cbdbd4e04710b3eebc15a66957ce": {
|
||||||
"model_module": "azureml_widgets",
|
"model_module": "azureml_train_widgets",
|
||||||
"model_module_version": "1.0.0",
|
"model_module_version": "1.0.0",
|
||||||
"model_name": "ShowRunDetailsModel",
|
"model_name": "ShowRunDetailsModel",
|
||||||
"state": {
|
"state": {
|
||||||
|
|||||||
@@ -40,8 +40,8 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"!jupyter nbextension install --py --user azureml.widgets\n",
|
"!jupyter nbextension install --py --user azureml.train.widgets\n",
|
||||||
"!jupyter nbextension enable --py --user azureml.widgets"
|
"!jupyter nbextension enable --py --user azureml.train.widgets"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -52,7 +52,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import AmlCompute, ComputeTarget\n",
|
"from azureml.core.compute import BatchAiCompute, ComputeTarget\n",
|
||||||
"from azureml.core.datastore import Datastore\n",
|
"from azureml.core.datastore import Datastore\n",
|
||||||
"from azureml.data.data_reference import DataReference\n",
|
"from azureml.data.data_reference import DataReference\n",
|
||||||
"from azureml.pipeline.core import Pipeline, PipelineData\n",
|
"from azureml.pipeline.core import Pipeline, PipelineData\n",
|
||||||
@@ -74,35 +74,21 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import os\n",
|
"# Batch AI compute\n",
|
||||||
"\n",
|
"cluster_name = \"gpu-cluster\"\n",
|
||||||
"# choose a name for your cluster\n",
|
"try:\n",
|
||||||
"compute_name = os.environ.get(\"BATCHAI_CLUSTER_NAME\", \"gpucluster\")\n",
|
" cluster = BatchAiCompute(ws, cluster_name)\n",
|
||||||
"compute_min_nodes = os.environ.get(\"BATCHAI_CLUSTER_MIN_NODES\", 0)\n",
|
" print(\"found existing cluster.\")\n",
|
||||||
"compute_max_nodes = os.environ.get(\"BATCHAI_CLUSTER_MAX_NODES\", 4)\n",
|
"except:\n",
|
||||||
"vm_size = os.environ.get(\"BATCHAI_CLUSTER_SKU\", \"STANDARD_NC6\")\n",
|
" print(\"creating new cluster\")\n",
|
||||||
"\n",
|
" provisioning_config = BatchAiCompute.provisioning_configuration(vm_size = \"STANDARD_NC6\",\n",
|
||||||
"\n",
|
" autoscale_enabled = True,\n",
|
||||||
"if compute_name in ws.compute_targets:\n",
|
" cluster_min_nodes = 0, \n",
|
||||||
" compute_target = ws.compute_targets[compute_name]\n",
|
" cluster_max_nodes = 1)\n",
|
||||||
" if compute_target and type(compute_target) is AmlCompute:\n",
|
|
||||||
" print('found compute target. just use it. ' + compute_name)\n",
|
|
||||||
"else:\n",
|
|
||||||
" print('creating a new compute target...')\n",
|
|
||||||
" provisioning_config = AmlCompute.provisioning_configuration(vm_size = vm_size, # NC6 is GPU-enabled\n",
|
|
||||||
" vm_priority = 'lowpriority', # optional\n",
|
|
||||||
" min_nodes = compute_min_nodes, \n",
|
|
||||||
" max_nodes = compute_max_nodes)\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, compute_name, provisioning_config)\n",
|
" cluster = ComputeTarget.create(ws, cluster_name, provisioning_config)\n",
|
||||||
" \n",
|
" cluster.wait_for_completion(show_output=True)"
|
||||||
" # can poll for a minimum number of nodes and for a specific timeout. \n",
|
|
||||||
" # if no min node count is provided it will use the scale settings for the cluster\n",
|
|
||||||
" compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)\n",
|
|
||||||
" \n",
|
|
||||||
" # For a more detailed view of current BatchAI cluster status, use the 'status' property \n",
|
|
||||||
" print(compute_target.status.serialize())"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -370,7 +356,7 @@
|
|||||||
" mode=\"download\" \n",
|
" mode=\"download\" \n",
|
||||||
" )\n",
|
" )\n",
|
||||||
"output_dir = PipelineData(name=\"scores\", \n",
|
"output_dir = PipelineData(name=\"scores\", \n",
|
||||||
" datastore=default_ds, \n",
|
" datastore_name=default_ds.name, \n",
|
||||||
" output_path_on_compute=\"batchscoring/results\")"
|
" output_path_on_compute=\"batchscoring/results\")"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -413,15 +399,13 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.runconfig import DEFAULT_GPU_IMAGE\n",
|
"cd = CondaDependencies.create(pip_packages=[\"tensorflow-gpu==1.4.0\", \"azureml-defaults\"])\n",
|
||||||
"\n",
|
|
||||||
"cd = CondaDependencies.create(pip_packages=[\"tensorflow-gpu==1.10.0\", \"azureml-defaults\"])\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"# Runconfig\n",
|
"# Runconfig\n",
|
||||||
"batchai_run_config = RunConfiguration(conda_dependencies=cd)\n",
|
"batchai_run_config = RunConfiguration(conda_dependencies=cd)\n",
|
||||||
"batchai_run_config.environment.docker.enabled = True\n",
|
"batchai_run_config.environment.docker.enabled = True\n",
|
||||||
"batchai_run_config.environment.docker.gpu_support = True\n",
|
"batchai_run_config.environment.docker.gpu_support = True\n",
|
||||||
"batchai_run_config.environment.docker.base_image = DEFAULT_GPU_IMAGE\n",
|
"batchai_run_config.environment.docker.base_image = \"microsoft/mmlspark:gpu-0.12\"\n",
|
||||||
"batchai_run_config.environment.spark.precache_packages = False"
|
"batchai_run_config.environment.spark.precache_packages = False"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -465,7 +449,7 @@
|
|||||||
" \"--label_dir\", label_dir, \n",
|
" \"--label_dir\", label_dir, \n",
|
||||||
" \"--output_dir\", output_dir, \n",
|
" \"--output_dir\", output_dir, \n",
|
||||||
" \"--batch_size\", batch_size_param],\n",
|
" \"--batch_size\", batch_size_param],\n",
|
||||||
" compute_target=compute_target,\n",
|
" target=cluster,\n",
|
||||||
" inputs=[input_images, label_dir],\n",
|
" inputs=[input_images, label_dir],\n",
|
||||||
" outputs=[output_dir],\n",
|
" outputs=[output_dir],\n",
|
||||||
" runconfig=batchai_run_config,\n",
|
" runconfig=batchai_run_config,\n",
|
||||||
@@ -496,7 +480,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(pipeline_run).show()"
|
"RunDetails(pipeline_run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -606,12 +590,9 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"from azureml.pipeline.core import PublishedPipeline\n",
|
"from azureml.pipeline.core import PublishedPipeline\n",
|
||||||
"\n",
|
"\n",
|
||||||
"rest_endpoint = published_pipeline.endpoint\n",
|
"rest_endpoint = PublishedPipeline.get_endpoint(published_id, ws)\n",
|
||||||
"# specify batch size when running the pipeline\n",
|
"# specify batch size when running the pipeline\n",
|
||||||
"response = requests.post(rest_endpoint, \n",
|
"response = requests.post(rest_endpoint, headers=aad_token, json={\"param_batch_size\": 50})\n",
|
||||||
" headers=aad_token, \n",
|
|
||||||
" json={\"ExperimentName\": \"batch_scoring\",\n",
|
|
||||||
" \"ParameterAssignments\": {\"param_batch_size\": 50}})\n",
|
|
||||||
"run_id = response.json()[\"Id\"]"
|
"run_id = response.json()[\"Id\"]"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -629,7 +610,7 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.pipeline.core.run import PipelineRun\n",
|
"from azureml.pipeline.core.run import PipelineRun\n",
|
||||||
"published_pipeline_run = PipelineRun(ws.experiments[\"batch_scoring\"], run_id)\n",
|
"published_pipeline_run = PipelineRun(ws.experiments()[\"batch_scoring\"], run_id)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"RunDetails(published_pipeline_run).show()"
|
"RunDetails(published_pipeline_run).show()"
|
||||||
]
|
]
|
||||||
@@ -656,7 +637,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.6.6"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
14
pr.md
14
pr.md
@@ -12,18 +12,6 @@
|
|||||||
## Community Blogs
|
## Community Blogs
|
||||||
- [Power Bat – How Spektacom is Powering the Game of Cricket with Microsoft AI](https://blogs.technet.microsoft.com/machinelearning/2018/10/11/power-bat-how-spektacom-is-powering-the-game-of-cricket-with-microsoft-ai/)
|
- [Power Bat – How Spektacom is Powering the Game of Cricket with Microsoft AI](https://blogs.technet.microsoft.com/machinelearning/2018/10/11/power-bat-how-spektacom-is-powering-the-game-of-cricket-with-microsoft-ai/)
|
||||||
|
|
||||||
## Ignite 2018 Public Preview Launch Sessions
|
|
||||||
- [AI with Azure Machine Learning services: Simplifying the data science process](https://myignite.techcommunity.microsoft.com/sessions/66248)
|
|
||||||
- [AI TechTalk: Azure Machine Learning SDK - a walkthrough](https://myignite.techcommunity.microsoft.com/sessions/66265)
|
|
||||||
- [AI for an intelligent cloud and intelligent edge: Discover, deploy, and manage with Azure ML services](https://myignite.techcommunity.microsoft.com/sessions/65389)
|
|
||||||
- [Generating high quality models efficiently using Automated ML and Hyperparameter Tuning](https://myignite.techcommunity.microsoft.com/sessions/66245)
|
|
||||||
- [AI for pros: Deep learning with PyTorch using the Azure Data Science Virtual Machine and scaling training with Azure ML](https://myignite.techcommunity.microsoft.com/sessions/66244)
|
|
||||||
|
|
||||||
## Get-started Videos on YouTube
|
|
||||||
- [Get started with Python SDK](https://youtu.be/VIsXeTuW3FU)
|
|
||||||
- [Get started from Azure Portal](https://youtu.be/lCkYUHV86Mk)
|
|
||||||
|
|
||||||
|
|
||||||
## Third Party Articles
|
## Third Party Articles
|
||||||
- [Azure’s new machine learning features embrace Python](https://www.infoworld.com/article/3306840/azure/azures-new-machine-learning-features-embrace-python.html) (InfoWorld)
|
- [Azure’s new machine learning features embrace Python](https://www.infoworld.com/article/3306840/azure/azures-new-machine-learning-features-embrace-python.html) (InfoWorld)
|
||||||
- [How to use Azure ML in Windows 10](https://www.infoworld.com/article/3308381/azure/how-to-use-azure-ml-in-windows-10.html) (InfoWorld)
|
- [How to use Azure ML in Windows 10](https://www.infoworld.com/article/3308381/azure/how-to-use-azure-ml-in-windows-10.html) (InfoWorld)
|
||||||
@@ -36,7 +24,7 @@
|
|||||||
## Community Projects
|
## Community Projects
|
||||||
- [Fashion MNIST](https://github.com/amynic/azureml-sdk-fashion)
|
- [Fashion MNIST](https://github.com/amynic/azureml-sdk-fashion)
|
||||||
- Keras on Databricks
|
- Keras on Databricks
|
||||||
- [Samples from CSS](https://github.com/Azure/AMLSamples)
|
- Samples from CSS
|
||||||
|
|
||||||
|
|
||||||
## Azure Machine Learning Studio Resources
|
## Azure Machine Learning Studio Resources
|
||||||
|
|||||||
@@ -434,13 +434,12 @@
|
|||||||
"from azureml.core.image import Image\n",
|
"from azureml.core.image import Image\n",
|
||||||
"from azureml.core.webservice import Webservice\n",
|
"from azureml.core.webservice import Webservice\n",
|
||||||
"from azureml.contrib.brainwave import BrainwaveWebservice, BrainwaveImage\n",
|
"from azureml.contrib.brainwave import BrainwaveWebservice, BrainwaveImage\n",
|
||||||
"from azureml.exceptions import WebserviceException\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"model_name = \"catsanddogs-resnet50-model\"\n",
|
"model_name = \"catsanddogs-resnet50-model\"\n",
|
||||||
"image_name = \"catsanddogs-resnet50-image\"\n",
|
"image_name = \"catsanddogs-resnet50-image\"\n",
|
||||||
"service_name = \"modelbuild-service\"\n",
|
"service_name = \"modelbuild-service\"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"registered_model = Model.register(ws, model_def_path, model_name)\n",
|
"registered_model = Model.register(ws, service_def_path, model_name)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"image_config = BrainwaveImage.image_configuration()\n",
|
"image_config = BrainwaveImage.image_configuration()\n",
|
||||||
"deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
"deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
||||||
@@ -449,10 +448,8 @@
|
|||||||
" service = Webservice(ws, service_name)\n",
|
" service = Webservice(ws, service_name)\n",
|
||||||
" service.delete()\n",
|
" service.delete()\n",
|
||||||
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
||||||
" service.wait_for_deployment(True)\n",
|
|
||||||
"except WebserviceException:\n",
|
"except WebserviceException:\n",
|
||||||
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)"
|
||||||
" service.wait_for_deployment(True)"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -80,7 +80,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.contrib.brainwave.models import QuantizedResnet50\n",
|
"from azureml.contrib.brainwave.models import QuantizedResnet50, Resnet50\n",
|
||||||
"model_path = os.path.expanduser('~/models')\n",
|
"model_path = os.path.expanduser('~/models')\n",
|
||||||
"model = QuantizedResnet50(model_path, is_frozen = True)\n",
|
"model = QuantizedResnet50(model_path, is_frozen = True)\n",
|
||||||
"feature_tensor = model.import_graph_def(image_tensors)\n",
|
"feature_tensor = model.import_graph_def(image_tensors)\n",
|
||||||
@@ -198,7 +198,7 @@
|
|||||||
" image_config = BrainwaveImage.image_configuration()\n",
|
" image_config = BrainwaveImage.image_configuration()\n",
|
||||||
" deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
" deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
||||||
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
||||||
" service.wait_for_deployment(True)"
|
" service.wait_for_deployment(true)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -265,7 +265,9 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"service.delete()"
|
"service.delete()\n",
|
||||||
|
" \n",
|
||||||
|
"registered_model.delete()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -404,7 +404,7 @@
|
|||||||
" image_config = BrainwaveImage.image_configuration()\n",
|
" image_config = BrainwaveImage.image_configuration()\n",
|
||||||
" deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
" deployment_config = BrainwaveWebservice.deploy_configuration()\n",
|
||||||
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
" service = Webservice.deploy_from_model(ws, service_name, [registered_model], image_config, deployment_config)\n",
|
||||||
" service.wait_for_deployment(True)"
|
" service.wait_for_deployment(true)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -511,7 +511,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"New BSD License\n",
|
"New BSD License\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Copyright (c) 2007–2018 The scikit-learn developers.\n",
|
"Copyright (c) 2007\u00e2\u20ac\u201c2018 The scikit-learn developers.\n",
|
||||||
"All rights reserved.\n",
|
"All rights reserved.\n",
|
||||||
"\n",
|
"\n",
|
||||||
"\n",
|
"\n",
|
||||||
|
|||||||
BIN
project-brainwave/snowleopardgaze.jpg
Normal file
BIN
project-brainwave/snowleopardgaze.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 61 KiB |
@@ -104,7 +104,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -115,8 +115,10 @@
|
|||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -331,7 +333,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"script_params = {\n",
|
"script_params = {\n",
|
||||||
" '--data_dir': ds_data,\n",
|
" '--data_dir': ds_data,\n",
|
||||||
" '--num_epochs': 10,\n",
|
" '--num_epochs': 25,\n",
|
||||||
" '--output_dir': './outputs'\n",
|
" '--output_dir': './outputs'\n",
|
||||||
"}\n",
|
"}\n",
|
||||||
"\n",
|
"\n",
|
||||||
@@ -385,26 +387,10 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Alternatively, you can block until the script has completed training before running more code."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
@@ -445,7 +431,7 @@
|
|||||||
" policy=early_termination_policy,\n",
|
" policy=early_termination_policy,\n",
|
||||||
" primary_metric_name='best_val_acc',\n",
|
" primary_metric_name='best_val_acc',\n",
|
||||||
" primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,\n",
|
" primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,\n",
|
||||||
" max_total_runs=8,\n",
|
" max_total_runs=20,\n",
|
||||||
" max_concurrent_runs=4)"
|
" max_concurrent_runs=4)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -480,27 +466,11 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"\n",
|
"\n",
|
||||||
"RunDetails(hyperdrive_run).show()"
|
"RunDetails(hyperdrive_run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Or block until the HyperDrive sweep has completed:"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"hyperdrive_run.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
@@ -576,7 +546,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"### Create environment file\n",
|
"### Create environment file\n",
|
||||||
"Then, we will need to create an environment file (`myenv.yml`) that specifies all of the scoring script's package dependencies. This file is used to ensure that all of those dependencies are installed in the Docker image by AML. In this case, we need to specify `azureml-core`, `torch` and `torchvision`."
|
"Then, we will need to create an environment file (`myenv.yml`) that specifies all of the scoring script's package dependencies. This file is used to ensure that all of those dependencies are installed in the Docker image by AML. In this case, we need to specify `torch`, `torchvision`, `pillow`, and `azureml-sdk`."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -585,14 +555,16 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.conda_dependencies import CondaDependencies \n",
|
"%%writefile myenv.yml\n",
|
||||||
"\n",
|
"name: myenv\n",
|
||||||
"myenv = CondaDependencies.create(pip_packages=['azureml-core', 'torch', 'torchvision'])\n",
|
"channels:\n",
|
||||||
"\n",
|
" - defaults\n",
|
||||||
"with open(\"myenv.yml\",\"w\") as f:\n",
|
"dependencies:\n",
|
||||||
" f.write(myenv.serialize_to_string())\n",
|
" - pip:\n",
|
||||||
" \n",
|
" - torch\n",
|
||||||
"print(myenv.serialize_to_string())"
|
" - torchvision\n",
|
||||||
|
" - pillow\n",
|
||||||
|
" - azureml-core"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -644,7 +616,25 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"### Deploy the registered model\n",
|
"### Deploy the registered model\n",
|
||||||
"Finally, let's deploy a web service from our registered model. Deploy the web service using the ACI config and image config files created in the previous steps. We pass the `model` object in a list to the `models` parameter. If you would like to deploy more than one registered model, append the additional models to this list."
|
"Finally, let's deploy a web service from our registered model. First, retrieve the model from your workspace."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from azureml.core.model import Model\n",
|
||||||
|
"\n",
|
||||||
|
"model = Model(ws, name='pytorch-hymenoptera')"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Then, deploy the web service using the ACI config and image config files created in the previous steps. We pass the `model` object in a list to the `models` parameter. If you would like to deploy more than one registered model, append the additional models to this list."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -720,10 +710,18 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import os, json\n",
|
"import os, json, base64\n",
|
||||||
|
"from io import BytesIO\n",
|
||||||
"from PIL import Image\n",
|
"from PIL import Image\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
"\n",
|
"\n",
|
||||||
|
"def imgToBase64(img):\n",
|
||||||
|
" \"\"\"Convert pillow image to base64-encoded image\"\"\"\n",
|
||||||
|
" imgio = BytesIO()\n",
|
||||||
|
" img.save(imgio, 'JPEG')\n",
|
||||||
|
" img_str = base64.b64encode(imgio.getvalue())\n",
|
||||||
|
" return img_str.decode('utf-8')\n",
|
||||||
|
"\n",
|
||||||
"test_img = os.path.join('hymenoptera_data', 'val', 'bees', '10870992_eebeeb3a12.jpg') #arbitary image from val dataset\n",
|
"test_img = os.path.join('hymenoptera_data', 'val', 'bees', '10870992_eebeeb3a12.jpg') #arbitary image from val dataset\n",
|
||||||
"plt.imshow(Image.open(test_img))"
|
"plt.imshow(Image.open(test_img))"
|
||||||
]
|
]
|
||||||
@@ -734,42 +732,18 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import torch\n",
|
"base64Img = imgToBase64(Image.open(test_img))\n",
|
||||||
"from torchvision import transforms\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"def preprocess(image_file):\n",
|
"result = service.run(input_data=json.dumps({'data': base64Img}))\n",
|
||||||
" \"\"\"Preprocess the input image.\"\"\"\n",
|
"print(json.loads(result))"
|
||||||
" data_transforms = transforms.Compose([\n",
|
|
||||||
" transforms.Resize(256),\n",
|
|
||||||
" transforms.CenterCrop(224),\n",
|
|
||||||
" transforms.ToTensor(),\n",
|
|
||||||
" transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\n",
|
|
||||||
" ])\n",
|
|
||||||
"\n",
|
|
||||||
" image = Image.open(image_file)\n",
|
|
||||||
" image = data_transforms(image).float()\n",
|
|
||||||
" image = torch.tensor(image)\n",
|
|
||||||
" image = image.unsqueeze(0)\n",
|
|
||||||
" return image.numpy()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"input_data = preprocess(test_img)\n",
|
|
||||||
"result = service.run(input_data=json.dumps({'data': input_data.tolist()}))\n",
|
|
||||||
"print(result)"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"## Clean up\n",
|
"### Delete web service\n",
|
||||||
"Once you no longer need the web service, you can delete it with a simple API call."
|
"Once you no longer need the web service, you should delete it."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -803,7 +777,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.6.6"
|
||||||
},
|
},
|
||||||
"msauthor": "minxia"
|
"msauthor": "minxia"
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -5,10 +5,35 @@ import torch
|
|||||||
import torch.nn as nn
|
import torch.nn as nn
|
||||||
from torchvision import transforms
|
from torchvision import transforms
|
||||||
import json
|
import json
|
||||||
|
import base64
|
||||||
|
from io import BytesIO
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
from azureml.core.model import Model
|
from azureml.core.model import Model
|
||||||
|
|
||||||
|
|
||||||
|
def preprocess_image(image_file):
|
||||||
|
"""Preprocess the input image."""
|
||||||
|
data_transforms = transforms.Compose([
|
||||||
|
transforms.Resize(256),
|
||||||
|
transforms.CenterCrop(224),
|
||||||
|
transforms.ToTensor(),
|
||||||
|
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
||||||
|
])
|
||||||
|
|
||||||
|
image = Image.open(image_file)
|
||||||
|
image = data_transforms(image).float()
|
||||||
|
image = torch.tensor(image)
|
||||||
|
image = image.unsqueeze(0)
|
||||||
|
return image
|
||||||
|
|
||||||
|
|
||||||
|
def base64ToImg(base64ImgString):
|
||||||
|
base64Img = base64ImgString.encode('utf-8')
|
||||||
|
decoded_img = base64.b64decode(base64Img)
|
||||||
|
return BytesIO(decoded_img)
|
||||||
|
|
||||||
|
|
||||||
def init():
|
def init():
|
||||||
global model
|
global model
|
||||||
model_path = Model.get_model_path('pytorch-hymenoptera')
|
model_path = Model.get_model_path('pytorch-hymenoptera')
|
||||||
@@ -17,15 +42,16 @@ def init():
|
|||||||
|
|
||||||
|
|
||||||
def run(input_data):
|
def run(input_data):
|
||||||
input_data = torch.tensor(json.loads(input_data)['data'])
|
img = base64ToImg(json.loads(input_data)['data'])
|
||||||
|
img = preprocess_image(img)
|
||||||
|
|
||||||
# get prediction
|
# get prediction
|
||||||
with torch.no_grad():
|
output = model(img)
|
||||||
output = model(input_data)
|
|
||||||
classes = ['ants', 'bees']
|
classes = ['ants', 'bees']
|
||||||
softmax = nn.Softmax(dim=1)
|
softmax = nn.Softmax(dim=1)
|
||||||
pred_probs = softmax(output).numpy()[0]
|
pred_probs = softmax(model(img)).detach().numpy()[0]
|
||||||
index = torch.argmax(output, 1)
|
index = torch.argmax(output, 1)
|
||||||
|
|
||||||
result = {"label": classes[index], "probability": str(pred_probs[index])}
|
result = json.dumps({"label": classes[index], "probability": str(pred_probs[index])})
|
||||||
return result
|
return result
|
||||||
|
|||||||
@@ -59,7 +59,6 @@ def train_model(model, criterion, optimizer, scheduler, num_epochs, data_dir):
|
|||||||
dataloaders, dataset_sizes, class_names = load_data(data_dir)
|
dataloaders, dataset_sizes, class_names = load_data(data_dir)
|
||||||
|
|
||||||
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
|
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
|
||||||
|
|
||||||
since = time.time()
|
since = time.time()
|
||||||
|
|
||||||
best_model_wts = copy.deepcopy(model.state_dict())
|
best_model_wts = copy.deepcopy(model.state_dict())
|
||||||
@@ -147,15 +146,12 @@ def fine_tune_model(num_epochs, data_dir, learning_rate, momentum):
|
|||||||
criterion = nn.CrossEntropyLoss()
|
criterion = nn.CrossEntropyLoss()
|
||||||
|
|
||||||
# Observe that all parameters are being optimized
|
# Observe that all parameters are being optimized
|
||||||
optimizer_ft = optim.SGD(model_ft.parameters(),
|
optimizer_ft = optim.SGD(model_ft.parameters(), lr=learning_rate, momentum=momentum)
|
||||||
lr=learning_rate, momentum=momentum)
|
|
||||||
|
|
||||||
# Decay LR by a factor of 0.1 every 7 epochs
|
# Decay LR by a factor of 0.1 every 7 epochs
|
||||||
exp_lr_scheduler = lr_scheduler.StepLR(
|
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
|
||||||
optimizer_ft, step_size=7, gamma=0.1)
|
|
||||||
|
|
||||||
model = train_model(model_ft, criterion, optimizer_ft,
|
model = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs, data_dir)
|
||||||
exp_lr_scheduler, num_epochs, data_dir)
|
|
||||||
|
|
||||||
return model
|
return model
|
||||||
|
|
||||||
@@ -163,19 +159,15 @@ def fine_tune_model(num_epochs, data_dir, learning_rate, momentum):
|
|||||||
def main():
|
def main():
|
||||||
# get command-line arguments
|
# get command-line arguments
|
||||||
parser = argparse.ArgumentParser()
|
parser = argparse.ArgumentParser()
|
||||||
parser.add_argument('--data_dir', type=str,
|
parser.add_argument('--data_dir', type=str, help='directory of training data')
|
||||||
help='directory of training data')
|
parser.add_argument('--num_epochs', type=int, default=25, help='number of epochs to train')
|
||||||
parser.add_argument('--num_epochs', type=int, default=25,
|
|
||||||
help='number of epochs to train')
|
|
||||||
parser.add_argument('--output_dir', type=str, help='output directory')
|
parser.add_argument('--output_dir', type=str, help='output directory')
|
||||||
parser.add_argument('--learning_rate', type=float,
|
parser.add_argument('--learning_rate', type=float, default=0.001, help='learning rate')
|
||||||
default=0.001, help='learning rate')
|
|
||||||
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
|
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
|
||||||
args = parser.parse_args()
|
args = parser.parse_args()
|
||||||
|
|
||||||
print("data directory is: " + args.data_dir)
|
print("data directory is: " + args.data_dir)
|
||||||
model = fine_tune_model(args.num_epochs, args.data_dir,
|
model = fine_tune_model(args.num_epochs, args.data_dir, args.learning_rate, args.momentum)
|
||||||
args.learning_rate, args.momentum)
|
|
||||||
os.makedirs(args.output_dir, exist_ok=True)
|
os.makedirs(args.output_dir, exist_ok=True)
|
||||||
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
|
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
|
||||||
|
|
||||||
|
|||||||
@@ -103,7 +103,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -114,8 +114,10 @@
|
|||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -262,7 +264,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -1 +0,0 @@
|
|||||||
/data/
|
|
||||||
@@ -225,23 +225,9 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"## Upload MNIST dataset to default datastore \n",
|
"## Upload MNIST dataset to default datastore \n",
|
||||||
"A [datastore](https://docs.microsoft.com/azure/machine-learning/service/how-to-access-data) is a place where data can be stored that is then made accessible to a Run either by means of mounting or copying the data to the compute target. A datastore can either be backed by an Azure Blob Storage or and Azure File Share (ADLS will be supported in the future). For simple data handling, each workspace provides a default datastore that can be used, in case the data is not already in Blob Storage or File Share."
|
"A [datastore](https://docs.microsoft.com/azure/machine-learning/service/how-to-access-data) is a place where data can be stored that is then made accessible to a Run either by means of mounting or copying the data to the compute target. A datastore can either be backed by an Azure Blob Storage or and Azure File Share (ADLS will be supported in the future). For simple data handling, each workspace provides a default datastore that can be used, in case the data is not already in Blob Storage or File Share.\n",
|
||||||
]
|
"\n",
|
||||||
},
|
"In this next step, we will upload the training and test set into the workspace's default datastore, which we will then later be mount on a Batch AI cluster for training.\n"
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ds = ws.get_default_datastore()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"In this next step, we will upload the training and test set into the workspace's default datastore, which we will then later be mount on a Batch AI cluster for training."
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -250,6 +236,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
|
"ds = ws.get_default_datastore()\n",
|
||||||
"ds.upload(src_dir='./data/mnist', target_path='mnist', overwrite=True, show_progress=True)"
|
"ds.upload(src_dir='./data/mnist', target_path='mnist', overwrite=True, show_progress=True)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -265,7 +252,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"If we could not find the cluster with the given name in the previous cell, then we will create a new cluster here. We will create a Batch AI Cluster of `STANDARD_NC6` GPU VMs. This process is broken down into 3 steps:\n",
|
"If we could not find the cluster with the given name in the previous cell, then we will create a new cluster here. We will create a Batch AI Cluster of `STANDARD_D2_V2` CPU VMs. This process is broken down into 3 steps:\n",
|
||||||
"1. create the configuration (this step is local and only takes a second)\n",
|
"1. create the configuration (this step is local and only takes a second)\n",
|
||||||
"2. create the Batch AI cluster (this step will take about **20 seconds**)\n",
|
"2. create the Batch AI cluster (this step will take about **20 seconds**)\n",
|
||||||
"3. provision the VMs to bring the cluster to the initial size (of 1 in this case). This step will take about **3-5 minutes** and is providing only sparse output in the process. Please make sure to wait until the call returns before moving to the next cell"
|
"3. provision the VMs to bring the cluster to the initial size (of 1 in this case). This step will take about **3-5 minutes** and is providing only sparse output in the process. Please make sure to wait until the call returns before moving to the next cell"
|
||||||
@@ -277,7 +264,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -286,15 +273,17 @@
|
|||||||
"try:\n",
|
"try:\n",
|
||||||
" # look for the existing cluster by name\n",
|
" # look for the existing cluster by name\n",
|
||||||
" compute_target = ComputeTarget(workspace=ws, name=cluster_name)\n",
|
" compute_target = ComputeTarget(workspace=ws, name=cluster_name)\n",
|
||||||
" if type(compute_target) is AmlCompute:\n",
|
" if type(compute_target) is BatchAiCompute:\n",
|
||||||
" print('Found existing compute target {}.'.format(cluster_name))\n",
|
" print('Found existing compute target {}.'.format(cluster_name))\n",
|
||||||
" else:\n",
|
" else:\n",
|
||||||
" print('{} exists but it is not a Batch AI cluster. Please choose a different name.'.format(cluster_name))\n",
|
" print('{} exists but it is not a Batch AI cluster. Please choose a different name.'.format(cluster_name))\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size=\"STANDARD_NC6\", # GPU-based VM\n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size=\"STANDARD_NC6\", # GPU-based VM\n",
|
||||||
" #vm_priority='lowpriority', # optional\n",
|
" #vm_priority='lowpriority', # optional\n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -311,7 +300,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"Now that you have created the compute target, let's see what the workspace's `compute_targets` property returns. You should now see one entry named 'gpucluster' of type BatchAI."
|
"Now that you have created the compute target, let's see what the workspace's `compute_targets()` function returns. You should now see one entry named 'gpucluster' of type BatchAI."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -320,7 +309,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"compute_targets = ws.compute_targets\n",
|
"compute_targets = ws.compute_targets()\n",
|
||||||
"for name, ct in compute_targets.items():\n",
|
"for name, ct in compute_targets.items():\n",
|
||||||
" print(name, ct.type, ct.provisioning_state)"
|
" print(name, ct.type, ct.provisioning_state)"
|
||||||
]
|
]
|
||||||
@@ -443,7 +432,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"run = exp.submit(est)"
|
"run = exp.submit(config=est)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -471,7 +460,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -491,15 +480,6 @@
|
|||||||
"run"
|
"run"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"run.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
@@ -748,10 +728,9 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"htc = HyperDriveRunConfig(estimator=est, \n",
|
"htc = HyperDriveRunConfig(estimator=est, \n",
|
||||||
" hyperparameter_sampling=ps, \n",
|
" hyperparameter_sampling=ps, \n",
|
||||||
" policy=policy, \n",
|
|
||||||
" primary_metric_name='validation_acc', \n",
|
" primary_metric_name='validation_acc', \n",
|
||||||
" primary_metric_goal=PrimaryMetricGoal.MAXIMIZE, \n",
|
" primary_metric_goal=PrimaryMetricGoal.MAXIMIZE, \n",
|
||||||
" max_total_runs=8,\n",
|
" max_total_runs=20,\n",
|
||||||
" max_concurrent_runs=4)"
|
" max_concurrent_runs=4)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -787,15 +766,6 @@
|
|||||||
"RunDetails(htr).show()"
|
"RunDetails(htr).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"htr.wait_for_completion(show_output=True)"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
@@ -826,7 +796,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"print(best_run.get_file_names())"
|
"print(best_run.get_file_names()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -889,7 +859,7 @@
|
|||||||
" # make prediction\n",
|
" # make prediction\n",
|
||||||
" out = output.eval(session = sess, feed_dict = {X: data})\n",
|
" out = output.eval(session = sess, feed_dict = {X: data})\n",
|
||||||
" y_hat = np.argmax(out, axis = 1)\n",
|
" y_hat = np.argmax(out, axis = 1)\n",
|
||||||
" return y_hat.tolist()"
|
" return json.dumps(y_hat.tolist())"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -1041,7 +1011,7 @@
|
|||||||
"test_samples = bytes(test_samples, encoding = 'utf8')\n",
|
"test_samples = bytes(test_samples, encoding = 'utf8')\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# predict using the deployed model\n",
|
"# predict using the deployed model\n",
|
||||||
"result = service.run(input_data=test_samples)\n",
|
"result = json.loads(service.run(input_data = test_samples))\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# compare actual value vs. the predicted values:\n",
|
"# compare actual value vs. the predicted values:\n",
|
||||||
"i = 0\n",
|
"i = 0\n",
|
||||||
@@ -1109,15 +1079,15 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"models = ws.models\n",
|
"models = ws.models()\n",
|
||||||
"for name, model in models.items():\n",
|
"for name, model in models.items():\n",
|
||||||
" print(\"Model: {}, ID: {}\".format(name, model.id))\n",
|
" print(\"Model: {}, ID: {}\".format(name, model.id))\n",
|
||||||
" \n",
|
" \n",
|
||||||
"images = ws.images\n",
|
"images = ws.images()\n",
|
||||||
"for name, image in images.items():\n",
|
"for name, image in images.items():\n",
|
||||||
" print(\"Image: {}, location: {}\".format(name, image.image_location))\n",
|
" print(\"Image: {}, location: {}\".format(name, image.image_location))\n",
|
||||||
" \n",
|
" \n",
|
||||||
"webservices = ws.webservices\n",
|
"webservices = ws.webservices()\n",
|
||||||
"for name, webservice in webservices.items():\n",
|
"for name, webservice in webservices.items():\n",
|
||||||
" print(\"Webservice: {}, scoring URI: {}\".format(name, webservice.scoring_uri))"
|
" print(\"Webservice: {}, scoring URI: {}\".format(name, webservice.scoring_uri))"
|
||||||
]
|
]
|
||||||
@@ -1138,6 +1108,23 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"service.delete()"
|
"service.delete()"
|
||||||
]
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"We can also delete the computer cluster. But remember if you set the `cluster_min_nodes` value to 0 when you created the cluster, once the jobs are finished, all nodes are deleted automatically. So you don't have to delete the cluster itself since it won't incur any cost. Next time you submit jobs to it, the cluster will then automatically \"grow\" up to the `cluster_min_nodes` which is set to 4."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"# delete the cluster if you need to.\n",
|
||||||
|
"compute_target.delete()"
|
||||||
|
]
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
@@ -1163,7 +1150,505 @@
|
|||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.6"
|
"version": "3.6.6"
|
||||||
},
|
},
|
||||||
"msauthor": "minxia"
|
"nbpresent": {
|
||||||
|
"slides": {
|
||||||
|
"05bb34ad-74b0-42b3-9654-8357d1ba9c99": {
|
||||||
|
"id": "05bb34ad-74b0-42b3-9654-8357d1ba9c99",
|
||||||
|
"prev": "851089af-9725-40c9-8f0b-9bf892b2b1fe",
|
||||||
|
"regions": {
|
||||||
|
"23fb396d-50f9-4770-adb3-0d6abcb40767": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "2039d2d5-aca6-4f25-a12f-df9ae6529cae",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "23fb396d-50f9-4770-adb3-0d6abcb40767"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"11bebe14-d1dc-476d-a31a-5828b9c3adf0": {
|
||||||
|
"id": "11bebe14-d1dc-476d-a31a-5828b9c3adf0",
|
||||||
|
"prev": "502648cb-26fe-496b-899f-84c8fe1dcbc0",
|
||||||
|
"regions": {
|
||||||
|
"a42499db-623e-4414-bea2-ff3617fd8fc5": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "4788c040-27a2-4dc1-8ed0-378a99b3a255",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "a42499db-623e-4414-bea2-ff3617fd8fc5"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"134f92d0-6389-4226-af51-1134ae8e8278": {
|
||||||
|
"id": "134f92d0-6389-4226-af51-1134ae8e8278",
|
||||||
|
"prev": "36b8728c-32ad-4941-be03-5cef51cdc430",
|
||||||
|
"regions": {
|
||||||
|
"b6d82a77-2d58-4b9e-a375-3103214b826c": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "7ab0e6d0-1f1c-451b-8ac5-687da44a8287",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "b6d82a77-2d58-4b9e-a375-3103214b826c"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"282a2421-697b-4fd0-9485-755abf5a0c18": {
|
||||||
|
"id": "282a2421-697b-4fd0-9485-755abf5a0c18",
|
||||||
|
"prev": "a8b9ceb9-b38f-4489-84df-b644c6fe28f2",
|
||||||
|
"regions": {
|
||||||
|
"522fec96-abe7-4a34-bd34-633733afecc8": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "d58e7785-c2ee-4a45-8e3d-4c538bf8075a",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "522fec96-abe7-4a34-bd34-633733afecc8"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"2dfec088-8a70-411a-9199-904ef3fa2383": {
|
||||||
|
"id": "2dfec088-8a70-411a-9199-904ef3fa2383",
|
||||||
|
"prev": "282a2421-697b-4fd0-9485-755abf5a0c18",
|
||||||
|
"regions": {
|
||||||
|
"0535fcb6-3a2b-4b46-98a7-3ebb1a38c47e": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "c377ea0c-0cd9-4345-9be2-e20fb29c94c3",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "0535fcb6-3a2b-4b46-98a7-3ebb1a38c47e"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"36a814c9-c540-4a6d-92d9-c03553d3d2c2": {
|
||||||
|
"id": "36a814c9-c540-4a6d-92d9-c03553d3d2c2",
|
||||||
|
"prev": "b52e4d09-5186-44e5-84db-3371c087acde",
|
||||||
|
"regions": {
|
||||||
|
"8bfba503-9907-43f0-b1a6-46a0b4311793": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "d5e4a56c-dfac-4346-be83-1c15b503deac",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "8bfba503-9907-43f0-b1a6-46a0b4311793"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"36b8728c-32ad-4941-be03-5cef51cdc430": {
|
||||||
|
"id": "36b8728c-32ad-4941-be03-5cef51cdc430",
|
||||||
|
"prev": "05bb34ad-74b0-42b3-9654-8357d1ba9c99",
|
||||||
|
"regions": {
|
||||||
|
"a36a5bdf-7f62-49b0-8634-e155a98851dc": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "e33dfc47-e7df-4623-a7a6-ab6bcf944629",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "a36a5bdf-7f62-49b0-8634-e155a98851dc"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"3f136f2a-f14c-4a4b-afea-13380556a79c": {
|
||||||
|
"id": "3f136f2a-f14c-4a4b-afea-13380556a79c",
|
||||||
|
"prev": "54cb8dfd-a89c-4922-867b-3c87d8b67cd3",
|
||||||
|
"regions": {
|
||||||
|
"80ecf237-d1b0-401e-83d2-6d04b7fcebd3": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "7debeb2b-ecea-414f-9b50-49657abb3e6a",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "80ecf237-d1b0-401e-83d2-6d04b7fcebd3"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"502648cb-26fe-496b-899f-84c8fe1dcbc0": {
|
||||||
|
"id": "502648cb-26fe-496b-899f-84c8fe1dcbc0",
|
||||||
|
"prev": "3f136f2a-f14c-4a4b-afea-13380556a79c",
|
||||||
|
"regions": {
|
||||||
|
"4c83bb4d-2a52-41ba-a77f-0c6efebd83a6": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "dbd22f6b-6d49-4005-b8fe-422ef8ef1d42",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "4c83bb4d-2a52-41ba-a77f-0c6efebd83a6"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"54cb8dfd-a89c-4922-867b-3c87d8b67cd3": {
|
||||||
|
"id": "54cb8dfd-a89c-4922-867b-3c87d8b67cd3",
|
||||||
|
"prev": "aa224267-f885-4c0c-95af-7bacfcc186d9",
|
||||||
|
"regions": {
|
||||||
|
"0848f0a7-032d-46c7-b35c-bfb69c83f961": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "3c32c557-d0e8-4bb3-a61a-aa51a767cd4e",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "0848f0a7-032d-46c7-b35c-bfb69c83f961"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"636b563c-faee-4c9e-a6a3-f46a905bfa82": {
|
||||||
|
"id": "636b563c-faee-4c9e-a6a3-f46a905bfa82",
|
||||||
|
"prev": "c5f59b98-a227-4344-9d6d-03abdd01c6aa",
|
||||||
|
"regions": {
|
||||||
|
"9c64f662-05dc-4b14-9cdc-d450b96f4368": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "70640ac0-7041-47a8-9a7f-e871defd74b2",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "9c64f662-05dc-4b14-9cdc-d450b96f4368"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"793cec2f-8413-484d-aa1e-388fd2b53a45": {
|
||||||
|
"id": "793cec2f-8413-484d-aa1e-388fd2b53a45",
|
||||||
|
"prev": "c66f3dfd-2d27-482b-be78-10ba733e826b",
|
||||||
|
"regions": {
|
||||||
|
"d08f9cfa-3b8d-4fb4-91ba-82d9858ea93e": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "dd56113e-e3db-41ae-91b7-2472ed194308",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "d08f9cfa-3b8d-4fb4-91ba-82d9858ea93e"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"83e912ff-260a-4391-8a12-331aba098506": {
|
||||||
|
"id": "83e912ff-260a-4391-8a12-331aba098506",
|
||||||
|
"prev": "fe5a0732-69f5-462a-8af6-851f84a9fdec",
|
||||||
|
"regions": {
|
||||||
|
"2fefcf5f-ea20-4604-a528-5e6c91bcb100": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "c3f2f57c-7454-4d3e-b38d-b0946cf066ea",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "2fefcf5f-ea20-4604-a528-5e6c91bcb100"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"851089af-9725-40c9-8f0b-9bf892b2b1fe": {
|
||||||
|
"id": "851089af-9725-40c9-8f0b-9bf892b2b1fe",
|
||||||
|
"prev": "636b563c-faee-4c9e-a6a3-f46a905bfa82",
|
||||||
|
"regions": {
|
||||||
|
"31c9dda5-fdf4-45e2-bcb7-12aa0f30e1d8": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "8408b90e-6cdd-44d1-86d3-648c23f877ac",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "31c9dda5-fdf4-45e2-bcb7-12aa0f30e1d8"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"87ab653d-e804-470f-bde9-c67caaa0f354": {
|
||||||
|
"id": "87ab653d-e804-470f-bde9-c67caaa0f354",
|
||||||
|
"prev": "a8c2d446-caee-42c8-886a-ed98f4935d78",
|
||||||
|
"regions": {
|
||||||
|
"bc3aeb56-c465-4868-a1ea-2de82584de98": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "59f52294-4a25-4c92-bab8-3b07f0f44d15",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "bc3aeb56-c465-4868-a1ea-2de82584de98"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"8b887c97-83bc-4395-83ac-f6703cbe243d": {
|
||||||
|
"id": "8b887c97-83bc-4395-83ac-f6703cbe243d",
|
||||||
|
"prev": "36a814c9-c540-4a6d-92d9-c03553d3d2c2",
|
||||||
|
"regions": {
|
||||||
|
"9d0bc72a-cb13-483f-a572-2bf60d0d145f": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "75499c85-d0a1-43db-8244-25778b9b2736",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "9d0bc72a-cb13-483f-a572-2bf60d0d145f"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"a8b9ceb9-b38f-4489-84df-b644c6fe28f2": {
|
||||||
|
"id": "a8b9ceb9-b38f-4489-84df-b644c6fe28f2",
|
||||||
|
"prev": null,
|
||||||
|
"regions": {
|
||||||
|
"f741ed94-3f24-4427-b615-3ab8753e5814": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "bf74d2e9-2708-49b1-934b-e0ede342f475",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "f741ed94-3f24-4427-b615-3ab8753e5814"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"a8c2d446-caee-42c8-886a-ed98f4935d78": {
|
||||||
|
"id": "a8c2d446-caee-42c8-886a-ed98f4935d78",
|
||||||
|
"prev": "2dfec088-8a70-411a-9199-904ef3fa2383",
|
||||||
|
"regions": {
|
||||||
|
"f03457d8-b2a7-4e14-9a73-cab80c5b815d": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "edaa7f2f-2439-4148-b57a-8c794c0945ec",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "f03457d8-b2a7-4e14-9a73-cab80c5b815d"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"aa224267-f885-4c0c-95af-7bacfcc186d9": {
|
||||||
|
"id": "aa224267-f885-4c0c-95af-7bacfcc186d9",
|
||||||
|
"prev": "793cec2f-8413-484d-aa1e-388fd2b53a45",
|
||||||
|
"regions": {
|
||||||
|
"0d7ac442-5e1d-49a5-91b3-1432d72449d8": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "4d6826fe-2cb8-4468-85ed-a242a1ce7155",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "0d7ac442-5e1d-49a5-91b3-1432d72449d8"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"b52e4d09-5186-44e5-84db-3371c087acde": {
|
||||||
|
"id": "b52e4d09-5186-44e5-84db-3371c087acde",
|
||||||
|
"prev": "134f92d0-6389-4226-af51-1134ae8e8278",
|
||||||
|
"regions": {
|
||||||
|
"7af7d997-80b2-497d-bced-ef8341763439": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "376882ec-d469-4fad-9462-18e4bbea64ca",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "7af7d997-80b2-497d-bced-ef8341763439"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"c5f59b98-a227-4344-9d6d-03abdd01c6aa": {
|
||||||
|
"id": "c5f59b98-a227-4344-9d6d-03abdd01c6aa",
|
||||||
|
"prev": "83e912ff-260a-4391-8a12-331aba098506",
|
||||||
|
"regions": {
|
||||||
|
"7268abff-0540-4c06-aefc-c386410c0953": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "396d478b-34aa-4afa-9898-cdce8222a516",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "7268abff-0540-4c06-aefc-c386410c0953"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"c66f3dfd-2d27-482b-be78-10ba733e826b": {
|
||||||
|
"id": "c66f3dfd-2d27-482b-be78-10ba733e826b",
|
||||||
|
"prev": "8b887c97-83bc-4395-83ac-f6703cbe243d",
|
||||||
|
"regions": {
|
||||||
|
"6cbe8e0e-8645-41a1-8a38-e44acb81be4b": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "7594c7c7-b808-48f7-9500-d7830a07968a",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "6cbe8e0e-8645-41a1-8a38-e44acb81be4b"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"d22045e5-7e3e-452e-bc7b-c6c4a893da8e": {
|
||||||
|
"id": "d22045e5-7e3e-452e-bc7b-c6c4a893da8e",
|
||||||
|
"prev": "ec41f96a-63a3-4825-9295-f4657a440ddb",
|
||||||
|
"regions": {
|
||||||
|
"24e2a3a9-bf65-4dab-927f-0bf6ffbe581d": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "defe921f-8097-44c3-8336-8af6700804a7",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "24e2a3a9-bf65-4dab-927f-0bf6ffbe581d"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"d24c958c-e419-4e4d-aa9c-d228a8ca55e4": {
|
||||||
|
"id": "d24c958c-e419-4e4d-aa9c-d228a8ca55e4",
|
||||||
|
"prev": "11bebe14-d1dc-476d-a31a-5828b9c3adf0",
|
||||||
|
"regions": {
|
||||||
|
"25312144-9faa-4680-bb8e-6307ea71370f": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "bed09a92-9a7a-473b-9464-90e479883a3e",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "25312144-9faa-4680-bb8e-6307ea71370f"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"ec41f96a-63a3-4825-9295-f4657a440ddb": {
|
||||||
|
"id": "ec41f96a-63a3-4825-9295-f4657a440ddb",
|
||||||
|
"prev": "87ab653d-e804-470f-bde9-c67caaa0f354",
|
||||||
|
"regions": {
|
||||||
|
"22e8be98-c254-4d04-b0e4-b9b5ae46eefe": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "bc70f780-c240-4779-96f3-bc5ef9a37d59",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "22e8be98-c254-4d04-b0e4-b9b5ae46eefe"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"fe5a0732-69f5-462a-8af6-851f84a9fdec": {
|
||||||
|
"id": "fe5a0732-69f5-462a-8af6-851f84a9fdec",
|
||||||
|
"prev": "d22045e5-7e3e-452e-bc7b-c6c4a893da8e",
|
||||||
|
"regions": {
|
||||||
|
"671b89f5-fa9c-4bc1-bdeb-6e0a4ce8939b": {
|
||||||
|
"attrs": {
|
||||||
|
"height": 0.8,
|
||||||
|
"width": 0.8,
|
||||||
|
"x": 0.1,
|
||||||
|
"y": 0.1
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"cell": "fd46e2ab-4ab6-4001-b536-1f323525d7d3",
|
||||||
|
"part": "whole"
|
||||||
|
},
|
||||||
|
"id": "671b89f5-fa9c-4bc1-bdeb-6e0a4ce8939b"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"themes": {}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
"nbformat_minor": 2
|
"nbformat_minor": 2
|
||||||
|
|||||||
@@ -39,7 +39,7 @@ n_h1 = args.n_hidden_1
|
|||||||
n_h2 = args.n_hidden_2
|
n_h2 = args.n_hidden_2
|
||||||
n_outputs = 10
|
n_outputs = 10
|
||||||
learning_rate = args.learning_rate
|
learning_rate = args.learning_rate
|
||||||
n_epochs = 20
|
n_epochs = 50
|
||||||
batch_size = args.batch_size
|
batch_size = args.batch_size
|
||||||
|
|
||||||
with tf.name_scope('network'):
|
with tf.name_scope('network'):
|
||||||
|
|||||||
@@ -1,2 +0,0 @@
|
|||||||
/data/
|
|
||||||
/tf-distr-hvd/
|
|
||||||
@@ -102,7 +102,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -113,8 +113,10 @@
|
|||||||
" print('Found existing compute target')\n",
|
" print('Found existing compute target')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -167,7 +169,7 @@
|
|||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"Each workspace is associated with a default datastore. In this tutorial, we will upload the training data to this default datastore."
|
"Each workspace is associated with a default datastore. In this tutorial, we will upload the training data to this default datastore. The below code will upload the contents of the data directory to the path `./data` on the default datastore."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -177,22 +179,8 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"ds = ws.get_default_datastore()\n",
|
"ds = ws.get_default_datastore()\n",
|
||||||
"print(ds.datastore_type, ds.account_name, ds.container_name)"
|
"print(ds.datastore_type, ds.account_name, ds.container_name)\n",
|
||||||
]
|
"\n",
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {},
|
|
||||||
"source": [
|
|
||||||
"Upload the contents of the data directory to the path `./data` on the default datastore."
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": null,
|
|
||||||
"metadata": {},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"ds.upload(src_dir='data', target_path='data', overwrite=True, show_progress=True)"
|
"ds.upload(src_dir='data', target_path='data', overwrite=True, show_progress=True)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -235,8 +223,6 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import os\n",
|
|
||||||
"\n",
|
|
||||||
"project_folder = './tf-distr-hvd'\n",
|
"project_folder = './tf-distr-hvd'\n",
|
||||||
"os.makedirs(project_folder, exist_ok=True)"
|
"os.makedirs(project_folder, exist_ok=True)"
|
||||||
]
|
]
|
||||||
@@ -349,7 +335,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -1 +0,0 @@
|
|||||||
/tf-distr-ps/
|
|
||||||
@@ -102,7 +102,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -113,8 +113,10 @@
|
|||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -207,8 +209,7 @@
|
|||||||
"from azureml.train.dnn import TensorFlow\n",
|
"from azureml.train.dnn import TensorFlow\n",
|
||||||
"\n",
|
"\n",
|
||||||
"script_params={\n",
|
"script_params={\n",
|
||||||
" '--num_gpus': 1,\n",
|
" '--num_gpus': 1\n",
|
||||||
" '--train_steps': 500\n",
|
|
||||||
"}\n",
|
"}\n",
|
||||||
"\n",
|
"\n",
|
||||||
"estimator = TensorFlow(source_directory=project_folder,\n",
|
"estimator = TensorFlow(source_directory=project_folder,\n",
|
||||||
@@ -244,7 +245,7 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"run = experiment.submit(estimator)\n",
|
"run = experiment.submit(estimator)\n",
|
||||||
"print(run)"
|
"print(run.get_details())"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -261,7 +262,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -102,7 +102,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import ComputeTarget, AmlCompute\n",
|
"from azureml.core.compute import ComputeTarget, BatchAiCompute\n",
|
||||||
"from azureml.core.compute_target import ComputeTargetException\n",
|
"from azureml.core.compute_target import ComputeTargetException\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
@@ -113,8 +113,10 @@
|
|||||||
" print('Found existing compute target.')\n",
|
" print('Found existing compute target.')\n",
|
||||||
"except ComputeTargetException:\n",
|
"except ComputeTargetException:\n",
|
||||||
" print('Creating a new compute target...')\n",
|
" print('Creating a new compute target...')\n",
|
||||||
" compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
" compute_config = BatchAiCompute.provisioning_configuration(vm_size='STANDARD_NC6', \n",
|
||||||
" max_nodes=6)\n",
|
" autoscale_enabled=True,\n",
|
||||||
|
" cluster_min_nodes=0, \n",
|
||||||
|
" cluster_max_nodes=4)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
" compute_target = ComputeTarget.create(ws, cluster_name, compute_config)\n",
|
||||||
@@ -281,7 +283,7 @@
|
|||||||
"from azureml.train.estimator import *\n",
|
"from azureml.train.estimator import *\n",
|
||||||
"\n",
|
"\n",
|
||||||
"script_params = {\n",
|
"script_params = {\n",
|
||||||
" '--num_epochs': 20,\n",
|
" '--num_epochs': 50,\n",
|
||||||
" '--data_dir': ds_data.as_mount(),\n",
|
" '--data_dir': ds_data.as_mount(),\n",
|
||||||
" '--output_dir': './outputs'\n",
|
" '--output_dir': './outputs'\n",
|
||||||
"}\n",
|
"}\n",
|
||||||
@@ -339,7 +341,7 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
|||||||
321
training/06.distributed-cntk-with-custom-docker/cntk_mnist.py
Normal file
321
training/06.distributed-cntk-with-custom-docker/cntk_mnist.py
Normal file
@@ -0,0 +1,321 @@
|
|||||||
|
# Copyright (c) Microsoft Corporation. All rights reserved.
|
||||||
|
# Licensed under the MIT License.
|
||||||
|
# Script adapted from:
|
||||||
|
# 1. https://github.com/Microsoft/CNTK/blob/v2.0/Tutorials/CNTK_103A_MNIST_DataLoader.ipynb
|
||||||
|
# 2. https://github.com/Microsoft/CNTK/blob/v2.0/Tutorials/CNTK_103C_MNIST_MultiLayerPerceptron.ipynb
|
||||||
|
# ===================================================================================================
|
||||||
|
"""Train a CNTK multi-layer perceptron on the MNIST dataset."""
|
||||||
|
|
||||||
|
from __future__ import print_function
|
||||||
|
import gzip
|
||||||
|
import numpy as np
|
||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
import struct
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
|
||||||
|
import cntk as C
|
||||||
|
from azureml.core.run import Run
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
run = Run.get_submitted_run()
|
||||||
|
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
|
||||||
|
parser.add_argument('--learning_rate', type=float, default=0.001, help='learning rate')
|
||||||
|
parser.add_argument('--num_hidden_layers', type=int, default=2, help='number of hidden layers')
|
||||||
|
parser.add_argument('--minibatch_size', type=int, default=64, help='minibatchsize')
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
# Functions to load MNIST images and unpack into train and test set.
|
||||||
|
# - loadData reads image data and formats into a 28x28 long array
|
||||||
|
# - loadLabels reads the corresponding labels data, 1 for each image
|
||||||
|
# - load packs the downloaded image and labels data into a combined format to be read later by
|
||||||
|
# CNTK text reader
|
||||||
|
|
||||||
|
|
||||||
|
def loadData(src, cimg):
|
||||||
|
print('Downloading ' + src)
|
||||||
|
gzfname, h = urlretrieve(src, './delete.me')
|
||||||
|
print('Done.')
|
||||||
|
try:
|
||||||
|
with gzip.open(gzfname) as gz:
|
||||||
|
n = struct.unpack('I', gz.read(4))
|
||||||
|
# Read magic number.
|
||||||
|
if n[0] != 0x3080000:
|
||||||
|
raise Exception('Invalid file: unexpected magic number.')
|
||||||
|
# Read number of entries.
|
||||||
|
n = struct.unpack('>I', gz.read(4))[0]
|
||||||
|
if n != cimg:
|
||||||
|
raise Exception('Invalid file: expected {0} entries.'.format(cimg))
|
||||||
|
crow = struct.unpack('>I', gz.read(4))[0]
|
||||||
|
ccol = struct.unpack('>I', gz.read(4))[0]
|
||||||
|
if crow != 28 or ccol != 28:
|
||||||
|
raise Exception('Invalid file: expected 28 rows/cols per image.')
|
||||||
|
# Read data.
|
||||||
|
res = np.fromstring(gz.read(cimg * crow * ccol), dtype=np.uint8)
|
||||||
|
finally:
|
||||||
|
os.remove(gzfname)
|
||||||
|
return res.reshape((cimg, crow * ccol))
|
||||||
|
|
||||||
|
|
||||||
|
def loadLabels(src, cimg):
|
||||||
|
print('Downloading ' + src)
|
||||||
|
gzfname, h = urlretrieve(src, './delete.me')
|
||||||
|
print('Done.')
|
||||||
|
try:
|
||||||
|
with gzip.open(gzfname) as gz:
|
||||||
|
n = struct.unpack('I', gz.read(4))
|
||||||
|
# Read magic number.
|
||||||
|
if n[0] != 0x1080000:
|
||||||
|
raise Exception('Invalid file: unexpected magic number.')
|
||||||
|
# Read number of entries.
|
||||||
|
n = struct.unpack('>I', gz.read(4))
|
||||||
|
if n[0] != cimg:
|
||||||
|
raise Exception('Invalid file: expected {0} rows.'.format(cimg))
|
||||||
|
# Read labels.
|
||||||
|
res = np.fromstring(gz.read(cimg), dtype=np.uint8)
|
||||||
|
finally:
|
||||||
|
os.remove(gzfname)
|
||||||
|
return res.reshape((cimg, 1))
|
||||||
|
|
||||||
|
|
||||||
|
def try_download(dataSrc, labelsSrc, cimg):
|
||||||
|
data = loadData(dataSrc, cimg)
|
||||||
|
labels = loadLabels(labelsSrc, cimg)
|
||||||
|
return np.hstack((data, labels))
|
||||||
|
|
||||||
|
# Save the data files into a format compatible with CNTK text reader
|
||||||
|
|
||||||
|
|
||||||
|
def savetxt(filename, ndarray):
|
||||||
|
dir = os.path.dirname(filename)
|
||||||
|
|
||||||
|
if not os.path.exists(dir):
|
||||||
|
os.makedirs(dir)
|
||||||
|
|
||||||
|
if not os.path.isfile(filename):
|
||||||
|
print("Saving", filename)
|
||||||
|
with open(filename, 'w') as f:
|
||||||
|
labels = list(map(' '.join, np.eye(10, dtype=np.uint).astype(str)))
|
||||||
|
for row in ndarray:
|
||||||
|
row_str = row.astype(str)
|
||||||
|
label_str = labels[row[-1]]
|
||||||
|
feature_str = ' '.join(row_str[:-1])
|
||||||
|
f.write('|labels {} |features {}\n'.format(label_str, feature_str))
|
||||||
|
else:
|
||||||
|
print("File already exists", filename)
|
||||||
|
|
||||||
|
# Read a CTF formatted text (as mentioned above) using the CTF deserializer from a file
|
||||||
|
|
||||||
|
|
||||||
|
def create_reader(path, is_training, input_dim, num_label_classes):
|
||||||
|
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
|
||||||
|
labels=C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),
|
||||||
|
features=C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)
|
||||||
|
)), randomize=is_training, max_sweeps=C.io.INFINITELY_REPEAT if is_training else 1)
|
||||||
|
|
||||||
|
# Defines a utility that prints the training progress
|
||||||
|
|
||||||
|
|
||||||
|
def print_training_progress(trainer, mb, frequency, verbose=1):
|
||||||
|
training_loss = "NA"
|
||||||
|
eval_error = "NA"
|
||||||
|
|
||||||
|
if mb % frequency == 0:
|
||||||
|
training_loss = trainer.previous_minibatch_loss_average
|
||||||
|
eval_error = trainer.previous_minibatch_evaluation_average
|
||||||
|
if verbose:
|
||||||
|
print("Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%".format(mb, training_loss, eval_error * 100))
|
||||||
|
|
||||||
|
return mb, training_loss, eval_error
|
||||||
|
|
||||||
|
# Create the network architecture
|
||||||
|
|
||||||
|
|
||||||
|
def create_model(features):
|
||||||
|
with C.layers.default_options(init=C.layers.glorot_uniform(), activation=C.ops.relu):
|
||||||
|
h = features
|
||||||
|
for _ in range(num_hidden_layers):
|
||||||
|
h = C.layers.Dense(hidden_layers_dim)(h)
|
||||||
|
r = C.layers.Dense(num_output_classes, activation=None)(h)
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
run = Run.get_submitted_run()
|
||||||
|
|
||||||
|
try:
|
||||||
|
from urllib.request import urlretrieve
|
||||||
|
except ImportError:
|
||||||
|
from urllib import urlretrieve
|
||||||
|
|
||||||
|
# Select the right target device when this script is being used:
|
||||||
|
if 'TEST_DEVICE' in os.environ:
|
||||||
|
if os.environ['TEST_DEVICE'] == 'cpu':
|
||||||
|
C.device.try_set_default_device(C.device.cpu())
|
||||||
|
else:
|
||||||
|
C.device.try_set_default_device(C.device.gpu(0))
|
||||||
|
|
||||||
|
# URLs for the train image and labels data
|
||||||
|
url_train_image = 'http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz'
|
||||||
|
url_train_labels = 'http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz'
|
||||||
|
num_train_samples = 60000
|
||||||
|
|
||||||
|
print("Downloading train data")
|
||||||
|
train = try_download(url_train_image, url_train_labels, num_train_samples)
|
||||||
|
|
||||||
|
url_test_image = 'http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz'
|
||||||
|
url_test_labels = 'http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz'
|
||||||
|
num_test_samples = 10000
|
||||||
|
|
||||||
|
print("Downloading test data")
|
||||||
|
test = try_download(url_test_image, url_test_labels, num_test_samples)
|
||||||
|
|
||||||
|
# Save the train and test files (prefer our default path for the data
|
||||||
|
rank = os.environ.get("OMPI_COMM_WORLD_RANK")
|
||||||
|
data_dir = os.path.join("outputs", "MNIST")
|
||||||
|
sentinel_path = os.path.join(data_dir, "complete.txt")
|
||||||
|
if rank == '0':
|
||||||
|
print('Writing train text file...')
|
||||||
|
savetxt(os.path.join(data_dir, "Train-28x28_cntk_text.txt"), train)
|
||||||
|
|
||||||
|
print('Writing test text file...')
|
||||||
|
savetxt(os.path.join(data_dir, "Test-28x28_cntk_text.txt"), test)
|
||||||
|
with open(sentinel_path, 'w+') as f:
|
||||||
|
f.write("download complete")
|
||||||
|
|
||||||
|
print('Done with downloading data.')
|
||||||
|
else:
|
||||||
|
while not os.path.exists(sentinel_path):
|
||||||
|
time.sleep(0.01)
|
||||||
|
|
||||||
|
# Ensure we always get the same amount of randomness
|
||||||
|
np.random.seed(0)
|
||||||
|
|
||||||
|
# Define the data dimensions
|
||||||
|
input_dim = 784
|
||||||
|
num_output_classes = 10
|
||||||
|
|
||||||
|
# Ensure the training and test data is generated and available for this tutorial.
|
||||||
|
# We search in two locations in the toolkit for the cached MNIST data set.
|
||||||
|
data_found = False
|
||||||
|
for data_dir in [os.path.join("..", "Examples", "Image", "DataSets", "MNIST"),
|
||||||
|
os.path.join("data_" + str(rank), "MNIST"),
|
||||||
|
os.path.join("outputs", "MNIST")]:
|
||||||
|
train_file = os.path.join(data_dir, "Train-28x28_cntk_text.txt")
|
||||||
|
test_file = os.path.join(data_dir, "Test-28x28_cntk_text.txt")
|
||||||
|
if os.path.isfile(train_file) and os.path.isfile(test_file):
|
||||||
|
data_found = True
|
||||||
|
break
|
||||||
|
if not data_found:
|
||||||
|
raise ValueError("Please generate the data by completing CNTK 103 Part A")
|
||||||
|
print("Data directory is {0}".format(data_dir))
|
||||||
|
|
||||||
|
num_hidden_layers = args.num_hidden_layers
|
||||||
|
hidden_layers_dim = 400
|
||||||
|
|
||||||
|
input = C.input_variable(input_dim)
|
||||||
|
label = C.input_variable(num_output_classes)
|
||||||
|
|
||||||
|
z = create_model(input)
|
||||||
|
# Scale the input to 0-1 range by dividing each pixel by 255.
|
||||||
|
z = create_model(input / 255.0)
|
||||||
|
|
||||||
|
loss = C.cross_entropy_with_softmax(z, label)
|
||||||
|
label_error = C.classification_error(z, label)
|
||||||
|
|
||||||
|
# Instantiate the trainer object to drive the model training
|
||||||
|
learning_rate = args.learning_rate
|
||||||
|
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
|
||||||
|
learner = C.sgd(z.parameters, lr_schedule)
|
||||||
|
trainer = C.Trainer(z, (loss, label_error), [learner])
|
||||||
|
|
||||||
|
# Initialize the parameters for the trainer
|
||||||
|
minibatch_size = args.minibatch_size
|
||||||
|
num_samples_per_sweep = 60000
|
||||||
|
num_sweeps_to_train_with = 10
|
||||||
|
num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size
|
||||||
|
|
||||||
|
# Create the reader to training data set
|
||||||
|
reader_train = create_reader(train_file, True, input_dim, num_output_classes)
|
||||||
|
|
||||||
|
# Map the data streams to the input and labels.
|
||||||
|
input_map = {
|
||||||
|
label: reader_train.streams.labels,
|
||||||
|
input: reader_train.streams.features
|
||||||
|
}
|
||||||
|
|
||||||
|
# Run the trainer on and perform model training
|
||||||
|
training_progress_output_freq = 500
|
||||||
|
|
||||||
|
errors = []
|
||||||
|
losses = []
|
||||||
|
for i in range(0, int(num_minibatches_to_train)):
|
||||||
|
# Read a mini batch from the training data file
|
||||||
|
data = reader_train.next_minibatch(minibatch_size, input_map=input_map)
|
||||||
|
|
||||||
|
trainer.train_minibatch(data)
|
||||||
|
batchsize, loss, error = print_training_progress(trainer, i, training_progress_output_freq, verbose=1)
|
||||||
|
if (error != 'NA') and (loss != 'NA'):
|
||||||
|
errors.append(float(error))
|
||||||
|
losses.append(float(loss))
|
||||||
|
|
||||||
|
# log the losses
|
||||||
|
if rank == '0':
|
||||||
|
run.log_list("Loss", losses)
|
||||||
|
run.log_list("Error", errors)
|
||||||
|
|
||||||
|
# Read the training data
|
||||||
|
reader_test = create_reader(test_file, False, input_dim, num_output_classes)
|
||||||
|
|
||||||
|
test_input_map = {
|
||||||
|
label: reader_test.streams.labels,
|
||||||
|
input: reader_test.streams.features,
|
||||||
|
}
|
||||||
|
|
||||||
|
# Test data for trained model
|
||||||
|
test_minibatch_size = 512
|
||||||
|
num_samples = 10000
|
||||||
|
num_minibatches_to_test = num_samples // test_minibatch_size
|
||||||
|
test_result = 0.0
|
||||||
|
|
||||||
|
for i in range(num_minibatches_to_test):
|
||||||
|
# We are loading test data in batches specified by test_minibatch_size
|
||||||
|
# Each data point in the minibatch is a MNIST digit image of 784 dimensions
|
||||||
|
# with one pixel per dimension that we will encode / decode with the
|
||||||
|
# trained model.
|
||||||
|
data = reader_test.next_minibatch(test_minibatch_size,
|
||||||
|
input_map=test_input_map)
|
||||||
|
|
||||||
|
eval_error = trainer.test_minibatch(data)
|
||||||
|
test_result = test_result + eval_error
|
||||||
|
|
||||||
|
# Average of evaluation errors of all test minibatches
|
||||||
|
print("Average test error: {0:.2f}%".format((test_result * 100) / num_minibatches_to_test))
|
||||||
|
|
||||||
|
out = C.softmax(z)
|
||||||
|
|
||||||
|
# Read the data for evaluation
|
||||||
|
reader_eval = create_reader(test_file, False, input_dim, num_output_classes)
|
||||||
|
|
||||||
|
eval_minibatch_size = 25
|
||||||
|
eval_input_map = {input: reader_eval.streams.features}
|
||||||
|
|
||||||
|
data = reader_test.next_minibatch(eval_minibatch_size, input_map=test_input_map)
|
||||||
|
|
||||||
|
img_label = data[label].asarray()
|
||||||
|
img_data = data[input].asarray()
|
||||||
|
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
|
||||||
|
|
||||||
|
# Find the index with the maximum value for both predicted as well as the ground truth
|
||||||
|
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
|
||||||
|
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
|
||||||
|
|
||||||
|
print("Label :", gtlabel[:25])
|
||||||
|
print("Predicted:", pred)
|
||||||
|
|
||||||
|
# save model to outputs folder
|
||||||
|
z.save('outputs/cntk.model')
|
||||||
@@ -176,13 +176,13 @@
|
|||||||
"from azureml.core.script_run_config import ScriptRunConfig\n",
|
"from azureml.core.script_run_config import ScriptRunConfig\n",
|
||||||
"import tensorflow as tf\n",
|
"import tensorflow as tf\n",
|
||||||
"\n",
|
"\n",
|
||||||
"logs_dir = os.path.join(os.curdir, \"logs\")\n",
|
"logs_dir = os.curdir + os.sep + \"logs\"\n",
|
||||||
"data_dir = os.path.abspath(os.path.join(os.curdir, \"mnist_data\"))\n",
|
"tensorflow_logs_dir = os.path.join(logs_dir, \"tensorflow\")\n",
|
||||||
"\n",
|
"\n",
|
||||||
"if not path.exists(data_dir):\n",
|
"if not path.exists(tensorflow_logs_dir):\n",
|
||||||
" makedirs(data_dir)\n",
|
" makedirs(tensorflow_logs_dir)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"os.environ[\"TEST_TMPDIR\"] = data_dir\n",
|
"os.environ[\"TEST_TMPDIR\"] = logs_dir\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# Writing logs to ./logs results in their being uploaded to Artifact Service,\n",
|
"# Writing logs to ./logs results in their being uploaded to Artifact Service,\n",
|
||||||
"# and thus, made accessible to our Tensorboard instance.\n",
|
"# and thus, made accessible to our Tensorboard instance.\n",
|
||||||
@@ -191,15 +191,15 @@
|
|||||||
"# Create an experiment\n",
|
"# Create an experiment\n",
|
||||||
"exp = Experiment(ws, experiment_name)\n",
|
"exp = Experiment(ws, experiment_name)\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# If you would like the run to go for longer, add --max_steps 5000 to the arguments list:\n",
|
|
||||||
"# arguments_list += [\"--max_steps\", \"5000\"]\n",
|
|
||||||
"\n",
|
|
||||||
"script = ScriptRunConfig(exp_dir,\n",
|
"script = ScriptRunConfig(exp_dir,\n",
|
||||||
" script=\"mnist_with_summaries.py\",\n",
|
" script=\"mnist_with_summaries.py\",\n",
|
||||||
" run_config=run_config,\n",
|
" run_config=run_config)\n",
|
||||||
" arguments=arguments_list)\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"run = exp.submit(script)\n",
|
"# If you would like the run to go for longer, add --max_steps 5000 to the arguments list:\n",
|
||||||
|
"# arguments_list += [\"--max_steps\", \"5000\"]\n",
|
||||||
|
"kwargs = {}\n",
|
||||||
|
"kwargs['arguments_list'] = arguments_list\n",
|
||||||
|
"run = exp.submit(script, kwargs)\n",
|
||||||
"# You can also wait for the run to complete\n",
|
"# You can also wait for the run to complete\n",
|
||||||
"# run.wait_for_completion(show_output=True)\n",
|
"# run.wait_for_completion(show_output=True)\n",
|
||||||
"runs.append(run)"
|
"runs.append(run)"
|
||||||
@@ -367,21 +367,23 @@
|
|||||||
"metadata": {},
|
"metadata": {},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import AmlCompute\n",
|
"from azureml.core.compute import BatchAiCompute\n",
|
||||||
"\n",
|
"\n",
|
||||||
"clust_name = \"cpucluster\"\n",
|
"clust_name = ws.name + \"cpu\"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"try:\n",
|
"try:\n",
|
||||||
" # If you already have a cluster named this, we don't need to make a new one.\n",
|
" # If you already have a cluster named this, we don't need to make a new one.\n",
|
||||||
" cts = ws.compute_targets \n",
|
" cts = ws.compute_targets() \n",
|
||||||
" compute_target = cts[clust_name]\n",
|
" compute_target = cts[clust_name]\n",
|
||||||
" assert compute_target.type == 'BatchAI'\n",
|
" assert compute_target.type == 'BatchAI'\n",
|
||||||
"except:\n",
|
"except:\n",
|
||||||
" # Let's make a new one here.\n",
|
" # Let's make a new one here.\n",
|
||||||
" provisioning_config = AmlCompute.provisioning_configuration(max_nodes=6, \n",
|
" provisioning_config = BatchAiCompute.provisioning_configuration(cluster_max_nodes=2, \n",
|
||||||
" vm_size='STANDARD_D2_V2')\n",
|
" autoscale_enabled=True, \n",
|
||||||
|
" cluster_min_nodes=1,\n",
|
||||||
|
" vm_size='Standard_D11_V2')\n",
|
||||||
" \n",
|
" \n",
|
||||||
" compute_target = AmlCompute.create(ws, clust_name, provisioning_config)\n",
|
" compute_target = BatchAiCompute.create(ws, clust_name, provisioning_config)\n",
|
||||||
" compute_target.wait_for_completion(show_output=True, min_node_count=1, timeout_in_minutes=20)\n",
|
" compute_target.wait_for_completion(show_output=True, min_node_count=1, timeout_in_minutes=20)\n",
|
||||||
"print(compute_target.name)\n",
|
"print(compute_target.name)\n",
|
||||||
" # For a more detailed view of current BatchAI cluster status, use the 'status' property \n",
|
" # For a more detailed view of current BatchAI cluster status, use the 'status' property \n",
|
||||||
|
|||||||
52
training/readme.md
Normal file
52
training/readme.md
Normal file
@@ -0,0 +1,52 @@
|
|||||||
|
# Training ML models with Azure ML SDK
|
||||||
|
These notebook tutorials cover the various scenarios for training machine learning and deep learning models with Azure Machine Learning.
|
||||||
|
|
||||||
|
## Sample notebooks
|
||||||
|
- [01.train-hyperparameter-tune-deploy-with-pytorch](./01.train-hyperparameter-tune-deploy-with-pytorch/01.train-hyperparameter-tune-deploy-with-pytorch.ipynb)
|
||||||
|
Train, hyperparameter tune, and deploy a PyTorch image classification model that distinguishes bees vs. ants using transfer learning. Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Upload training data using `Datastore`
|
||||||
|
- Run a single-node `PyTorch` training job
|
||||||
|
- Hyperparameter tune model with HyperDrive
|
||||||
|
- Find and register the best model
|
||||||
|
- Deploy model to ACI
|
||||||
|
- [02.distributed-pytorch-with-horovod](./02.distributed-pytorch-with-horovod/02.distributed-pytorch-with-horovod.ipynb)
|
||||||
|
Train a PyTorch model on the MNIST dataset using distributed training with Horovod. Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Run a two-node distributed `PyTorch` training job using Horovod
|
||||||
|
- [03.train-hyperparameter-tun-deploy-with-tensorflow](./03.train-hyperparameter-tune-deploy-with-tensorflow/03.train-hyperparameter-tune-deploy-with-tensorflow.ipynb)
|
||||||
|
Train, hyperparameter tune, and deploy a TensorFlow model on the MNIST dataset. Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Upload training data using `Datastore`
|
||||||
|
- Run a single-node `TensorFlow` training job
|
||||||
|
- Leverage features of the `Run` object
|
||||||
|
- Download the trained model
|
||||||
|
- Hyperparameter tune model with HyperDrive
|
||||||
|
- Find and register the best model
|
||||||
|
- Deploy model to ACI
|
||||||
|
- [04.distributed-tensorflow-with-horovod](./04.distributed-tensorflow-with-horovod/04.distributed-tensorflow-with-horovod.ipynb)
|
||||||
|
Train a TensorFlow word2vec model using distributed training with Horovod. Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Upload training data using `Datastore`
|
||||||
|
- Run a two-node distributed `TensorFlow` training job using Horovod
|
||||||
|
- [05.distributed-tensorflow-with-parameter-server](./05.distributed-tensorflow-with-parameter-server/05.distributed-tensorflow-with-parameter-server.ipynb)
|
||||||
|
Train a TensorFlow model on the MNIST dataset using native distributed TensorFlow (parameter server). Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Run a two workers, one parameter server distributed `TensorFlow` training job
|
||||||
|
- [06.distributed-cntk-with-custom-docker](./06.distributed-cntk-with-custom-docker/06.distributed-cntk-with-custom-docker.ipynb)
|
||||||
|
Train a CNTK model on the MNIST dataset using the Azure ML base `Estimator` with custom Docker image and distributed training. Azure ML concepts covered:
|
||||||
|
- Create a remote compute target (Batch AI cluster)
|
||||||
|
- Upload training data using `Datastore`
|
||||||
|
- Run a base `Estimator` training job using a custom Docker image from Docker Hub
|
||||||
|
- Distributed CNTK two-node training job via MPI using base `Estimator`
|
||||||
|
|
||||||
|
- [07.tensorboard](./07.tensorboard/07.tensorboard.ipynb)
|
||||||
|
Train a TensorFlow MNIST model locally, on a DSVM, and on Batch AI and view the logs live on TensorBoard. Azure ML concepts covered:
|
||||||
|
- Run the training job locally with Azure ML and run TensorBoard locally. Start (and stop) an Azure ML `TensorBoard` object to stream and view the logs
|
||||||
|
- Run the training job on a remote DSVM and stream the logs to TensorBoard
|
||||||
|
- Run the training job on a remote Batch AI cluster and stream the logs to TensorBoard
|
||||||
|
- Start a `Tensorboard` instance that displays the logs from all three above runs in one
|
||||||
|
- [08.export-run-history-to-tensorboard](./08.export-run-history-to-tensorboard/08.export-run-history-to-tensorboard.ipynb)
|
||||||
|
- Start an Azure ML `Experiment` and log metrics to `Run` history
|
||||||
|
- Export the `Run` history logs to TensorBoard logs
|
||||||
|
- View the logs in TensorBoard
|
||||||
@@ -58,13 +58,14 @@
|
|||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": null,
|
"execution_count": null,
|
||||||
"metadata": {
|
"metadata": {
|
||||||
|
"name": "import",
|
||||||
"tags": [
|
"tags": [
|
||||||
"check version"
|
"check version"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"%matplotlib notebook\n",
|
"%matplotlib inline\n",
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
"import matplotlib\n",
|
"import matplotlib\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
@@ -131,9 +132,9 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"### Create remote compute target\n",
|
"### Create remote compute target\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Azure Machine Learning Managed Compute(AmlCompute) is a managed service that enables data scientists to train machine learning models on clusters of Azure virtual machines, including VMs with GPU support. In this tutorial, you create AmlCompute as your training environment. This code creates compute for you if it does not already exist in your workspace. \n",
|
"Azure Azure ML Managed Compute is a managed service that enables data scientists to train machine learning models on clusters of Azure virtual machines, including VMs with GPU support. In this tutorial, you create an Azure Managed Compute cluster as your training environment. This code creates a cluster for you if it does not already exist in your workspace. \n",
|
||||||
"\n",
|
"\n",
|
||||||
" **Creation of the compute takes approximately 5 minutes.** If the compute is already in the workspace this code uses it and skips the creation process."
|
" **Creation of the cluster takes approximately 5 minutes.** If the cluster is already in the workspace this code uses it and skips the creation process."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -147,31 +148,32 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.core.compute import AmlCompute\n",
|
"from azureml.core.compute import BatchAiCompute\n",
|
||||||
"from azureml.core.compute import ComputeTarget\n",
|
"from azureml.core.compute import ComputeTarget\n",
|
||||||
"import os\n",
|
"import os\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# choose a name for your cluster\n",
|
"# choose a name for your cluster\n",
|
||||||
"compute_name = os.environ.get(\"BATCHAI_CLUSTER_NAME\", \"cpucluster\")\n",
|
"batchai_cluster_name = os.environ.get(\"BATCHAI_CLUSTER_NAME\", ws.name + \"gpu\")\n",
|
||||||
"compute_min_nodes = os.environ.get(\"BATCHAI_CLUSTER_MIN_NODES\", 0)\n",
|
"cluster_min_nodes = os.environ.get(\"BATCHAI_CLUSTER_MIN_NODES\", 1)\n",
|
||||||
"compute_max_nodes = os.environ.get(\"BATCHAI_CLUSTER_MAX_NODES\", 4)\n",
|
"cluster_max_nodes = os.environ.get(\"BATCHAI_CLUSTER_MAX_NODES\", 3)\n",
|
||||||
"\n",
|
"vm_size = os.environ.get(\"BATCHAI_CLUSTER_SKU\", \"STANDARD_NC6\")\n",
|
||||||
"# This example uses CPU VM. For using GPU VM, set SKU to STANDARD_NC6\n",
|
"autoscale_enabled = os.environ.get(\"BATCHAI_CLUSTER_AUTOSCALE_ENABLED\", True)\n",
|
||||||
"vm_size = os.environ.get(\"BATCHAI_CLUSTER_SKU\", \"STANDARD_D2_V2\")\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"\n",
|
"\n",
|
||||||
"if compute_name in ws.compute_targets:\n",
|
"if batchai_cluster_name in ws.compute_targets():\n",
|
||||||
" compute_target = ws.compute_targets[compute_name]\n",
|
" compute_target = ws.compute_targets()[batchai_cluster_name]\n",
|
||||||
" if compute_target and type(compute_target) is AmlCompute:\n",
|
" if compute_target and type(compute_target) is BatchAiCompute:\n",
|
||||||
" print('found compute target. just use it. ' + compute_name)\n",
|
" print('found compute target. just use it. ' + batchai_cluster_name)\n",
|
||||||
"else:\n",
|
"else:\n",
|
||||||
" print('creating a new compute target...')\n",
|
" print('creating a new compute target...')\n",
|
||||||
" provisioning_config = AmlCompute.provisioning_configuration(vm_size = vm_size,\n",
|
" provisioning_config = BatchAiCompute.provisioning_configuration(vm_size = vm_size, # NC6 is GPU-enabled\n",
|
||||||
" min_nodes = compute_min_nodes, \n",
|
" vm_priority = 'lowpriority', # optional\n",
|
||||||
" max_nodes = compute_max_nodes)\n",
|
" autoscale_enabled = autoscale_enabled,\n",
|
||||||
|
" cluster_min_nodes = cluster_min_nodes, \n",
|
||||||
|
" cluster_max_nodes = cluster_max_nodes)\n",
|
||||||
"\n",
|
"\n",
|
||||||
" # create the cluster\n",
|
" # create the cluster\n",
|
||||||
" compute_target = ComputeTarget.create(ws, compute_name, provisioning_config)\n",
|
" compute_target = ComputeTarget.create(ws, batchai_cluster_name, provisioning_config)\n",
|
||||||
" \n",
|
" \n",
|
||||||
" # can poll for a minimum number of nodes and for a specific timeout. \n",
|
" # can poll for a minimum number of nodes and for a specific timeout. \n",
|
||||||
" # if no min node count is provided it will use the scale settings for the cluster\n",
|
" # if no min node count is provided it will use the scale settings for the cluster\n",
|
||||||
@@ -200,6 +202,13 @@
|
|||||||
"Download the MNIST dataset and save the files into a `data` directory locally. Images and labels for both training and testing are downloaded."
|
"Download the MNIST dataset and save the files into a `data` directory locally. Images and labels for both training and testing are downloaded."
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": null,
|
"execution_count": null,
|
||||||
@@ -570,7 +579,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(run).show()"
|
"RunDetails(run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -709,7 +718,7 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.6.2"
|
"version": "3.6.6"
|
||||||
},
|
},
|
||||||
"msauthor": "sgilley"
|
"msauthor": "sgilley"
|
||||||
},
|
},
|
||||||
|
|||||||
@@ -97,7 +97,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"%matplotlib notebook\n",
|
"%matplotlib inline\n",
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
"import matplotlib\n",
|
"import matplotlib\n",
|
||||||
"import matplotlib.pyplot as plt\n",
|
"import matplotlib.pyplot as plt\n",
|
||||||
@@ -134,7 +134,7 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"ws = Workspace.from_config()\n",
|
"ws = Workspace.from_config()\n",
|
||||||
"model=Model(ws, 'sklearn_mnist')\n",
|
"model=Model(ws, 'sklearn_mnist')\n",
|
||||||
"model.download(target_dir='.', exists_ok=True)\n",
|
"model.download(target_dir = '.')\n",
|
||||||
"import os \n",
|
"import os \n",
|
||||||
"# verify the downloaded model file\n",
|
"# verify the downloaded model file\n",
|
||||||
"os.stat('./sklearn_mnist_model.pkl')"
|
"os.stat('./sklearn_mnist_model.pkl')"
|
||||||
@@ -296,8 +296,7 @@
|
|||||||
" data = np.array(json.loads(raw_data)['data'])\n",
|
" data = np.array(json.loads(raw_data)['data'])\n",
|
||||||
" # make prediction\n",
|
" # make prediction\n",
|
||||||
" y_hat = model.predict(data)\n",
|
" y_hat = model.predict(data)\n",
|
||||||
" # you can return any data type as long as it is JSON-serializable\n",
|
" return json.dumps(y_hat.tolist())"
|
||||||
" return y_hat.tolist()"
|
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -481,7 +480,7 @@
|
|||||||
"test_samples = bytes(test_samples, encoding = 'utf8')\n",
|
"test_samples = bytes(test_samples, encoding = 'utf8')\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# predict using the deployed model\n",
|
"# predict using the deployed model\n",
|
||||||
"result = service.run(input_data=test_samples)\n",
|
"result = json.loads(service.run(input_data=test_samples))\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# compare actual value vs. the predicted values:\n",
|
"# compare actual value vs. the predicted values:\n",
|
||||||
"i = 0\n",
|
"i = 0\n",
|
||||||
|
|||||||
@@ -264,7 +264,7 @@
|
|||||||
},
|
},
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"from azureml.widgets import RunDetails\n",
|
"from azureml.train.widgets import RunDetails\n",
|
||||||
"RunDetails(local_run).show()"
|
"RunDetails(local_run).show()"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
@@ -393,7 +393,7 @@
|
|||||||
"> * Review training results\n",
|
"> * Review training results\n",
|
||||||
"> * Register the best model\n",
|
"> * Register the best model\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Learn more about [how to configure settings for automatic training](https://aka.ms/aml-how-to-configure-auto) or [how to use automatic training on a remote resource](https://aka.ms/aml-how-to-auto-remote)."
|
"Learn more about [how to configure settings for automatic training](https://aka.ms/aml-how-configure-auto) or [how to use automatic training on a remote resource](https://aka.ms/aml-how-to-auto-remote)."
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
|
|||||||
Reference in New Issue
Block a user